人工智能实战_第三次作业_陈泽寅
第三次作业:使用minibatch的方式进行梯度下降
一、简要概述
| 项目 | 内容 |
|---|---|
| 课程 | 人工智能实战2019 |
| 作业要求 | 作业要求 |
| 我在这个课程的目标是 | 了解人工智能理论,提升coding能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 了解单层神经工作原理,掌握几种梯度下降法的优缺点,自己实现简单算法 |
二、单层神经网络原理以及权值更新依据
-
单变量随机梯度下降 SDG(Stochastic Grident Descent)
-
正向计算过程:
\[Z^{n \times 1}=W^{n \times f} \cdot X^{f \times 1} + B^{n \times 1}
\]
\[A^{n \times 1}=a(Z)
\]
- 反向计算过程:
\[\Delta Z^{n \times 1} = J'(W,B) = A^{n \times 1} - Y^{1 \times 1}
\]
\[W^{n \times f} = W^{n \times f} - \eta \cdot (\Delta Z^{n \times 1} \cdot X_T^{1 \times f})\]
\[B^{n \times 1} = B^{n \times 1} - \eta \cdot \Delta Z^{n \times 1}\]
* 其中:
\[f=特征值数,m=样本数,n=神经元数,\eta=步长 \\
A=预测值,Y=标签值,X=输入值,X_T=X的转置\]
三、作业实现步骤
- 模拟PDF上的步骤,仿写出相应的单层神经网络模型算法。
- 采用SGD梯度下降算法更新每次的权值
- 统计每一个Epoch权值更新完之后的代价值。
- 更改batch_size的值为5,10,15,观察在不同的batch_size下函数代价函数的收敛速度与效果。
四、代码
#-*-coding:utf-8-*-
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
x_data_name = "TemperatureControlXData.dat" #read the data from x
y_data_name = "TemperatureControlYData.dat" # 两个文件名保存着数据文件的路径
#下面这个类保存着每个线性模型的参数
class CData(object):
def __init__(self, loss, w, b, epoch, iteration):
self.loss = loss
self.w = w
self.b = b
self.epoch = epoch
self.iteration = iteration
# 下面这个函数将X,Y数据从文件中读出,并且通过reshape函数将其规整为一行的结果
def ReadData():
Xfile = Path(x_data_name)
Yfile = Path(y_data_name)
if Xfile.exists() & Yfile.exists():
X = np.load(Xfile)
Y = np.load(Yfile)
return X.reshape(1, -1), Y.reshape(1, -1) #将这两种数据全部转化为一个列
else:
return None, None
# 前向传播过程 z = w*x + b
# 得到相应的z
def Fowrad(w,b,x):
z = np.dot(w,x)+b
return z;
# 反向求导过程,求出w和b的值应该变化的量
def BackPropagation(x,y,z):
m = np.shape(x)[1] # 代表样本的数量
# delta z = z - y
deltaZ = z - y
# delta b = sum(delta z)
deltaB = deltaZ.sum(axis=1, keepdims=True) / m
# delta w = (delta z) * (x')
deltaW = np.dot(deltaZ, x.T) / m
return deltaW,deltaB
# 每次反向求导后跟新w和b的值
def UpdateWeights(w, b, deltaW, deltaB, eta):
w = w - eta * deltaW
b = b - eta * deltaB
return w, b
# 示例中给出的初始化w和b的方法,根据输入和输出的个数确定不同
# 大小的矩阵
def SetParam(num_input,num_output, flag):
if flag == 0:
# zero
W = np.zeros((num_output, num_input))
elif flag == 1:
# normalize
W = np.random.normal(size=(num_output, num_input))
elif flag == 2:
# xavier
W = np.random.uniform(
