
读书笔记 zhutianqing的书籍 Differential Privacy and Application
这是记录看zhutianqing的这本书的看书笔记

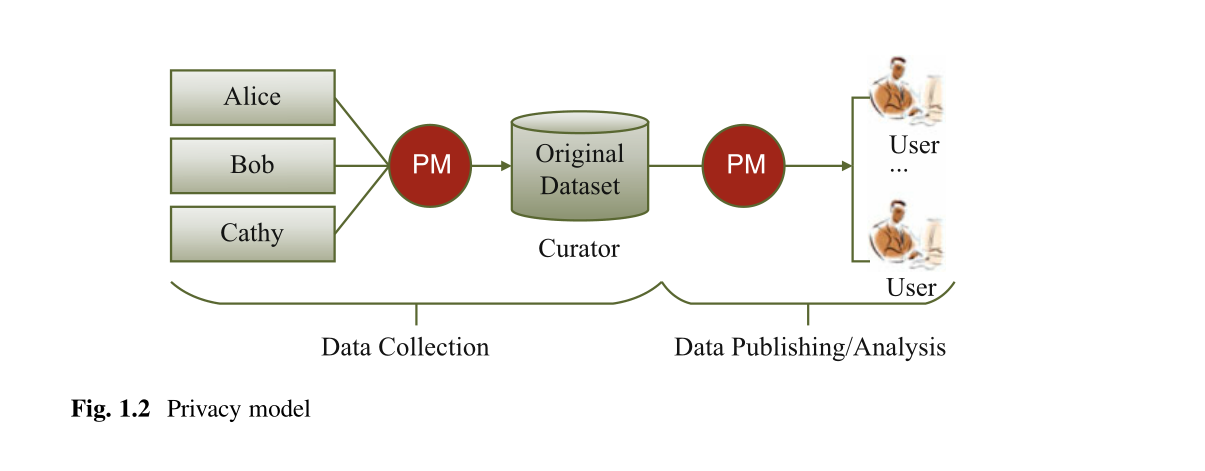




有多种查询类型,例如计数,总和,均值和范围查询。
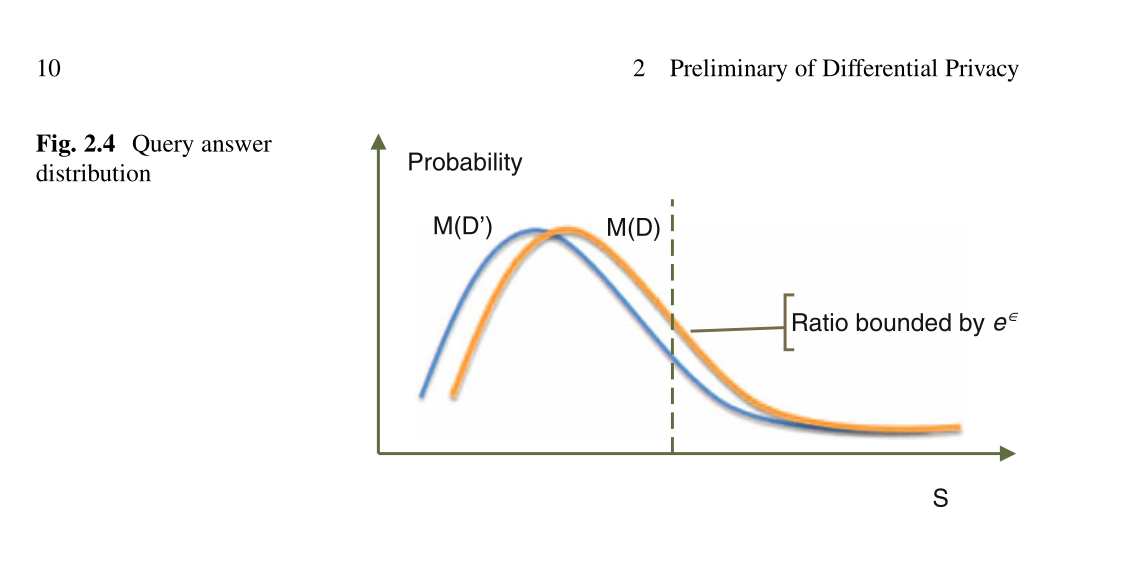
当查询具有相对较低的敏感度值(例如计数或求和查询)时,全局敏感度效果很好。
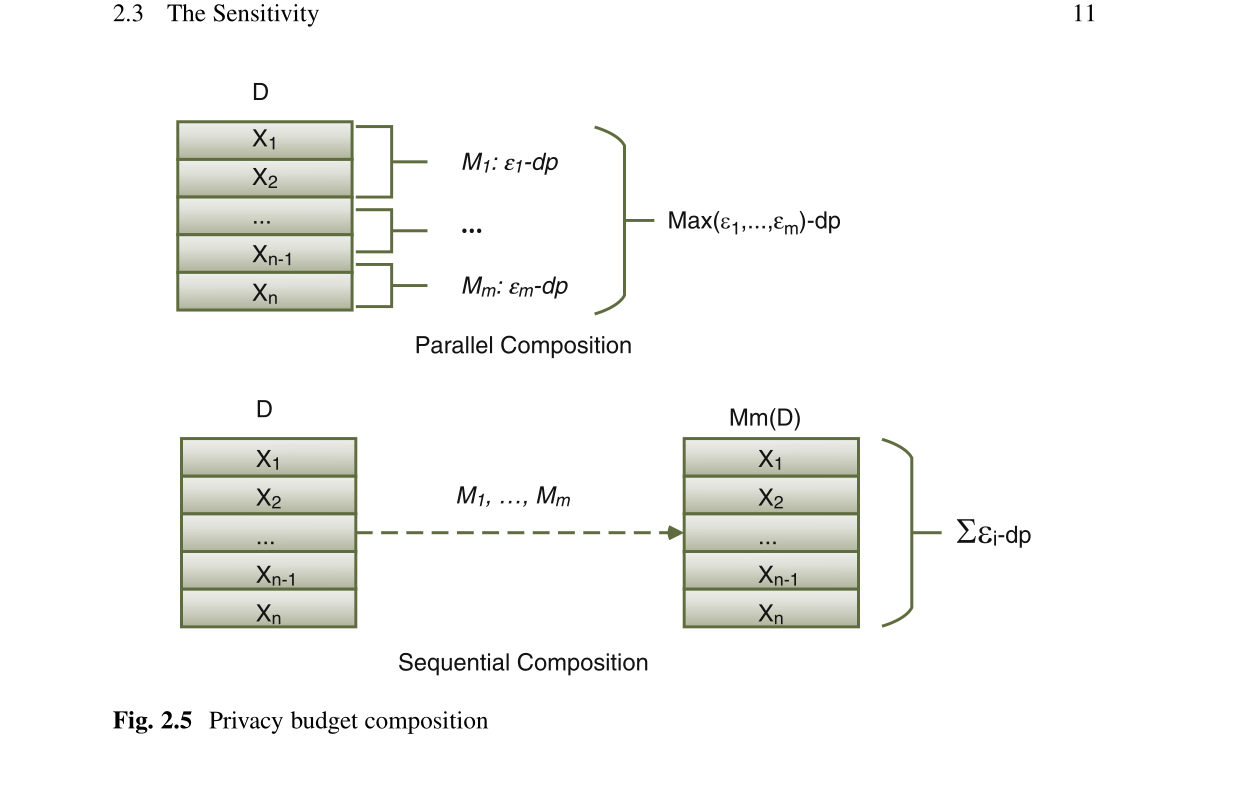
当真实答案超过数百或数千时,灵敏度远低于真实答案。但是对于诸如中位数,平均值之类的查询,与真实答案相比,全局敏感性会产生较高的值。然后,我们将对这些查询求助于本地敏感性。

平滑的界限
Chapter 3
Differentially Private Data Publishing: Settings
and Mechanisms

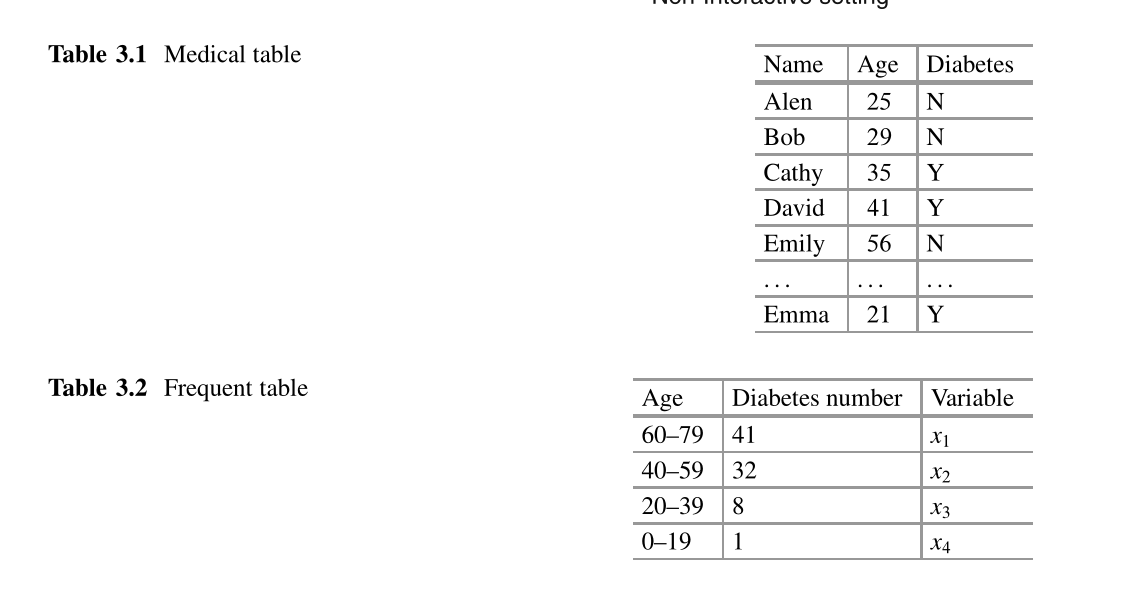

We categorize the existing mechanisms into several types: transformation, partition-ing of dataset, query separation and iteration. Tables 3.1 and 3.2 are used again to show the key idea of those types.

