K-近邻分类法及tabulate、rng、categorical、varfun、discretize函数用法介绍
原理:简单比喻为——人以群分,物以类聚。
优点:对于类域的交叉或重叠较多的待分样本集来说,K-NN较其他方法更合适。
缺点:计算量较大,因为会计算全体已知样本的距离。
改进方法:
(1)解决计算量大,事先对已知样本点进行剪辑,去除对分类作用不大的成分。
(2)尽可能将计算压缩到接近测试样本领域的小范围内,避免盲目地与训练样本集中的每个样本进行距离计算。
算法步骤:
(1)初始化距离为最大值,计算未知样本和每个样本的距离dist.
(2)得到目前k个最邻近样本的最大距离maxdist,若dist<maxdist,则将该训练样本作为K-近邻样本。
(3)重复上述计算距离的步骤,直到所有未知样本与所有训练样本的距离计算完。
(4)统计k个最近邻样本中每个类别出现的次数。
(5)选择出现频率最大的类别作为未知样本的类别。
实例介绍:
根据客户的16个属性,为一家银行建一个分类器,判断客户是否愿意购买理财产品:
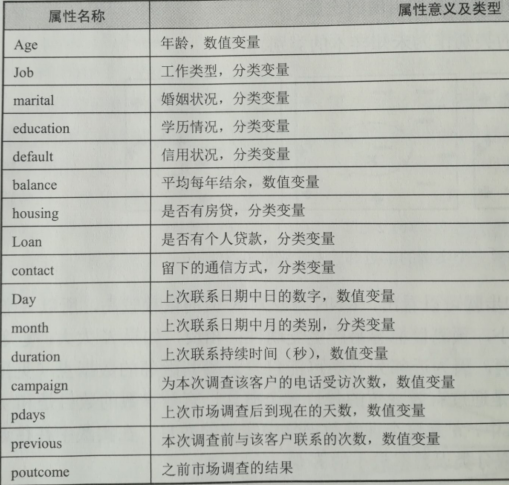


1 %% ———————————机器学习———————————————%% 2 %%%%%%%%%%%%%%%%%%%%%%%1.K-近邻分类%%%%%%%%%%%%%%%%%%%%%%%%% 3 %16个属性分别为: 4 %age job marital education default balance housing loan contact 5 %day month duration campaign pdays previous poutcome y(是否愿意) 6 load 'E:\数学建模\学习资料\程序_MATLAB数学建模方法与实践_卓金武等\Cha5\Classification_method_examples\bank.mat';%载入记录数据 7 names = bank.Properties.VariableNames;%使用数据文件,记录自变量和因变量的属性名 8 category = varfun(@iscellstr,bank,'Output','uniform'); %输出格式为数值格式。为字符串的返回结果为1,为数字的返回结果为0 9 for i = find(category) 10 bank.(names{i}) = categorical(bank.(names{i})); 11 %将bank中的属性创建分类数组。bank.(names{i}) 的类别是bank.(names{i})经过分类后的唯一值且经过排序 12 end 13 catPred = category(1:end-1); 14 rng('default');%设置随机数的生成方式,‘default’可以生成相同的随机数 15 figure(1) 16 gscatter(bank.balance,bank.duration,bank.y,'kk','xo') 17 set(gca,'linewidth',2); 18 X = table2array(varfun(@double,bank(:,1:end-1)));%预测变量 19 Y = bank.y; 20 disp('数据中YES&No的统计结果'); 21 tabulate(Y) %求重复数字的个数使用tabulate,占比率 22 Xnum = [X(:,~catPred) dummyvar(X(:,catPred))]; 23 Ynum = double(Y)-1; 24 25 %%%设置交叉验证方式 26 cv = cvpartition(height(bank),'holdout',0.40); 27 Xtrain = X(training(cv),:); 28 Ytrain = Y(training(cv),:); 29 XtrainNum = Xnum(training(cv),:); 30 YtrainNum = Ynum(training(cv),:); 31 Xtest = X(test(cv),:); 32 Ytest = Y(test(cv),:); 33 XtestNum = Xnum(test(cv),:); 34 YtestNum = Ynum(test(cv),:); 35 disp('训练集'); 36 tabulate(Ytrain); 37 disp('测试集'); 38 tabulate(Ytest); 39 40 %%%训练K-NN分类器 41 knn = ClassificationKNN.fit(Xtrain,Ytrain,'Distance','seuclidean','NumNeighbors',5); 42 %进行预测 43 [Y_knn,Yscore_knn] = knn.predict(Xtest); 44 Yscore_knn = Yscore_knn(:,2); 45 %计算混淆矩阵 46 disp('最近邻方法分类结果:'); 47 C_knn = confusionmat(Ytest,Y_knn)
2.题中有关函数用法简介:
【1】varfun函数:
语法:
1)B = varfun(func,A) 分别向表或时间表 A 的每个变量应用函数 func,并在表或时间表 B 中返回值。
函数 func 必须取一个输入参数,并在每次调用时返回行数相同的数组。输出参数中的第 i 个变量 B{:,i} 等于 func(A{:,i})。
如果 A 是时间表,而 func 跨多个行组聚合数据,则 varfun 将 A 中每个行组的第一个行时间指定为 B 中对应的行时间。要以表的形式返回 B 而不带行时间,请将 'OutputFormat' 指定为 'table'。
2)B = varfun(func,A,Name,Value) 通过一个或多个 Name,Value 对组参数指定的其他选项,分别向表或时间表 A 的每个变量应用函数 func。
例如,您可以指定要传递给该函数的变量。
参数说明:
1)= varfun(func,A,Name,Value),'OutputFormat' - B 的格式:'table' (默认) | 'timetable' | 'uniform' | 'cell';若想返回数值向量而非表则可输入B = varfun(func,A,'OutputFormat','uniform')。B = varfun(func,A,'GroupingVariables','Var1')表示将A中“Var1”变量进行分组(统计个数),会有单独一列进行显示,再将func函数(同一类别)计算出的值列出。
【2】categorical函数:
函数说明:
categorical 是为一组有限的离散类别(例如 High、Med 和 Low)赋值的数据类型。这些类别可以采用您指定的数学排序,例如 High > Med > Low,但这并非必须。分类数组可用来有效地存储并方便地处理非数值数据,同时还为数值赋予有意义的名称。分类数组的常见用法是用来指定构成表的各组行。
语法:
B = categorical(A)B = categorical(A,valueset)B = categorical(A,valueset,catnames)B = categorical(A,___,Name,Value)转换数组并按类别选择数据
创建一个包含气象站标签的分类数组。将其添加到温度读数表中。然后使用类别按气象站选择温度读数。
首先,创建包含温度读数、日期和气象站标签的数组。
Temps = [58; 72; 56; 90; 76];
Dates = {'2017-04-17';'2017-04-18';'2017-04-30';'2017-05-01';'2017-04-27'};
Stations = {'S1';'S2';'S1';'S3';'S2'};
将 Stations 转换为分类数组。
Stations = categorical(Stations)
Stations = 5x1 categorical array
S1
S2
S1
S3
S2
显示类别。三个气象站标签为类别。
categories(Stations)
ans = 3x1 cell array
{'S1'}
{'S2'}
{'S3'}
创建包含温度、日期和气象站标签的表。
T = table(Temps,Dates,Stations)
T=5x3 table
Temps Dates Stations
_____ ____________ ________
58 '2017-04-17' S1
72 '2017-04-18' S2
56 '2017-04-30' S1
90 '2017-05-01' S3
76 '2017-04-27' S2
显示从气象站 S2 获得的读数。您可以使用 == 运算符找出等于 S2 的 Station 的值。然后使用逻辑索引选择包含气象站 S2 的数据的表行。
TF = (T.Stations == 'S2');
T(TF,:)
ans=2x3 table
Temps Dates Stations
_____ ____________ ________
72 '2017-04-18' S2
76 '2017-04-27' S2
【3】discretize函数(本题未用到):将数据分组到 bin 或类别中
例如:使用 discretize 函数(而不是 categorical)将 100 个随机数划分为三个类别。
x = rand(100,1);
y = discretize(x,[0 .25 .75 1],'categorical',{'small','medium','large'});
summary(y)
运行结果是:
small 22
medium 46
large 32
【4】rng随机数生成设置函数:
rng(seed) 使用非负整数 seed 为随机数生成函数提供种子,以使 rand、randi 和 randn 生成可预测的数字序列。
rng('shuffle') 根据当前时间为随机数生成函数提供种子。这样,rand、randi 和 randn 会在您每次调用 rng 时生成不同的数字序列。
rng(seed, generator) 和 rng('shuffle', generator) 另外指定 rand、randi 和 randn 使用的随机数生成函数的类型。generator 输入为以下项之一:
'twister':Mersenne Twister
'simdTwister':面向 SIMD 的快速 Mersenne Twister 算法
'combRecursive':合并的多个递归
'multFibonacci':乘法滞后 Fibonacci
'v5uniform':传统 MATLAB® 5.0 均匀生成函数
'v5normal':传统 MATLAB 5.0 正常生成函数
'v4':传统 MATLAB 4.0 生成函数
rng('default') 将 rand、randi 和 randn 使用的随机数生成函数的设置重置为其默认值。这样,会生成相同的随机数,就好像您重新启动了 MATLAB。默认设置是种子为 0 的 Mersenne Twister。
scurr = rng 返回 rand、randi 和 randn 使用的随机数生成函数的当前设置。这些设置将在包含字段 'Type'、'Seed' 和 'State' 的结构体 scurr 中返回。
rng(s) 将 rand、randi 和 randn 使用的随机数生成函数的设置还原回之前用 s = rng 等命令捕获的值。
sprev = rng(...) 返回 rand、randi 和 randn 使用的随机数生成函数的以前设置,然后更改这些设置。
【5】tabulate函数;
可以计算函数的个数以及在数组或矩阵中的占比率.
例如;
test = [1 2 3 3 3 5 4 1 2];
tabulate(test);
运行结果:
Value Count Percent
1 2 22.22%
2 2 22.22%
3 3 33.33%
4 1 11.11%
5 1 11.11%
test = [{'a'},{'aaa'},{'a'}];
tabulate(test)
运行结果:
Value Count Percent
a 2 66.67%
aaa 1 33.33%