-np.sqrt(6 / (num_input + num_output)),
np.sqrt(6 / (num_input + num_output)),
size=(num_output, num_input))
B = np.zeros((num_output, 1))
return W, B
# 这个函数计算在每一次迭代更新完权值之后的误差
def GetLoss(w,b,x,y):
m = x.shape[1]
z = np.dot(w, x) + b
LOSS = (z - y) ** 2
loss = LOSS.sum() / m / 2
return loss
# 在每次迭代的时候从x,y中取出合适大小的batch来进行训练
def GetBatchSamples(X, Y, batch_size, iteration):
num_feature = X.shape[0]
start = iteration * batch_size
end = start + batch_size
batch_x = X[0:num_feature, start:end].reshape(num_feature, batch_size)
batch_y = Y[0, start:end].reshape(1, batch_size)
return batch_x, batch_y
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X)//batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
if __name__ == '__main__':
# 首先设置学习率 eta, batch_size, epoch的个数
eta = 0.1
size = {5,10,15}
epochMax = 50
# x,y就是我们的训练数据
x,y = ReadData()
print np.shape(x),np.shape(y)
plt.figure()
for batch_size in size:
loss = []
# iterMax是我们每个epoch迭代的次数,epochMax是我们循环的次数
iterMax = np.shape(x)[1] / batch_size
w, b = SetParam(1, 1, 2)
for epoch in range(epochMax):
for x_batch, y_batch in shuffle_batch(X, y, batch_size):
# 获得每一个iter的batch数据
# 获得前向传播后的z值
z_batch = Fowrad(w,b,x_batch)
# 反向传播
deltaW,deltaB = BackPropagation(x_batch,y_batch,z_batch)
# 更新w和b的值
w,b = UpdateWeights(w,b,deltaW,deltaB,eta)
# 每个epoch后获取新的参数得出的loss
c = GetLoss(w,b,x,y)
print("Epoch = %d , w = %f,b = %f ,loss = %f"%(epoch,w,b,c))
loss.append(c)
axisX = np.arange(5,epochMax,1)
plt.plot(axisX,loss)
plt.legend(['batch_size : 5','batch_size : 10','batch_size : 15'],loc ='upper right')
plt.show()
plt.figure()
min = np.min(x,1)
max = np.max(x,1)
lineX = np.arange(min,max,0.01)
lineX = lineX.reshape(1,-1)
lineY = lineX * w + b
print np.shape(lineY)
plt.scatter(x,y,s=1)
plt.plot(lineX[0,:],lineY[0,:],'r')
plt.show()
五、实验结果
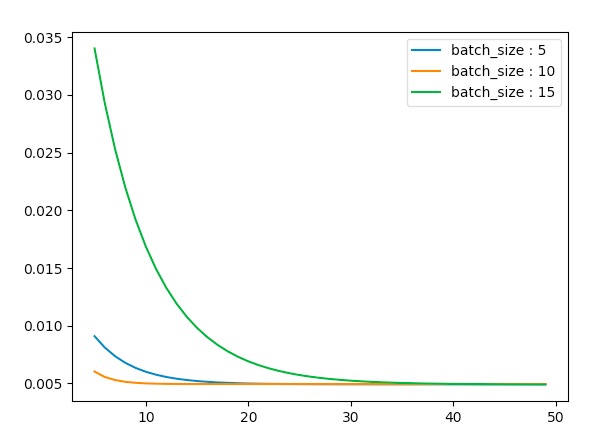
-
以上是不同batch_size下的代价函数随着epoch的增加而变化的情况可以看当batchsize取10的时候下降最快
-
当我们改变其学习率为0.01,0.1,0.2,0.5时我们看其变化
-
eta = 0.01时
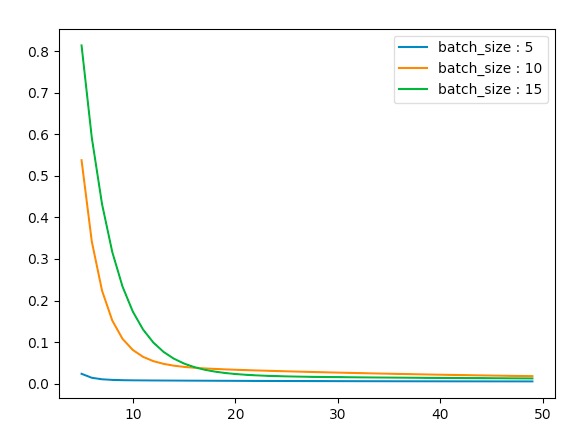
-
eta = 0.1时
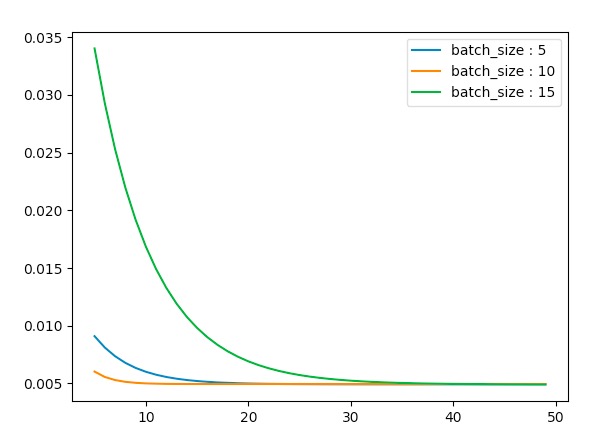
-
eta = 0.2时
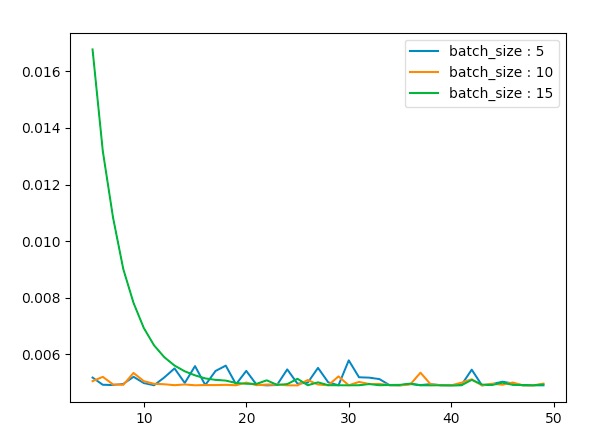
-
eta = 0.5时

-
-
我们看到随着学习率的变大,SGD的抖动也在逐渐增加。
-
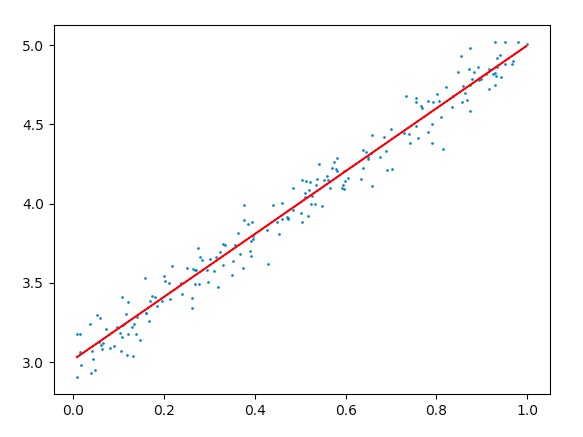
这是在最后取得的权值下,生成的拟合曲线。
代价函数变化:
batch_size = 5