Chapter 4
Differentially Private Data Publishing:
Interactive Setting
交互式设置在输入数据的各个方面进行操作,包括交易,直方图,流和图形数据集。在以下各节中,我们讨论涉及这些类型的输入数据的发布方案。
4.2 直方图发布
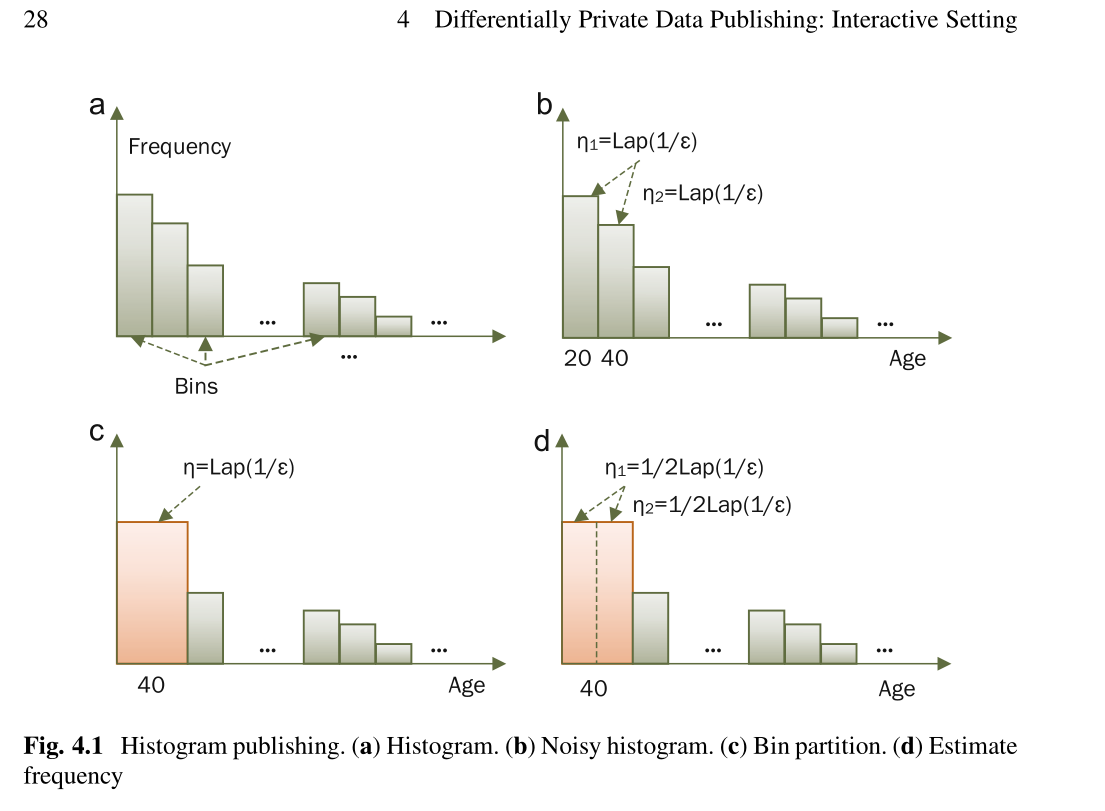
从交易数据的直方图表示形式来看通常很方便。假设直方图具有N个bin,则差分隐私机制旨在隐藏每个bin的频率。直方图表示的优点是限制了对噪声的敏感性[62]。例如,当直方图用于支持范围或计数查询时,添加或删除单个记录最多将影响一个bin。因此,直方图上的范围或计数查询具有等于1的敏感度,并且每个bin的附加噪声量将相对较小。
4.2.1 Laplace
这是一种直接机制,可将拉普拉斯噪声添加到查询覆盖的每个bin的频率中。当一定范围的查询仅覆盖少量的bin时,此机制对查询结果保留了很高的实用性;但是,如果原始数据集包含多个属性,则这些属性及其相关的值范围的组合将导致大量的bin。由于大量错误累积,查询的答案毫无意义。
4.3 Stream Data Publishing
4.4 Graph Data Publishing
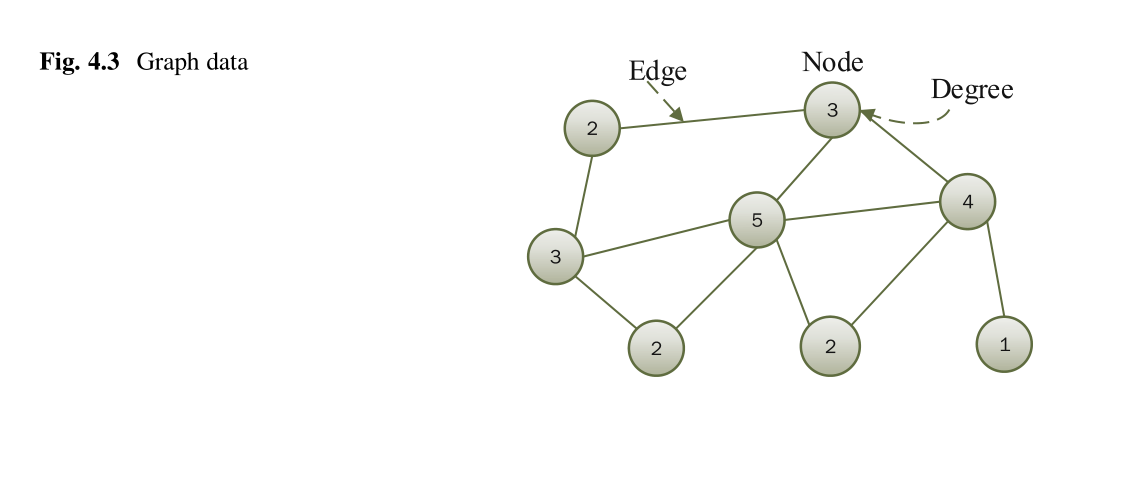
对于图形数据,隐私问题更为严重。对于交易数据集记录,至少给出属性。在图形数据中,属性是派生的,没有给出。例如,给定一个图,要隐藏的重要属性是什么?

