第一次作业——结合三次小作业
作业①:UniversityRanking
1)要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
2)代码:
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp = urllib.request.urlopen(url) #打开URL
data = resp.read() #读取URL内容
html = data.decode() #对网页内容解码,转为字符串
soup = BeautifulSoup(html,"html.parser") #使用beautifulsoup库解析
university=soup.select("a[href$='university']")
print("排名\t\t学校名称\t\t省市\t\t学校类型\t总分") #打印表头
for table in university:
tag=table.parent #这是表的主码
tank=tag.previous_sibling
area=tag.next_sibling
type=area.next_sibling
result=type.next_sibling
print(tank.text.strip()+"\t\t"+tag.text.strip()+"\t\t"+area.text.strip()+"\t\t"+type.text.strip()+"\t\t"+result.text.strip())
#if(len(tag)>=8):
#print(tank.text.strip()+"\t\t"+tag.text.strip()+"\t"+area.text.strip()+"\t\t"+type.text.strip()+"\t\t"+result.text.strip())
#else:
#print(tank.text.strip()+"\t\t"+tag.text.strip()+"\t\t"+area.text.strip()+"\t\t"+type.text.strip()+"\t\t"+result.text.strip())
#本来是打算调节一下间距的,但好像没用
3)结果
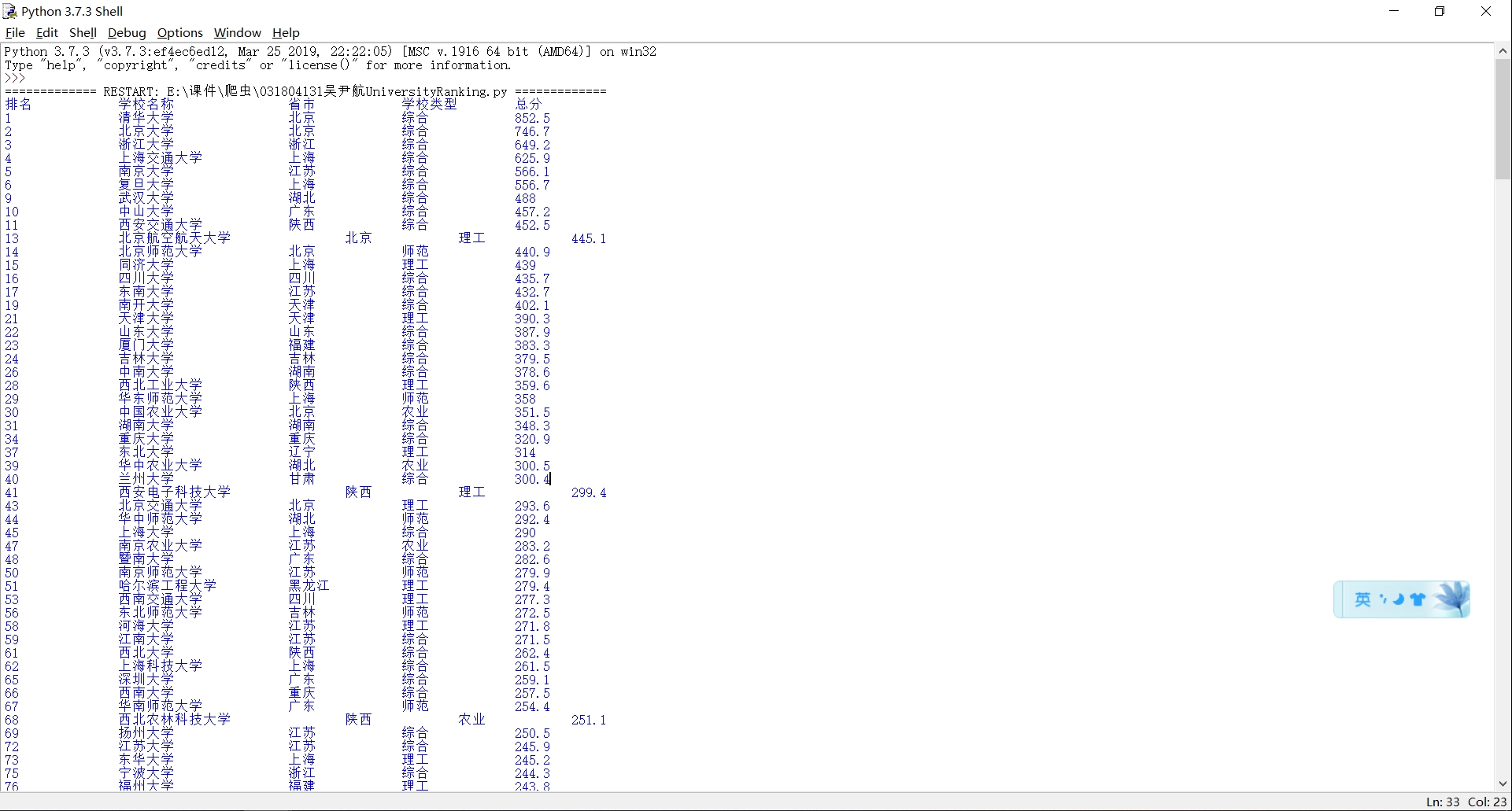
4)心得
1.初步了解了爬取网页的大致流程
2.学习了HTML网页架构
3.学习了beautifulsoup库,urllib.request方法的使用
作业②:
1)要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
2)代码:
import requests
from bs4 import BeautifulSoup
def getHTMLText(url): #获得网页内容
header = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} #伪装成浏览器的头部,然而京东似乎并没有对爬虫作出限制
html = requests.get(url, headers=header)
html.encoding = html.apparent_encoding #作用是把编码方式改为UTF-8
return html.text
def getList(html): #给出列表
if html=='':
print('页面不存在')
else:
dict = {} #要先声明dict是个列表
soup = BeautifulSoup(html, 'html.parser')
for i in range(20):
info = soup.find_all('div',attrs={'class':"gl-i-wrap"})[i]
price = info.find_all('div',attrs={'class':"p-price"})[0]
name = info.find_all('div',attrs={'class':"p-name p-name-type-2"})[0]
valuelist = price.find_all('i')
keylist = name.find_all('em')