Epoch = 0 , w = 1.263874,b = 3.099159 ,loss = 0.061878
Epoch = 1 , w = 1.454535,b = 3.274156 ,loss = 0.017243
Epoch = 2 , w = 1.529773,b = 3.253623 ,loss = 0.014271
Epoch = 3 , w = 1.589247,b = 3.223812 ,loss = 0.012070
Epoch = 4 , w = 1.640776,b = 3.196955 ,loss = 0.010385
Epoch = 5 , w = 1.685762,b = 3.173438 ,loss = 0.009097
Epoch = 6 , w = 1.725059,b = 3.152890 ,loss = 0.008113
Epoch = 7 , w = 1.759388,b = 3.134939 ,loss = 0.007362
Epoch = 8 , w = 1.789379,b = 3.119256 ,loss = 0.006788
Epoch = 9 , w = 1.815578,b = 3.105557 ,loss = 0.006349
Epoch = 10 , w = 1.838466,b = 3.093589 ,loss = 0.006014
Epoch = 11 , w = 1.858460,b = 3.083133 ,loss = 0.005758
Epoch = 12 , w = 1.875927,b = 3.074000 ,loss = 0.005562
Epoch = 13 , w = 1.891186,b = 3.066021 ,loss = 0.005412
Epoch = 14 , w = 1.904517,b = 3.059050 ,loss = 0.005297
Epoch = 15 , w = 1.916162,b = 3.052961 ,loss = 0.005210
Epoch = 16 , w = 1.926335,b = 3.047641 ,loss = 0.005142
Epoch = 17 , w = 1.935222,b = 3.042994 ,loss = 0.005091
Epoch = 18 , w = 1.942986,b = 3.038934 ,loss = 0.005051
Epoch = 19 , w = 1.949769,b = 3.035387 ,loss = 0.005021
Epoch = 20 , w = 1.955694,b = 3.032289 ,loss = 0.004998
Epoch = 21 , w = 1.960870,b = 3.029582 ,loss = 0.004980
Epoch = 22 , w = 1.965392,b = 3.027218 ,loss = 0.004966
Epoch = 23 , w = 1.969342,b = 3.025152 ,loss = 0.004956
Epoch = 24 , w = 1.972793,b = 3.023348 ,loss = 0.004948
Epoch = 25 , w = 1.975808,b = 3.021771 ,loss = 0.004941
Epoch = 26 , w = 1.978442,b = 3.020394 ,loss = 0.004937
Epoch = 27 , w = 1.980742,b = 3.019191 ,loss = 0.004933
Epoch = 28 , w = 1.982752,b = 3.018140 ,loss = 0.004930
Epoch = 29 , w = 1.984508,b = 3.017222 ,loss = 0.004928
Epoch = 30 , w = 1.986042,b = 3.016420 ,loss = 0.004926
Epoch = 31 , w = 1.987382,b = 3.015719 ,loss = 0.004925
Epoch = 32 , w = 1.988553,b = 3.015107 ,loss = 0.004924
Epoch = 33 , w = 1.989575,b = 3.014572 ,loss = 0.004923
Epoch = 34 , w = 1.990469,b = 3.014105 ,loss = 0.004922
Epoch = 35 , w = 1.991249,b = 3.013697 ,loss = 0.004922
Epoch = 36 , w = 1.991931,b = 3.013340 ,loss = 0.004921
Epoch = 37 , w = 1.992527,b = 3.013029 ,loss = 0.004921
Epoch = 38 , w = 1.993047,b = 3.012757 ,loss = 0.004921
Epoch = 39 , w = 1.993502,b = 3.012519 ,loss = 0.004920