现有方法在基本图统计的边缘差分隐私甚至节点差分隐私保证方面都可以很好地工作。但是,发布特定的统计数据(例如切割,节点之间的成对距离或超图)仍然是未解决的问题 。
经过分析,我们得出结论,交互式出版物中的这些度量是相互关联的。例如,给定固定的隐私预算,较高的准确性通常会导致较少的查询。另一方面,以固定的精度,大量查询通常会导致计算效率低下的机制。因此,数据发布机制设计的目标是获得可以平衡上述度量的更好结果。实际上,机制的选择取决于应用程序的要求。
Chapter 5
Differentially Private Data Publishing:
Non-interactive Setting
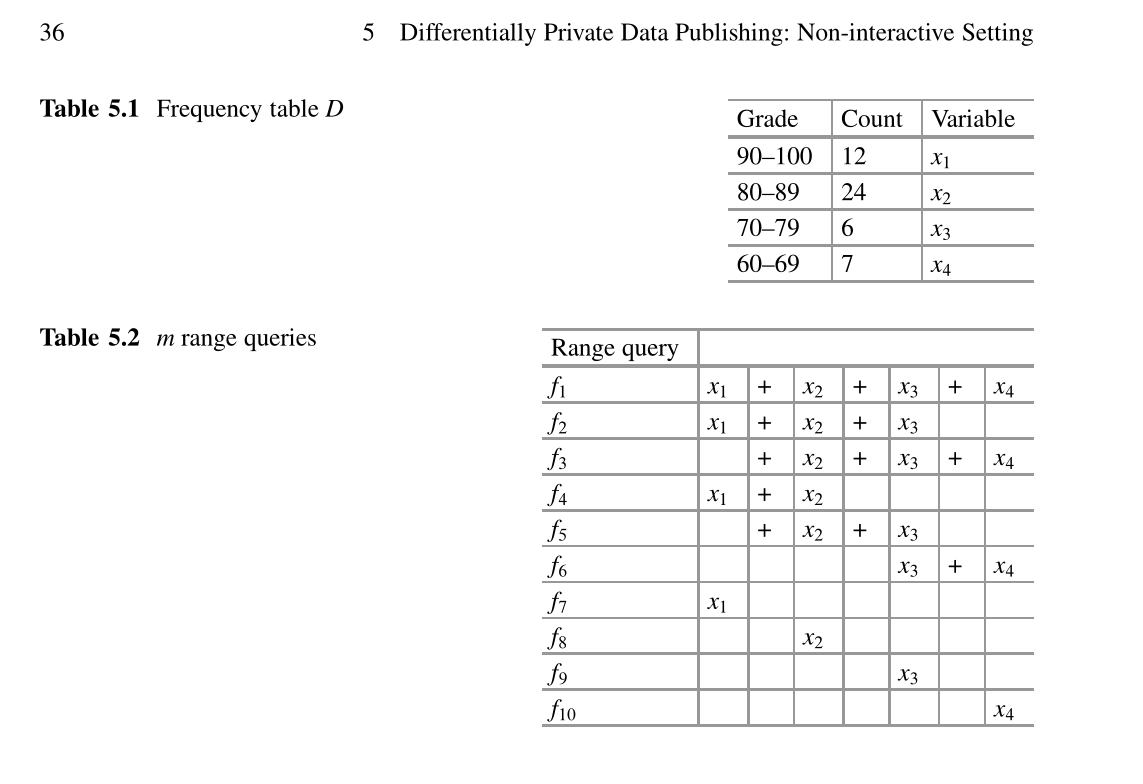
非交互式设置意味着所有查询一次都提供给策展人。非交互式发布的关键挑战是灵敏度测量。查询之间的相关性将大大提高敏感性。提出了两种可能的方法来解决此问题:一种是分解批查询之间的相关性(如第5.1节所述),另一种是发布具有差异隐私约束的综合数据集来回答那些提出的查询。相关方法在综合数据集发布部分中介绍




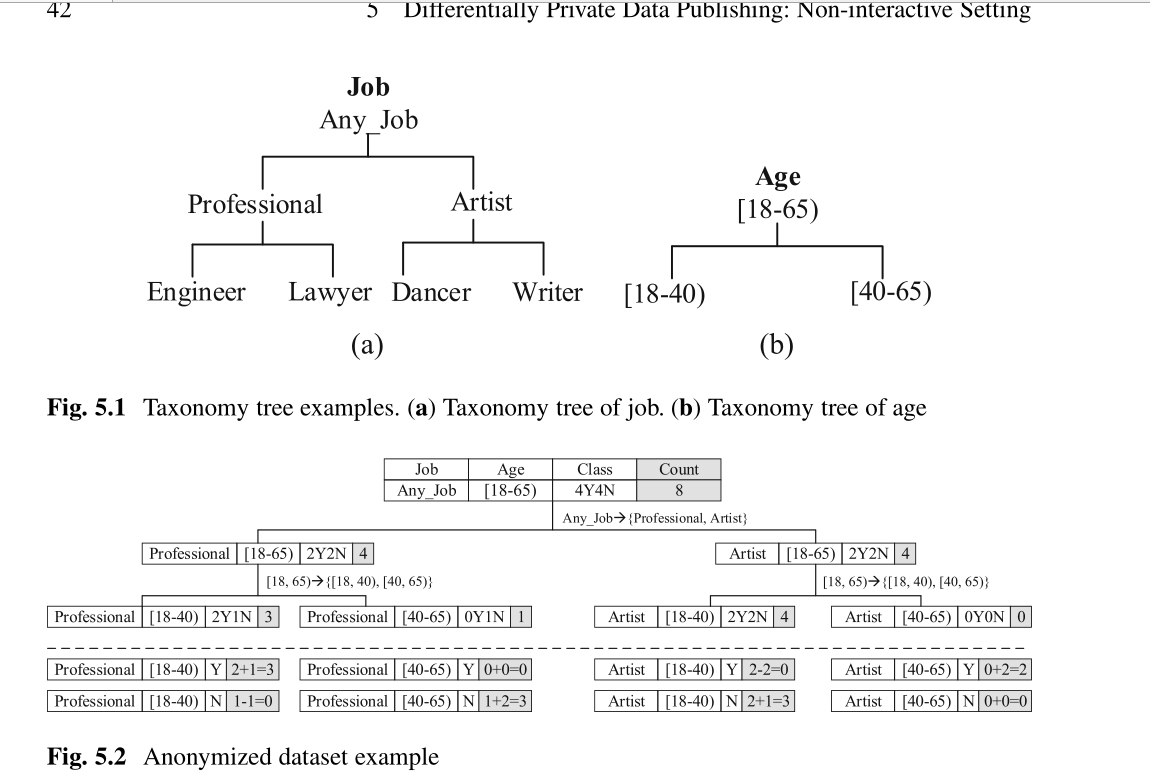

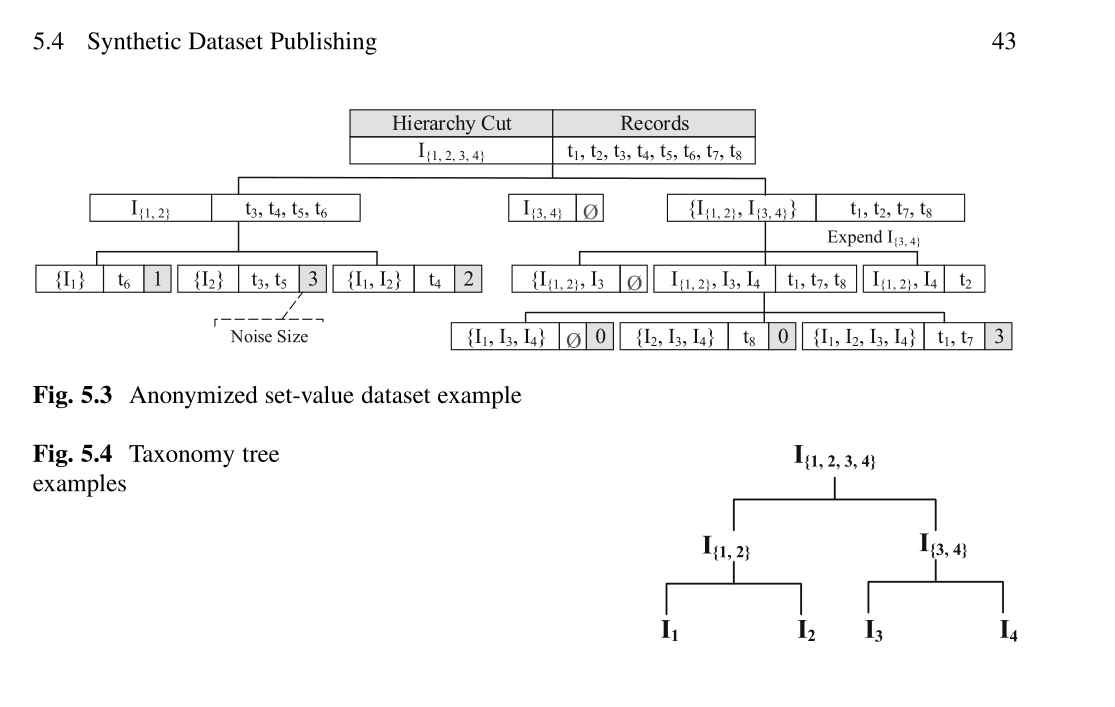
