深度学习之AdaGrad算法
AdaGrad 算法根据自变量在每个维度的梯度值调整各个维度的学习率,从而避免统一的维度难以适应所有维度的问题。
特点:
-
小批量随机梯度按元素累加变量,出现在学习率的分母项中。(若目标函数有关自变量的偏导数一直都较大,那么学习率下降较快;反之亦然。)
-
若迭代早期下降过快 + 当前解仍然不佳,可能导致很难找到有效解。
一、算法初解
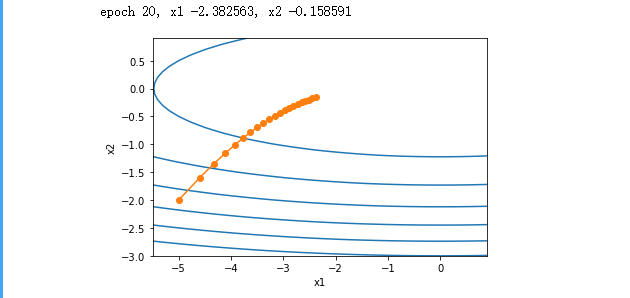
实现AdaGrad算法,使⽤的学习率为0.4。输出的⾃变量的迭代轨迹较平滑。但由
于累加效果使学习率不断衰减,⾃变量在迭代后期的移动幅度较⼩。
%matplotlib inline
import math
import torch
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
def adagrad_2d(x1, x2, s1, s2):
g1, g2, eps = 0.2 * x1, 4 * x2, 1e-6
s1 += g1 ** 2
s2 += g2 ** 2
x1 -= eta /math.sqrt(s1 + eps) * g1
x2 -= eta / math.sqrt(s2 + eps) * g2
return x1, x2, s1, s2
def f_2d(x1, x2):
return 0.1 * x1 **2 + 2 *x2 ** 2
eta = 0.4
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))
运行结果:
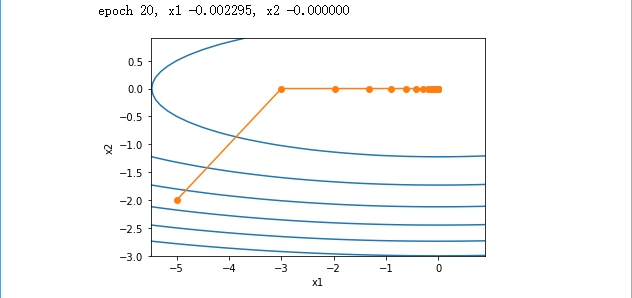
将学习率增⼤到2。可以看到⾃变量更为迅速地逼近了最优解
eta = 2
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))
运行结果:
二、从零开始实现
同动量法⼀样,AdaGrad算法需要对每个⾃变量维护同它⼀样形状的状态变量。下面根据AdaGrad算
法中的公式实现该算法。
# 从零开始实现
%matplotlib inline
import math
import torch
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
features, labels = d2l.get_data_ch7()
def init_adagrad_states():
s_w = torch.zeros((features.shape[1], 1), dtype=torch.float32)
s_b = torch.zeros(1, dtype=torch.float32)
return (s_w, s_b)
def adagrad(params, states, hyperparams):
eps = 1e-6
for p, s in zip(params, states):
s.data += (p.grad.data**2)
p.data -= hyperparams['lr'] * p.grad.data / torch.sqrt(s + eps)
d2l.train_ch7(adagrad, init_adagrad_states(), {'lr' : 0.1},features,labels)
运行结果:

三、出现的运行错误
错误代码OSError: ../../data/airfoil_self_noise.dat not found.找不到文件:

在这个网站下载"airfoil_self_noise.dat",将其放入这个路径中“ ../../data/airfoil_self_noise.dat”。即可运行成功。


