第四次作业
作业一
1)爬取当当网站图书数据
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
- 代码:
- MySpider.py:
-
import scrapy
from DangDang.items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MydangdangSpider(scrapy.Spider):
name = 'mydangdang'
key = '1984 '
source_url = 'http://search.dangdang.com/'
def start_requests(self):
url = MydangdangSpider.source_url + "?key="+MydangdangSpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
list = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in list:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
yield item
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
passpinelines.py:
-
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
if self.opened:
self.cursor.execute("insert into books (Title,Author,Publisher,Date,Price,Detail) values( % s, % s, % s, % s, % s, % s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
except Exception as err:
print(err)
return itemitems.py:
-
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author=scrapy.Field()
date=scrapy.Field()
publisher=scrapy.Field()
price=scrapy.Field()
结果:
![]()
- 感想:这个作业主要是照着这份书上的代码来复现的。但我在安装SQL数据库上出了问题,MySQL只能使用自带的workbench打开,而MSSQL2019干脆安装失败了,最后只能把MSSQL 2008搬出来才解决了这次作业......
-
作业二
1)爬取股票相关信息
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
-
- 代码:
- items.py:
-
import scrapy
class StockcrawItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
num_key = scrapy.Field()
name_key = scrapy.Field()
price_key = scrapy.Field()
change_rate_key = scrapy.Field()
change_amount_key = scrapy.Field()
turning_key = scrapy.Field()
passpipelines.py
-
import pymysql
class StockcrawPipeline:
def open_spider(self, myspiders):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="password", db="testforcraw",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from cmb")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into stock(num_key, name_key, price_key, change_rate_key, change_amount_key, volume_key)"
"values( % s, % s, % s, % s, % s, % s)",
(item["num_key"], item["name_key"], item["price_key"], item["change_rate_key"], item["change_amount_key"], item["turning_key "]))
except Exception as err:
print(err)
return item -
MySpider.py
-
from scrapy import Request
import scrapy
from urllib.parse import quote
from bs4 import BeautifulSoup
from ..items import StockcrawItem
from selenium import webdriver
from bs4 import UnicodeDammit
class StockSpider(scrapy.Spider):
name = 'stock'
start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
driver1 = webdriver.Chrome()
# [num_key, name_key, price_key, change_rate_key, change_amount_key, turning_key ]
def parse(self, response):
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
tr_list = selector.xpath("//tr[@class]")
for td in tr_list:
num_key = td.xpath("./td[2]/a[1]/text()").extract_first()
name_key = td.xpath("./td[3]/a[1]/text()").extract_first()
price_key = td.xpath("./td[5]/span[1]/text()").extract_first()
change_rate_key = td.xpath("./td[6]/span[1]/text()").extract_first()
change_amount_key = td.xpath("./td[7]/span[1]/text()").extract_first()
turning_key = td.xpath("./td[8]/text()").extract_first()
# print(num_key, name_key, price_key, change_rate_key, change_amount_key, volume_key)
item = StockcrawItem()
item["num_key"] = num_key
item["name_key"] = name_key
item["price_key"] = price_key
item["change_rate_key"] = change_rate_key
item["change_amount_key"] = change_amount_key
item["turning_key "] = turning_key
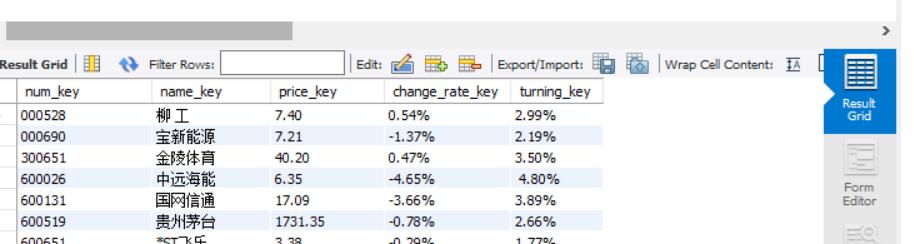
yield item - 结果:
![]()
- 感想:实事求是的讲,这一次的实践作业并不算太难,如果能把之前几个知识点融会贯通的话做起来还是比较快的,其他同学反映的数据库会对num_key自动排号的问题也没有出现。(就是为什么我只是搜索了几个股票网站就会接到推荐股票的电话?孩子怕了)
-
作业三
-
爬取外汇网站数据。
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
items.pyimport scrapy class ExchangeItem(scrapy.Item): count=scrapy.Field() Currency=scrapy.Field() TSP=scrapy.Field() CSP=scrapy.Field() TBP=scrapy.Field() CBP=scrapy.Field() Time=scrapy.Field()
MySpider.py
-
import scrapy from exchange.items import ExchangeItem class mySpider(scrapy.Spider): name = "mySpider" count=0 def start_requests(self): url="http://fx.cmbchina.com/hq/" yield scrapy.Request(url=url,callback=self.parse) def parse(self, response, **kwargs): item=ExchangeItem() data=response.body.decode() selector=scrapy.Selector(text=data) start_text=selector.xpath("//div[@id='realRateInfo']/table[@align='center']/tr") for text in start_text[1:]: self.count+=1 item["count"]=self.count item["Currency"]=text.xpath("./td[1]/text()").extract_first().strip() item["TSP"]=text.xpath("./td[4]/text()").extract_first().strip() item["CSP"] = text.xpath("./td[5]/text()").extract_first().strip() item["TBP"] = text.xpath("./td[6]/text()").extract_first().strip() item["CBP"] = text.xpath("./td[7]/text()").extract_first().strip() item["Time"] = text.xpath("./td[8]/text()").extract_first().strip() yield item
pipelines.py
-
import pymysql class ExchangePipeline: connect=pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", charset="utf8",db="mydb") cursor=connect.cursor() sql="""create table exchange(Id int,Currency varchar(64),TSP varchar(64),CSP varchar(64),TBP varchar(64), CBP varchar(64),Time varchar(64))ENGINE=InnoDB DEFAULT CHARSET=utf8""" cursor.execute(sql) def process_item(self, item, spider): try: self.cursor.execute("insert into exchange values(%s,%s,%s,%s,%s,%s,%s)", (item["count"],item["Currency"],item["TSP"],item["CSP"],item["TBP"], item["CBP"],item["Time"])) self.connect.commit() except Exception as err: print(err) return item
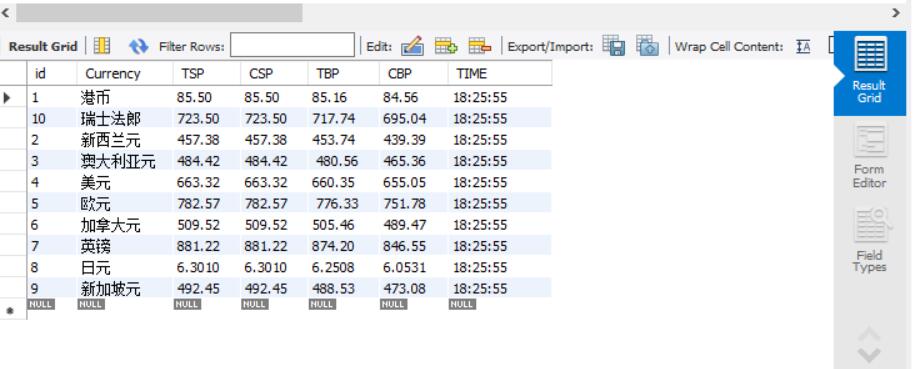
结果:
![]()
- 感想:和前两个作业差不多,如果可以做好HTML标签定位的话也不会太难。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号