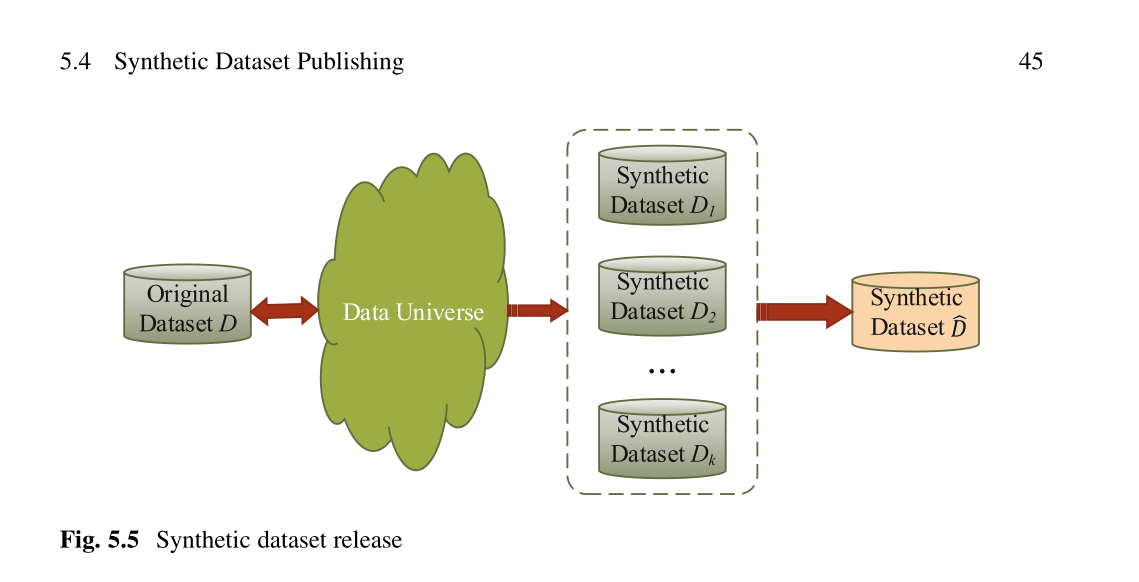
总而言之,计算学习理论扩展了合成数据发布的研究工作,证明可以在保持差异隐私的同时保持可接受的效用。然而,如何降低计算复杂性以及如何在这些数据集上提供各种类型的查询仍然是挑战。

Chapter 6
Differentially Private Data Analysis
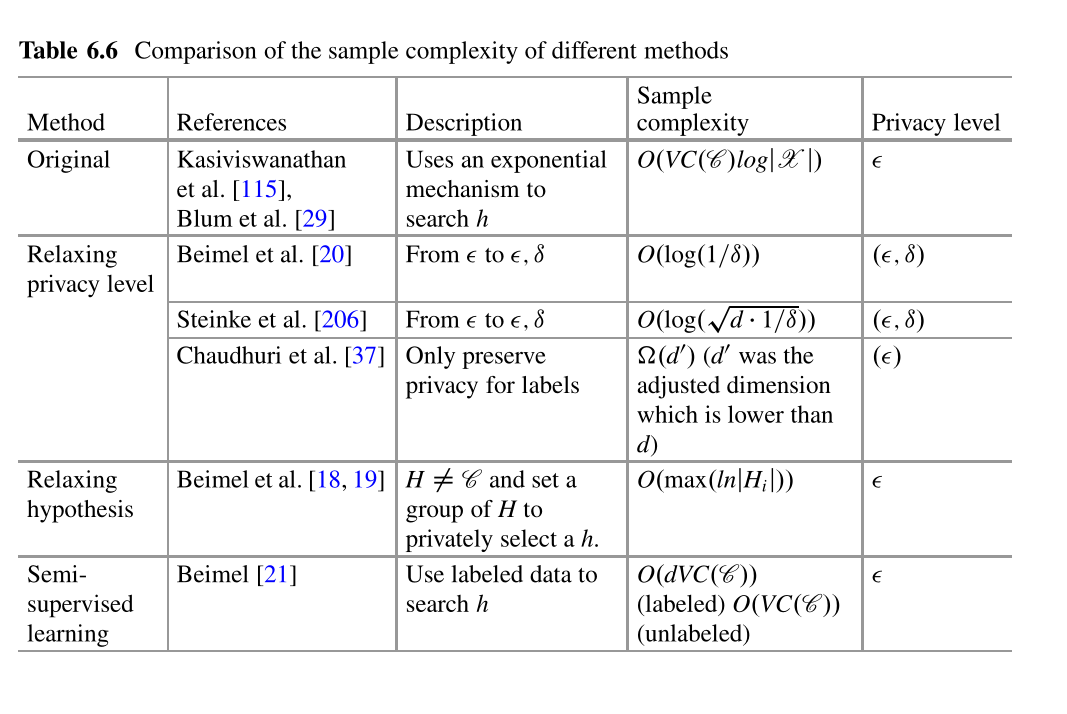
隐私是广泛应用中越来越重要的问题,需要改进现有的非私有算法以满足隐私保护的要求。这些非私有算法可以是数据挖掘,机器学习或统计分析算法。保护隐私的直接方法是将差分私有机制(例如Laplace或指数机制)合并到现有算法中。我们将这种合并视为差分私有数据分析,这是引起重要研究关注的重要研究方向。差异化私有数据分析旨在发布近似准确的分析模型,而不是查询答案或综合数据集。基本思想是将当前的非私有算法扩展为差分隐私算法。可以通过几个框架来实现此扩展,可以将其大致分为Laplace /指数框架和私有学习框架。表6.1显示了差异私有数据分析问题的特征,其中研究人员关注这两个框架的准确性和计算效率。由于不同的论文使用不同的术语来描述输出,因此“模型”和“算法”在本节中可以互换。
6.1 Laplace/Exponential Framework