Epoch = 40 , w = 1.993899,b = 3.012311 ,loss = 0.004920
Epoch = 41 , w = 1.994246,b = 3.012130 ,loss = 0.004920
Epoch = 42 , w = 1.994549,b = 3.011972 ,loss = 0.004920
Epoch = 43 , w = 1.994813,b = 3.011833 ,loss = 0.004920
Epoch = 44 , w = 1.995045,b = 3.011712 ,loss = 0.004920
Epoch = 45 , w = 1.995247,b = 3.011607 ,loss = 0.004920
Epoch = 46 , w = 1.995423,b = 3.011514 ,loss = 0.004920
Epoch = 47 , w = 1.995577,b = 3.011434 ,loss = 0.004920
Epoch = 48 , w = 1.995712,b = 3.011363 ,loss = 0.004920
Epoch = 49 , w = 1.995830,b = 3.011302 ,loss = 0.004920
batch_size = 10
Epoch = 0 , w = 2.627484,b = 2.662620 ,loss = 0.022283
Epoch = 1 , w = 2.482123,b = 2.755555 ,loss = 0.014914
Epoch = 2 , w = 2.366523,b = 2.817388 ,loss = 0.010696
Epoch = 3 , w = 2.278350,b = 2.864496 ,loss = 0.008255
Epoch = 4 , w = 2.211115,b = 2.900418 ,loss = 0.006844
Epoch = 5 , w = 2.159845,b = 2.927810 ,loss = 0.006031
Epoch = 6 , w = 2.120750,b = 2.948697 ,loss = 0.005563
Epoch = 7 , w = 2.090938,b = 2.964625 ,loss = 0.005295
Epoch = 8 , w = 2.068205,b = 2.976770 ,loss = 0.005142
Epoch = 9 , w = 2.050870,b = 2.986031 ,loss = 0.005055
Epoch = 10 , w = 2.037652,b = 2.993094 ,loss = 0.005006
Epoch = 11 , w = 2.027572,b = 2.998479 ,loss = 0.004979
Epoch = 12 , w = 2.019886,b = 3.002585 ,loss = 0.004965
Epoch = 13 , w = 2.014025,b = 3.005717 ,loss = 0.004957
Epoch = 14 , w = 2.009556,b = 3.008104 ,loss = 0.004953
Epoch = 15 , w = 2.006148,b = 3.009925 ,loss = 0.004951
Epoch = 16 , w = 2.003549,b = 3.011314 ,loss = 0.004951
Epoch = 17 , w = 2.001568,b = 3.012372 ,loss = 0.004950
Epoch = 18 , w = 2.000056,b = 3.013180 ,loss = 0.004951
Epoch = 19 , w = 1.998904,b = 3.013795 ,loss = 0.004951
Epoch = 20 , w = 1.998025,b = 3.014265 ,loss = 0.004951
Epoch = 21 , w = 1.997355,b = 3.014623 ,loss = 0.004951
Epoch = 22 , w = 1.996845,b = 3.014896 ,loss = 0.004951
Epoch = 23 , w = 1.996455,b = 3.015104 ,loss = 0.004952
Epoch = 24 , w = 1.996158,b = 3.015263 ,loss = 0.004952
Epoch = 25 , w = 1.995931,b = 3.015384 ,loss = 0.004952
Epoch = 26 , w = 1.995759,b = 3.015476 ,loss = 0.004952
Epoch = 27 , w = 1.995627,b = 3.015546 ,loss = 0.004952
Epoch = 28 , w = 1.995526,b = 3.015600 ,loss = 0.004952
Epoch = 29 , w = 1.995450,b = 3.015641 ,loss = 0.004952