for i in range(len(keylist)):
key = keylist[i].text
val = valuelist[i].text
dict[key] = val
return dict
#我没有写try...catch,毕竟这不是一个正式的应用程序,有错直接报就行
#words = '蓝牙耳机'
stocklist = 'https://search.jd.com/Search?keyword=%E8%93%9D%E7%89%99%E8%80%B3%E6%9C%BA&enc=utf-8&wq=%E8%93%9D%E7%89%99%E8%80%B3%E6%9C%BA&pvid=1d21c1acf22a4472a48abe678343b213'
url = stocklist
#url = stocklist + words #看网上示例要加上words......但我没看明白,删掉也没有出问题
html = getHTMLText(url)
dict1 = getList(html)
title = "{:4}\t{:20}\t{:4}\t"
print(title.format("序号", "商品名称", '价格')) #更为合理的输出format,不然会挤成一团
count = 0
for n in dict1:
count = count + 1
print(title.format(count, n, dict1[g]))
3)结果
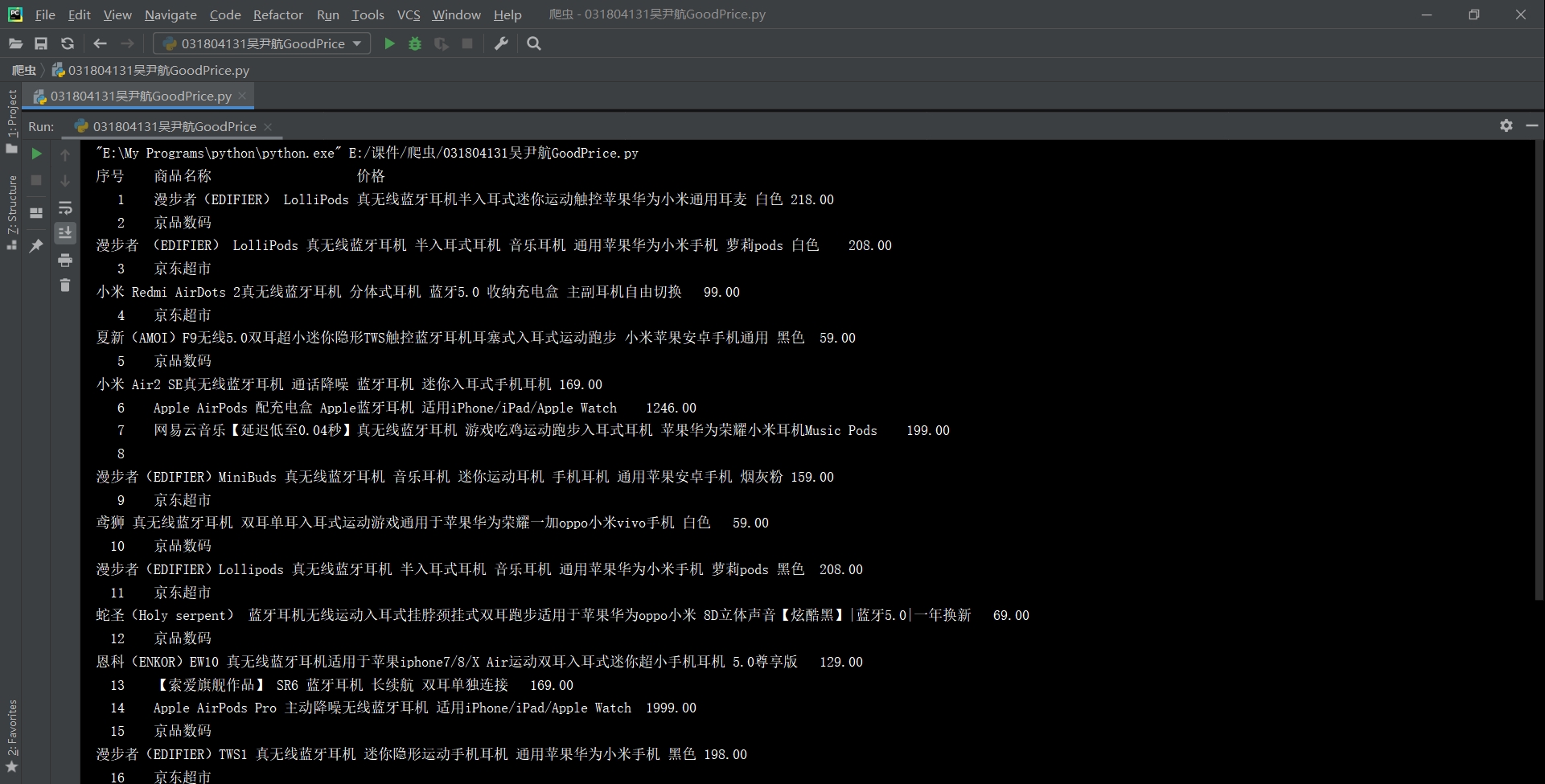
4)心得
1.加深了对HTML网页架构的了解
2.尝试了apparent_encoding方法
3.加深了对header方法的理解
作业③:
1)要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
2)代码:
import re
from bs4 import BeautifulSoup
import urllib.request
url = "http://xcb.fzu.edu.cn/"
def getHTML(url):