最常见的扩展方法是将Laplace或指数机制合并到非私有分析算法中,因此被称为Laplace /指数框架。
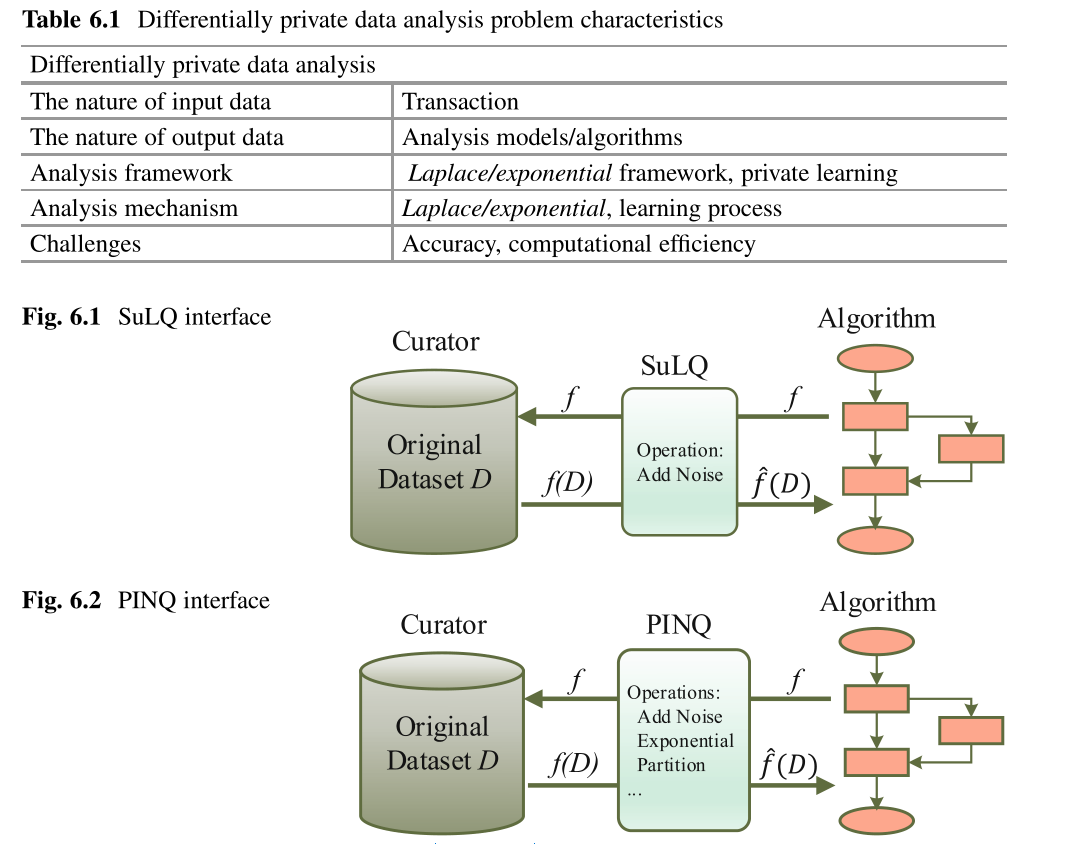
6.1.2 Specific Algorithms in the Laplace/Exponential Framework
6.1.2.1 Supervised Learning

6.1.2.2 Unsupervised Learning
6.1.2.3 Frequent Itemset Mining


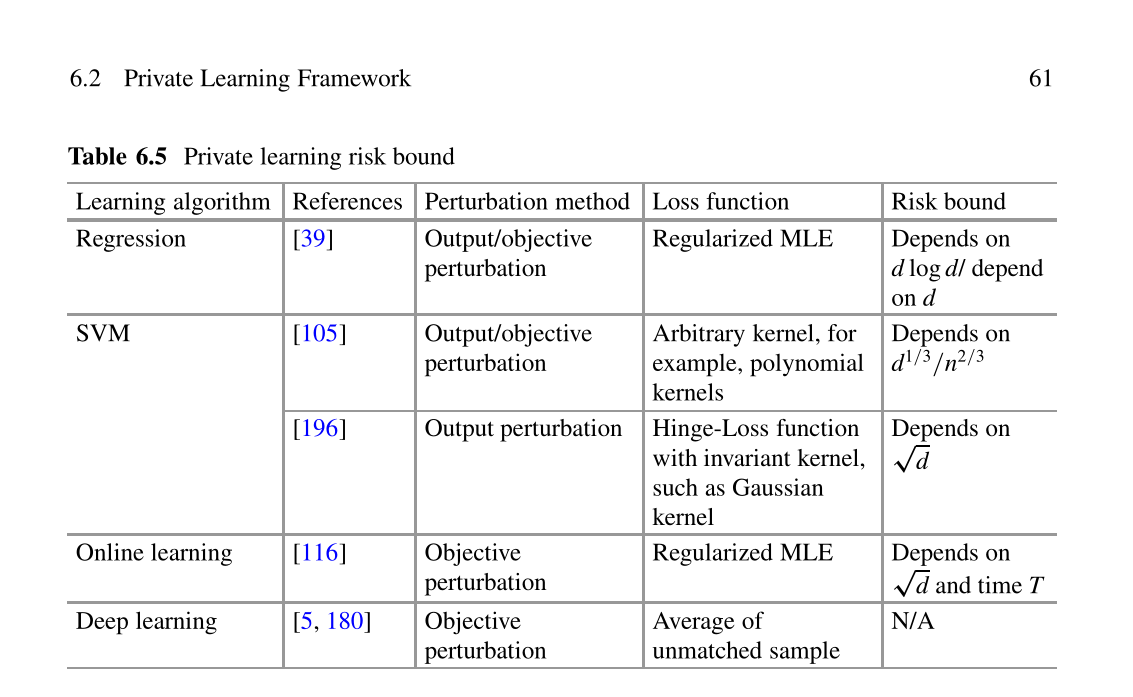
Laplace /指数框架可以将Laplace或指数机制自由地引入各种算法。但是,分析结果的实用性对该框架是一个挑战。当在算法步骤中增加噪声时,不清楚效用损失将是多大,并且分析结果不容易比较。解决这一难题的一种可能方法是通过优化的观点并利用一些现有的理论(例如学习理论)来解决数据分析问题[115],以便可以估算和比较效用损失。基于这种直觉,研究人员提出了私人学习框架。
6.2 Private Learning Framework
机器学习是各个领域中最常用的技术之一。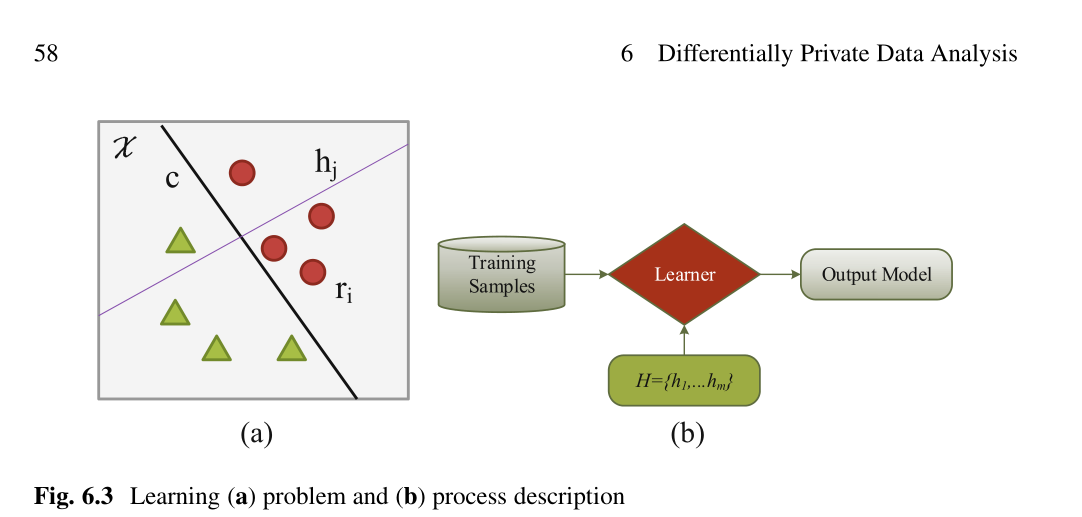
•如何根据差异隐私选择最佳模型?
•要达到有限的精度,需要多少个样本?