Epoch = 30 , w = 1.995391,b = 3.015672 ,loss = 0.004952
Epoch = 31 , w = 1.995347,b = 3.015696 ,loss = 0.004952
Epoch = 32 , w = 1.995313,b = 3.015714 ,loss = 0.004952
Epoch = 33 , w = 1.995287,b = 3.015728 ,loss = 0.004952
Epoch = 34 , w = 1.995267,b = 3.015738 ,loss = 0.004952
Epoch = 35 , w = 1.995252,b = 3.015746 ,loss = 0.004952
Epoch = 36 , w = 1.995241,b = 3.015753 ,loss = 0.004952
Epoch = 37 , w = 1.995232,b = 3.015757 ,loss = 0.004952
Epoch = 38 , w = 1.995225,b = 3.015761 ,loss = 0.004952
Epoch = 39 , w = 1.995220,b = 3.015764 ,loss = 0.004952
Epoch = 40 , w = 1.995216,b = 3.015766 ,loss = 0.004952
Epoch = 41 , w = 1.995213,b = 3.015767 ,loss = 0.004952
Epoch = 42 , w = 1.995211,b = 3.015768 ,loss = 0.004952
Epoch = 43 , w = 1.995209,b = 3.015769 ,loss = 0.004952
Epoch = 44 , w = 1.995208,b = 3.015770 ,loss = 0.004952
Epoch = 45 , w = 1.995207,b = 3.015771 ,loss = 0.004952
Epoch = 46 , w = 1.995206,b = 3.015771 ,loss = 0.004952
Epoch = 47 , w = 1.995206,b = 3.015771 ,loss = 0.004952
Epoch = 48 , w = 1.995205,b = 3.015772 ,loss = 0.004952
Epoch = 49 , w = 1.995205,b = 3.015772 ,loss = 0.004952
batch_size = 15
Epoch = 0 , w = 0.359754,b = 3.013313 ,loss = 0.427990
Epoch = 1 , w = 0.753299,b = 3.498736 ,loss = 0.075995
Epoch = 2 , w = 0.903888,b = 3.542616 ,loss = 0.055048
Epoch = 3 , w = 1.004769,b = 3.512235 ,loss = 0.046501
Epoch = 4 , w = 1.090577,b = 3.472006 ,loss = 0.039700
Epoch = 5 , w = 1.167951,b = 3.433004 ,loss = 0.034029
Epoch = 6 , w = 1.238552,b = 3.396928 ,loss = 0.029284
Epoch = 7 , w = 1.303122,b = 3.363848 ,loss = 0.025311
Epoch = 8 , w = 1.362202,b = 3.333566 ,loss = 0.021986
Epoch = 9 , w = 1.416263,b = 3.305853 ,loss = 0.019201
Epoch = 10 , w = 1.465732,b = 3.280493 ,loss = 0.016871
Epoch = 11 , w = 1.511001,b = 3.257288 ,loss = 0.014919
Epoch = 12 , w = 1.552425,b = 3.236052 ,loss = 0.013286
Epoch = 13 , w = 1.590330,b = 3.216621 ,loss = 0.011919
Epoch = 14 , w = 1.625017,b = 3.198839 ,loss = 0.010774
Epoch = 15 , w = 1.656758,b = 3.182568 ,loss = 0.009816
Epoch = 16 , w = 1.685803,b = 3.167679 ,loss = 0.009014
Epoch = 17 , w = 1.712381,b = 3.154054 ,loss = 0.008343
Epoch = 18 , w = 1.736702,b = 3.141586 ,loss = 0.007782
Epoch = 19 , w = 1.758958,b = 3.130177 ,loss = 0.007312