if url == '':
print('页面不存在')
else:
resp = urllib.request.urlopen(url)
data = resp.read()
return data.decode()
soup = BeautifulSoup(html,'html.parser')
flag = soup.find_all("img", attrs={"src": re.compile('jpg')}) #使用compile编译为字节代码对象
return flag
def getJPG(tags):
jpg = []
name = []
for image in tags:
src = image.get("src") #此处要声明好src类型,否则会一直报错AttributeError: 'str' object has no attribute 'get'
n = re.search("\w+\.", src)
name.append(src[n.start():n.end()] + "jpg")
jpg.append(src)
return jpg, name
def save(path, jpg, name):
i = 0
for i in range(len(jpg)):
urllib.request.urlretrieve(jpg[i], path + '/' + name[i]) #urlretrieve方法直接将远程数据下载到本地
save_path = r"picture"
tags = getHTML(url)
jpg,name = getJPG(tags)
save(save_path, jpg, name)
3)结果
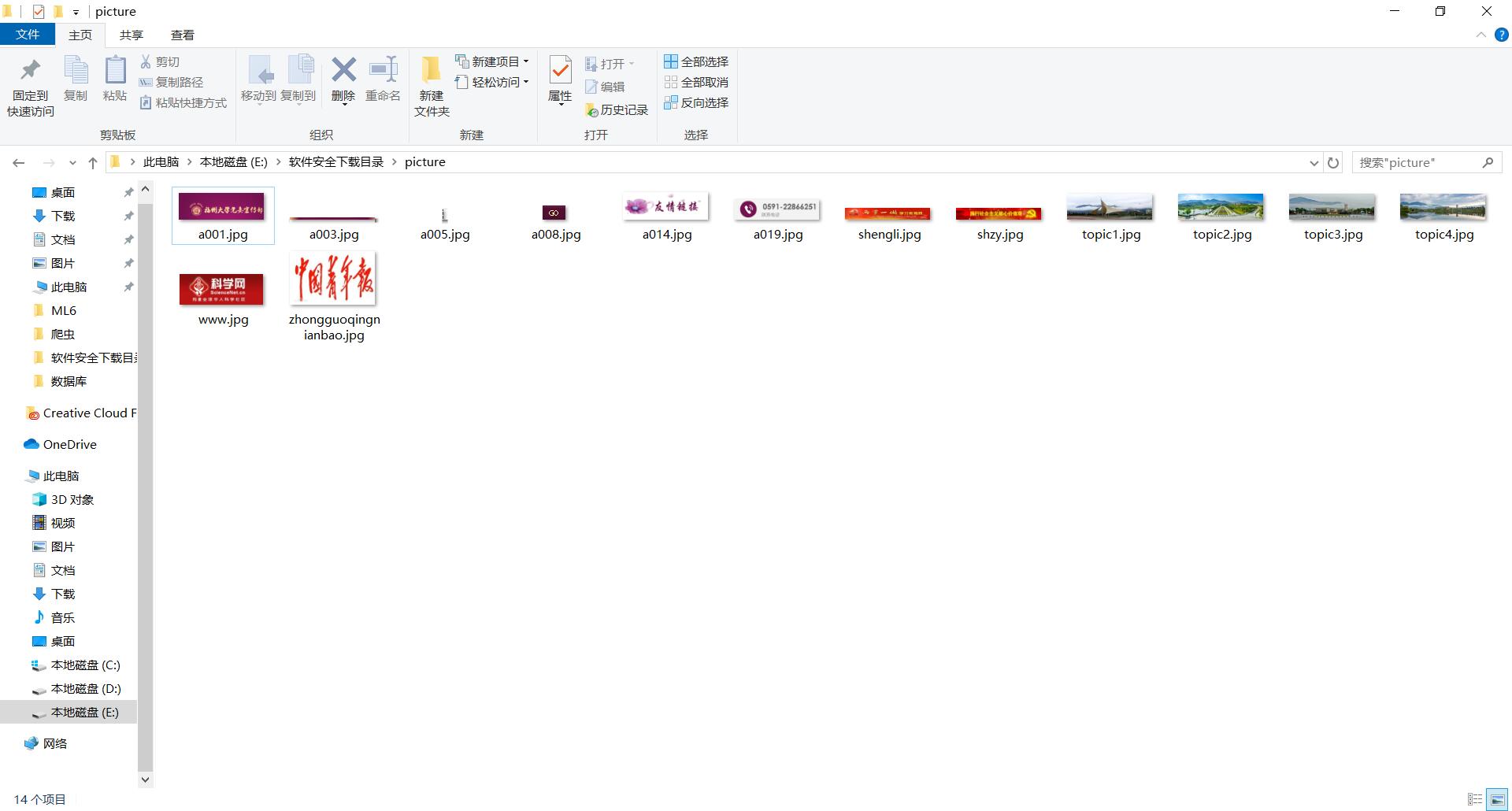
4)心得
1.加深了对了re库、append函数、urllib.request.urlretrieve方法的应用
2.进一步学习了HTML网页源代码的结构
3.重新学习了如何在本地存储文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号