6.2.1 Foundation of ERM
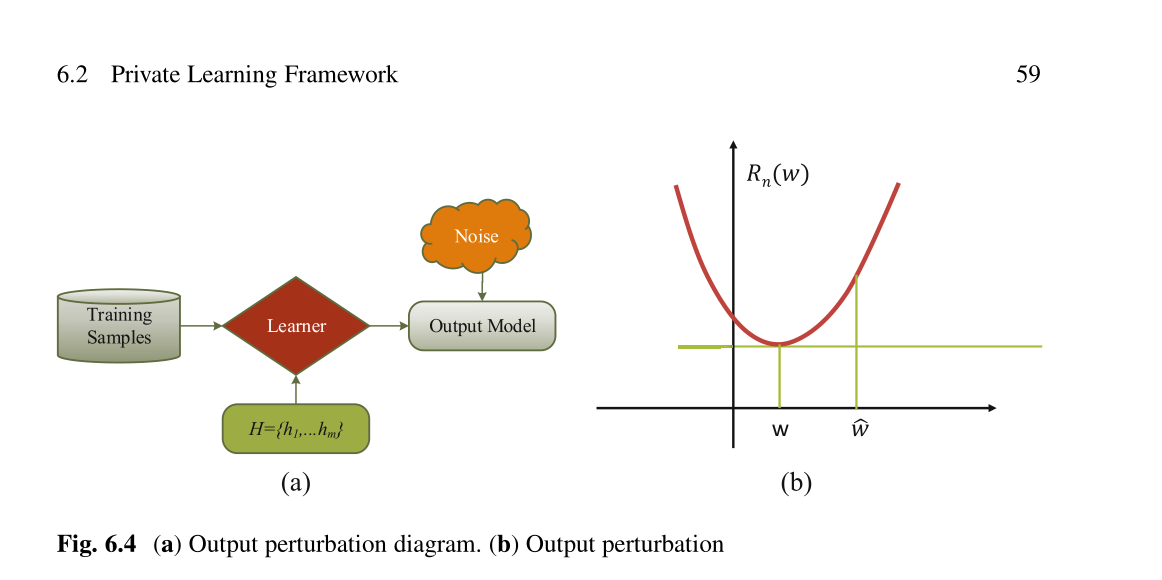
6.2.2 Private Learning in ERM
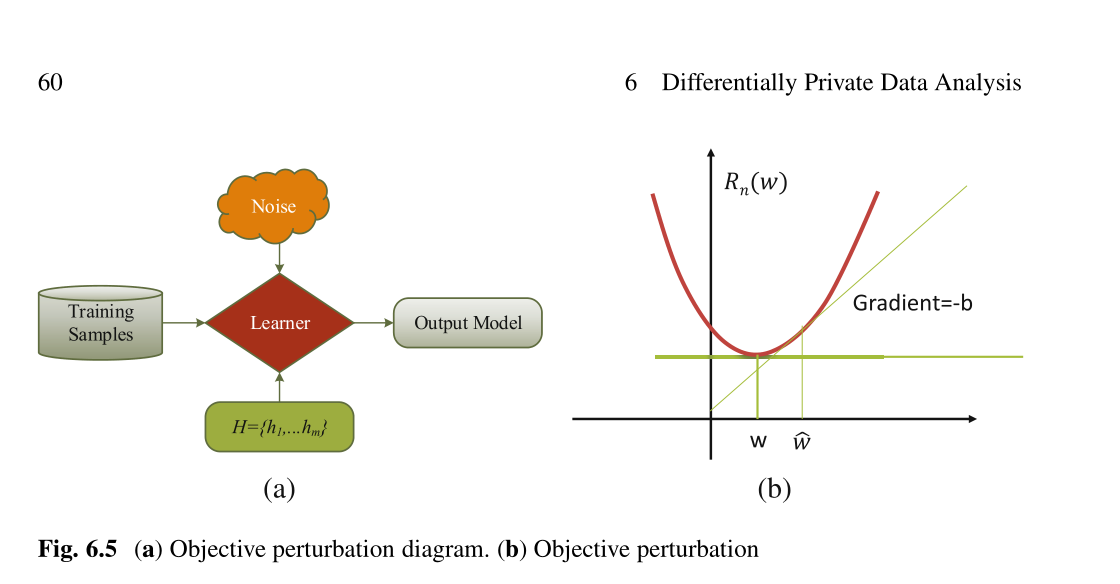
总结:但是,私人学习框架有一些限制。 ERM要求目标函数应该是凸函数和L-Lipschitz。 PAC学习只能在算法可学习的情况下应用。这些限制阻碍了隐私学习框架的实际发展,使它们成为积极发展的理论命题,但对于实际应用仍然不切实际。
对于图形数据,隐私问题更为严重。对于交易数据集记录,至少给出属性。在图形数据中,属性是派生的,没有给出。例如,给定一个图,要隐藏的重要属性是什么?
------------恢复内容开始------------
这是记录看zhutianqing的这本书的看书笔记
有多种查询类型,例如计数,总和,均值和范围查询。
当查询具有相对较低的敏感度值(例如计数或求和查询)时,全局敏感度效果很好。
当真实答案超过数百或数千时,灵敏度远低于真实答案。但是对于诸如中位数,平均值之类的查询,与真实答案相比,全局敏感性会产生较高的值。然后,我们将对这些查询求助于本地敏感性。
平滑的界限
Chapter 3
Differentially Private Data Publishing: Settings
and Mechanisms
We categorize the existing mechanisms into several types: transformation, partition-ing of dataset, query separation and iteration. Tables 3.1 and 3.2 are used again to show the key idea of those types.
Chapter 4
Differentially Private Data Publishing:
Interactive Setting
交互式设置在输入数据的各个方面进行操作,包括交易,直方图,流和图形数据集。在以下各节中,我们讨论涉及这些类型的输入数据的发布方案。
4.2 直方图发布
从交易数据的直方图表示形式来看通常很方便。假设直方图具有N个bin,则差分隐私机制旨在隐藏每个bin的频率。直方图表示的优点是限制了对噪声的敏感性[62]。例如,当直方图用于支持范围或计数查询时,添加或删除单个记录最多将影响一个bin。因此,直方图上的范围或计数查询具有等于1的敏感度,并且每个bin的附加噪声量将相对较小。
4.2.1 Laplace
这是一种直接机制,可将拉普拉斯噪声添加到查询覆盖的每个bin的频率中。当一定范围的查询仅覆盖少量的bin时,此机制对查询结果保留了很高的实用性;但是,如果原始数据集包含多个属性,则这些属性及其相关的值范围的组合将导致大量的bin。由于大量错误累积,查询的答案毫无意义。
4.3 Stream Data Publishing
4.4 Graph Data Publishing
对于图形数据,隐私问题更为严重。对于交易数据集记录,至少给出属性。在图形数据中,属性是派生的,没有给出。例如,给定一个图,要隐藏的重要属性是什么?
现有方法在基本图统计的边缘差分隐私甚至节点差分隐私保证方面都可以很好地工作。但是,发布特定的统计数据(例如切割,节点之间的成对距离或超图)仍然是未解决的问题 。
经过分析,我们得出结论,交互式出版物中的这些度量是相互关联的。例如,给定固定的隐私预算,较高的准确性通常会导致较少的查询。另一方面,以固定的精度,大量查询通常会导致计算效率低下的机制。因此,数据发布机制设计的目标是获得可以平衡上述度量的更好结果。实际上,机制的选择取决于应用程序的要求。
Chapter 5
Differentially Private Data Publishing:
Non-interactive Setting
非交互式设置意味着所有查询一次都提供给策展人。非交互式发布的关键挑战是灵敏度测量。查询之间的相关性将大大提高敏感性。提出了两种可能的方法来解决此问题:一种是分解批查询之间的相关性(如第5.1节所述),另一种是发布具有差异隐私约束的综合数据集来回答那些提出的查询。相关方法在综合数据集发布部分中介绍
总而言之,计算学习理论扩展了合成数据发布的研究工作,证明可以在保持差异隐私的同时保持可接受的效用。然而,如何降低计算复杂性以及如何在这些数据集上提供各种类型的查询仍然是挑战。
Chapter 6
Differentially Private Data Analysis
隐私是广泛应用中越来越重要的问题,需要改进现有的非私有算法以满足隐私保护的要求。这些非私有算法可以是数据挖掘,机器学习或统计分析算法。保护隐私的直接方法是将差分私有机制(例如Laplace或指数机制)合并到现有算法中。我们将这种合并视为差分私有数据分析,这是引起重要研究关注的重要研究方向。差异化私有数据分析旨在发布近似准确的分析模型,而不是查询答案或综合数据集。基本思想是将当前的非私有算法扩展为差分隐私算法。可以通过几个框架来实现此扩展,可以将其大致分为Laplace /指数框架和私有学习框架。表6.1显示了差异私有数据分析问题的特征,其中研究人员关注这两个框架的准确性和计算效率。由于不同的论文使用不同的术语来描述输出,因此“模型”和“算法”在本节中可以互换。
6.1 Laplace/Exponential Framework
最常见的扩展方法是将Laplace或指数机制合并到非私有分析算法中,因此被称为Laplace /指数框架。
6.1.2 Specific Algorithms in the Laplace/Exponential Framework
6.1.2.1 Supervised Learning
6.1.2.2 Unsupervised Learning
6.1.2.3 Frequent Itemset Mining
Laplace /指数框架可以将Laplace或指数机制自由地引入各种算法。但是,分析结果的实用性对该框架是一个挑战。当在算法步骤中增加噪声时,不清楚效用损失将是多大,并且分析结果不容易比较。解决这一难题的一种可能方法是通过优化的观点并利用一些现有的理论(例如学习理论)来解决数据分析问题[115],以便可以估算和比较效用损失。基于这种直觉,研究人员提出了私人学习框架。
6.2 Private Learning Framework
机器学习是各个领域中最常用的技术之一。
•如何根据差异隐私选择最佳模型?