Epoch = 20 , w = 1.779323,b = 3.119737 ,loss = 0.006918
Epoch = 21 , w = 1.797959,b = 3.110184 ,loss = 0.006589
Epoch = 22 , w = 1.815012,b = 3.101442 ,loss = 0.006314
Epoch = 23 , w = 1.830617,b = 3.093442 ,loss = 0.006083
Epoch = 24 , w = 1.844897,b = 3.086122 ,loss = 0.005890
Epoch = 25 , w = 1.857964,b = 3.079423 ,loss = 0.005729
Epoch = 26 , w = 1.869921,b = 3.073294 ,loss = 0.005594
Epoch = 27 , w = 1.880863,b = 3.067685 ,loss = 0.005481
Epoch = 28 , w = 1.890875,b = 3.062552 ,loss = 0.005387
Epoch = 29 , w = 1.900037,b = 3.057855 ,loss = 0.005308
Epoch = 30 , w = 1.908421,b = 3.053557 ,loss = 0.005242
Epoch = 31 , w = 1.916093,b = 3.049624 ,loss = 0.005186
Epoch = 32 , w = 1.923113,b = 3.046026 ,loss = 0.005140
Epoch = 33 , w = 1.929538,b = 3.042732 ,loss = 0.005102
Epoch = 34 , w = 1.935416,b = 3.039719 ,loss = 0.005070
Epoch = 35 , w = 1.940796,b = 3.036961 ,loss = 0.005043
Epoch = 36 , w = 1.945718,b = 3.034438 ,loss = 0.005020
Epoch = 37 , w = 1.950222,b = 3.032129 ,loss = 0.005001
Epoch = 38 , w = 1.954344,b = 3.030016 ,loss = 0.004986
Epoch = 39 , w = 1.958116,b = 3.028082 ,loss = 0.004973
Epoch = 40 , w = 1.961568,b = 3.026313 ,loss = 0.004962
Epoch = 41 , w = 1.964726,b = 3.024694 ,loss = 0.004953
Epoch = 42 , w = 1.967616,b = 3.023212 ,loss = 0.004945
Epoch = 43 , w = 1.970261,b = 3.021856 ,loss = 0.004939
Epoch = 44 , w = 1.972681,b = 3.020616 ,loss = 0.004933
Epoch = 45 , w = 1.974895,b = 3.019480 ,loss = 0.004929
Epoch = 46 , w = 1.976922,b = 3.018442 ,loss = 0.004925
Epoch = 47 , w = 1.978776,b = 3.017491 ,loss = 0.004922
Epoch = 48 , w = 1. 980473,b = 3.016621 ,loss = 0.004920
Epoch = 49 , w = 1.982026,b = 3.015825 ,loss = 0.004918
六、实验结论
SGD的迭代效果会和batch_size有关,batch_size过大或者过小都会导致权值的更新速度变慢。此处,batch_size = 10就是一个比较合适的大小。SGD在随着epoch增加的时候会发生上下波动,这也正是其随机性的体现。
七、问题解答
- 问题2:为什么是椭圆而不是圆?如何把这个图变成一个圆?
- 答:因为损失函数的表达式是\(f(w,b) = \Sigma(w*x+b-y)^2\)=\(w^2*x^2+b^2+y^2+C*w+D*b+K\),因此w前面有一个x的系数,这样的话这个函数就明显是一个椭圆形的函数。如果我们想要画成一个圆,只需要把损失函数\(f(w,b)\)改成\(f(w,b) = (w*y-w*x-b)^2\),这样的画画出来的损失函数关于\(w和b\)的图像将会是一个圆形。但是此时的损失函数的意义没有原来的那么明确。
- 问题3:为什么中心是个椭圆区域而不是一个点?
- 答:我的理解是
- 1、我们的数据精度不够,导致原本不同的点由于精度的原因认为其相等。
- 2、由于SGD只能得到局部最优解,而不能得到全局最优解,因此局部最优解可能有很多个,因此得到是一个区域。
- 3、实际上我们的w和b也不是连续的而是一堆离散的点,因此会存在很多个近似相等的最优解。
- 答:我的理解是