•要达到有限的精度,需要多少个样本?
6.2.1 Foundation of ERM
6.2.2 Private Learning in ERM
总结:但是,私人学习框架有一些限制。 ERM要求目标函数应该是凸函数和L-Lipschitz。 PAC学习只能在算法可学习的情况下应用。这些限制阻碍了隐私学习框架的实际发展,使它们成为积极发展的理论命题,但对于实际应用仍然不切实际。
对于图形数据,隐私问题更为严重。对于交易数据集记录,至少给出属性。在图形数据中,属性是派生的,没有给出。例如,给定一个图,要隐藏的重要属性是什么?
Chapter 7
Differentially Private Deep Learning
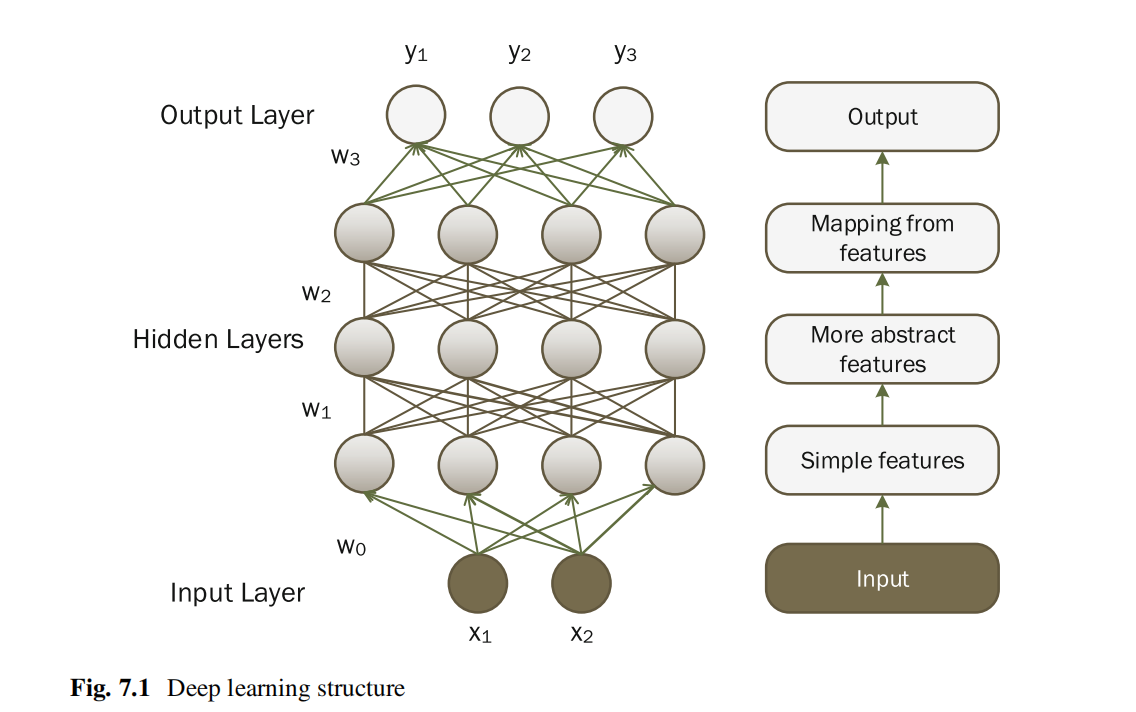
深度学习的基本思想是应用多层结构从高维数据中提取复杂特征,并使用这些特征来构建模型。多层结构由神经元组成。每层中的神经元都从前一层接收有限数量的输出神经元及其关联的权重。训练过程的目的是调整这些神经元的权重以适合训练样本。实际上,随机梯度下降(SGD)程序是实现此目标的最流行方法之一。

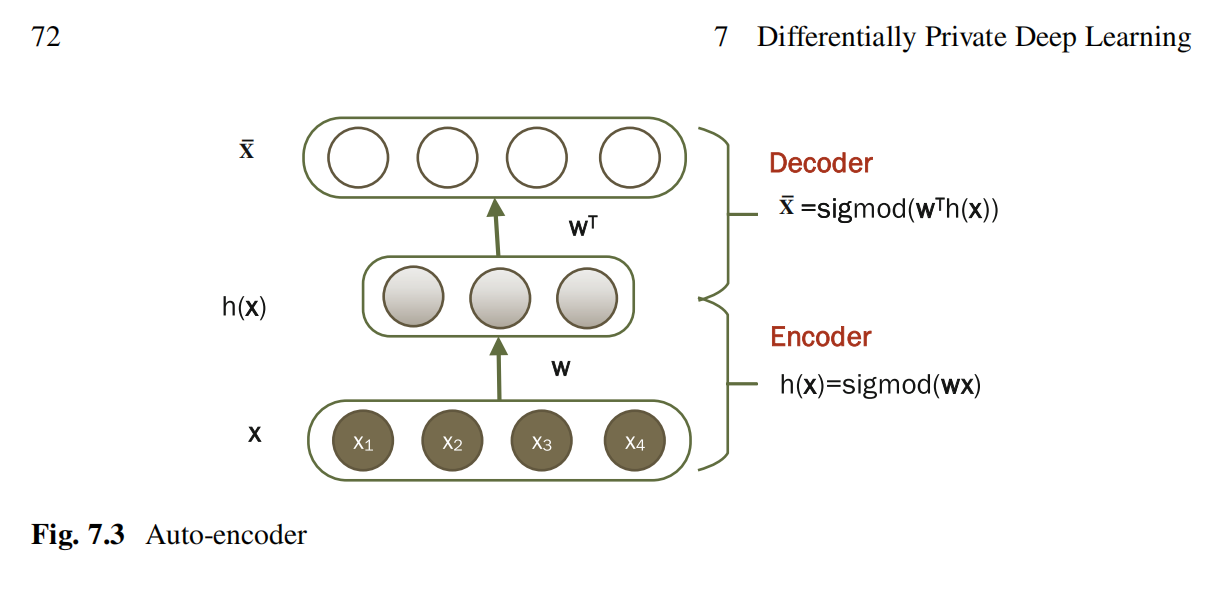
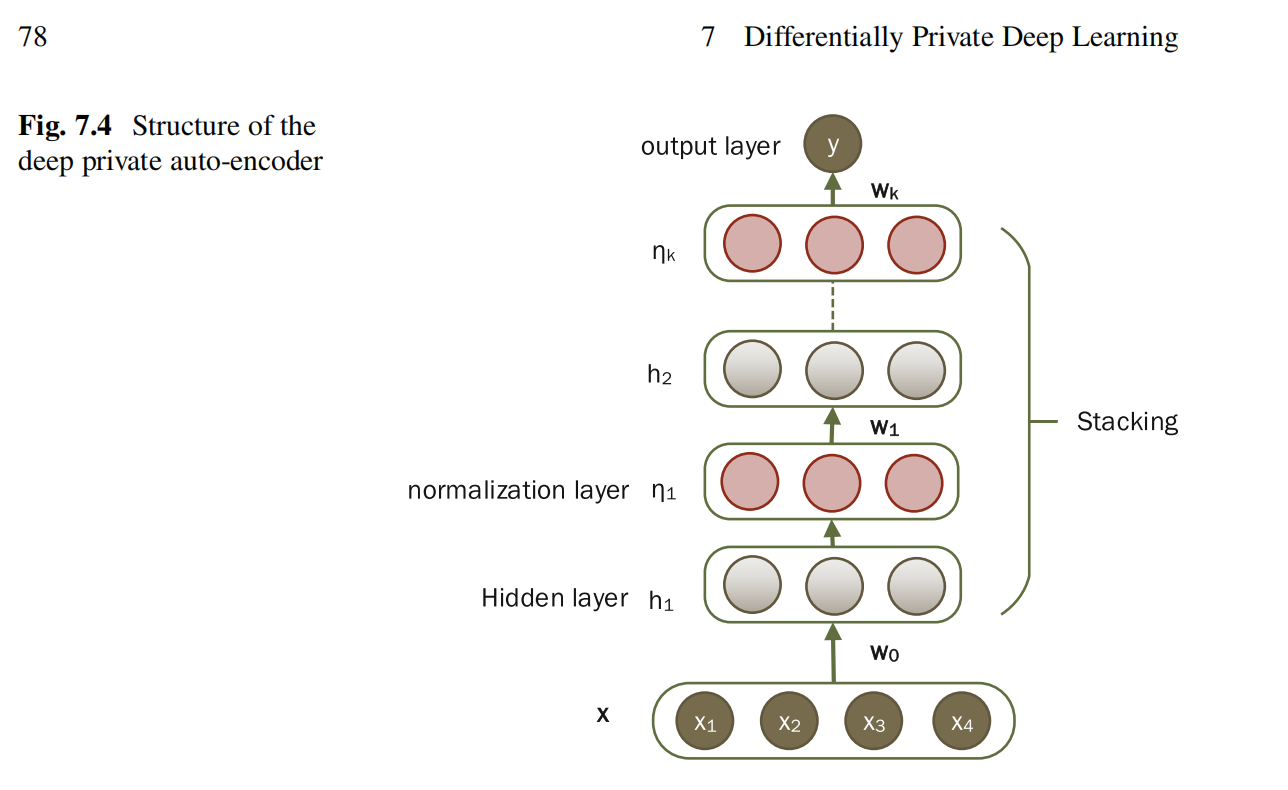
作者简要地介绍了实验的环境

Chapter 8
Differentially Private Applications: Where to Start?
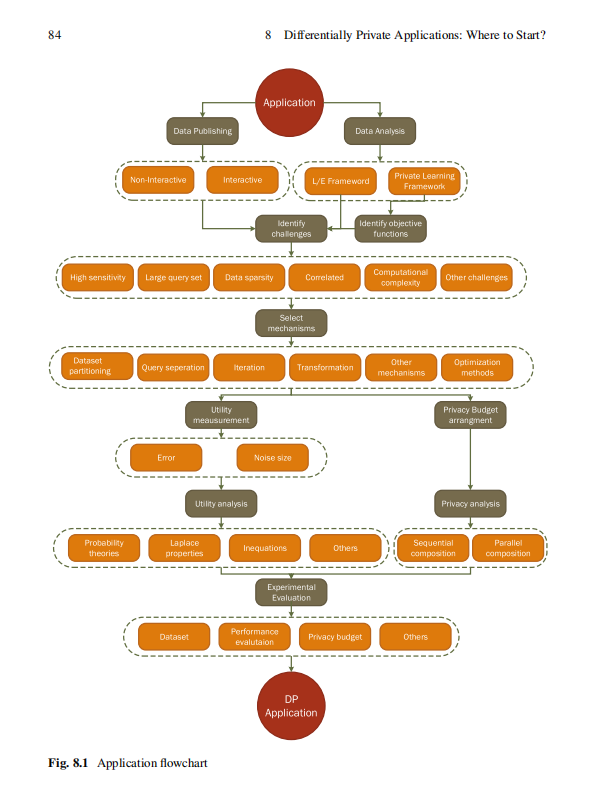
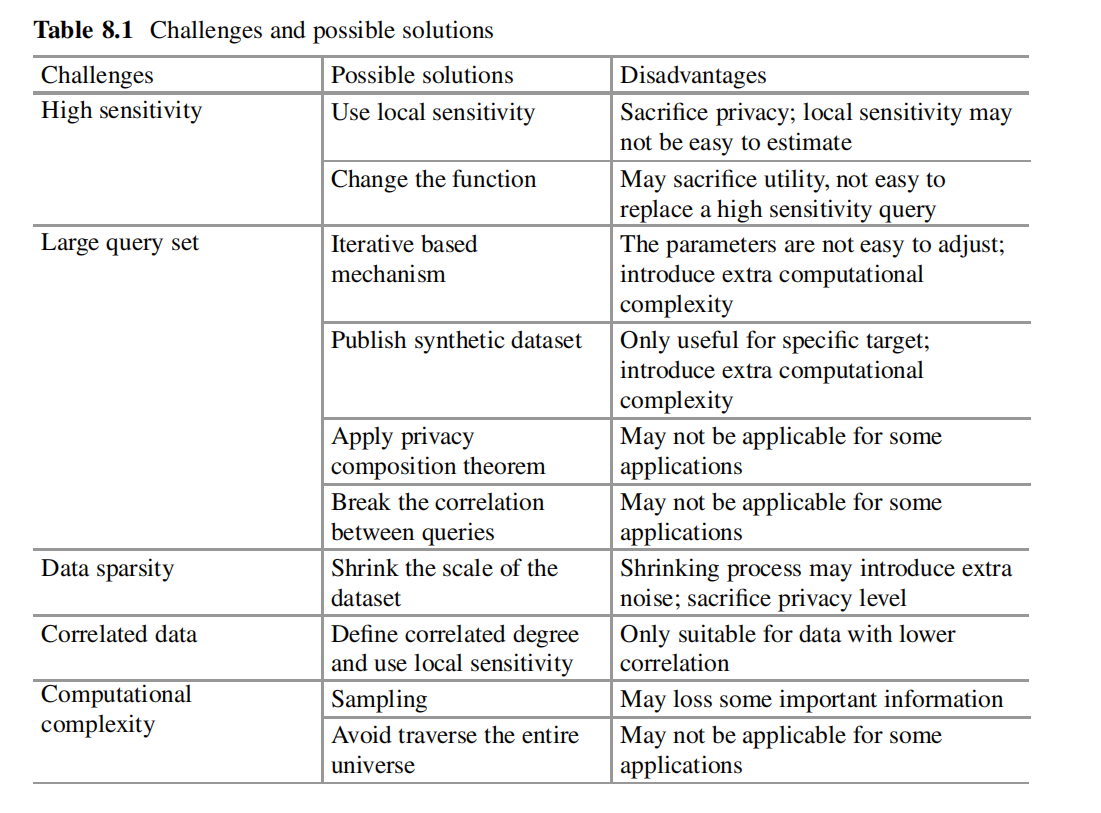
8.3应用程序中有用的公共数据集
8.3.1推荐系统数据集
1http://www.netflixprize.com.
2http://www.grouplens.org.
3https://webscope.sandbox.yahoo.com/catalog.php?datatype=r.
这些都是可用的数据
第一个是netflix的,其中的数据是包括每个用户至少对20部电影评分,并且每部电影已对20–250个用户进行评分。
第二个是电影分级数据集
第三个是yahoo收集2002-2006年用户听歌爱好的数据集
8.3.2 Online Social Network Datasets
斯坦福网络分析平台(SNAP)是一个通用的网络分析和图形挖掘库,其中包含描述超大型网络(包括社交网络,通信网络和运输网络)的数据集[136]。
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号