第一次个人编程作业
一、GitHub链接GitHub
二、计算模块接口的设计与实现
1.流程图
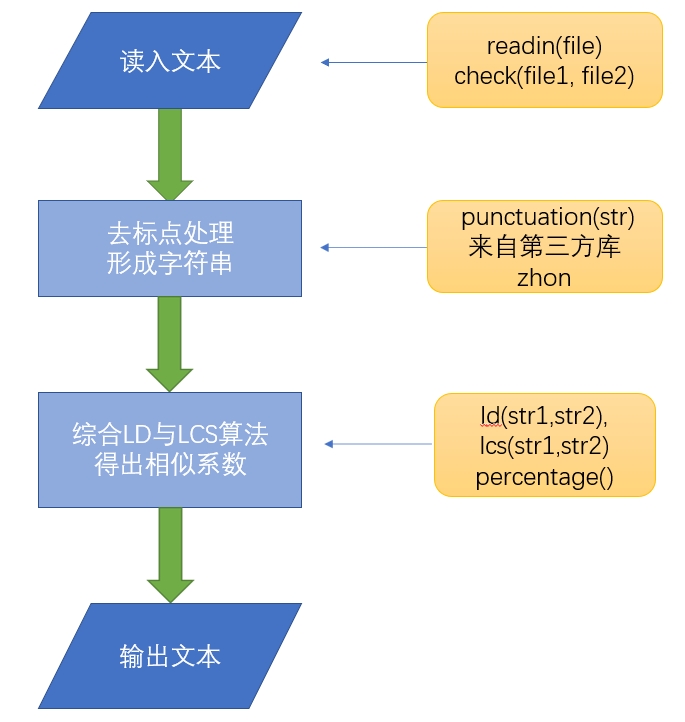
2.核心算法
在设计核心的比较算法时,一开始我曾经有过两种不同的思考方向:一是使用jieba库对文本去标点+分词后运用gensim库将文本视作一个巨大的稀疏向量,求出其向量余弦;二是在去标点后直接比较字符串,通过设计出一个能得到字符串相似比率的算法求出查重率。
初步试验后,我先放弃了稀疏向量求向量余弦法:这一方法显然不适用于处理长文本,在全文测试中向量余弦基本接近0.99(请注意:这只是我早期测试的结果,不排除我测试出错的可能性;已经有相当一部分同学对向量余弦法进行了改良并取得了不错的成果);而在研究后者的过程中,我发现了两种相对有效的基础算法:LD算法和LCS算法。
LD算法(编辑距离算法),是以字符串A通过插入字符、删除字符、替换字符变成另一个字符串B,那么操作的过程的次数表示两个字符串的差异。
对于1≤i≤N,1≤j≤M,
若ai=bj,则LCS(i,j)=LCS(i-1,j-1)+1
若ai≠bj,则LD(i,j)=Min(LD(i-1,j-1),LD(i-1,j),LD(i,j-1))+1
LCS算法(最长公共子串算法),LCS(A,B)表示字符串A和字符串B的最长公共子串的长度。最长公共子串不需要连续出现,但一定是出现的顺序一致。
对于1≤i≤N,1≤j≤M
若ai=bj,则LCS(i,j)=LCS(i-1,j-1)+1
若ai≠bj,则LCS(i,j)=Max(LCS(i-1,j-1),LCS(i-1,j),LCS(i,j-1))
这两种算法各有利弊:LD算法能够比较好的处理实例中增加、删除变换两种情况,而LCS算法则更适合处理实例中乱序、移动变换的情况。
那么,是否有办法在这两种算法中各取所长呢?
我找到了这个
S(A,B)=LCS(A,B)/(LD(A,B)+LCS(A,B))
LD(A,B)+LCS(A,B)表示两个字符串A、B的唯一最佳匹配字串的长度,使得S(A,B)=S(B,A);且S(A,B)作为查重率时会稳定在一个相对合理的比率内,就是它了!
3.使用的Python库
汉字文本处理库zhon(ver1.1.5)
python内置模块re和sys
三、计算模块接口部分的性能分析
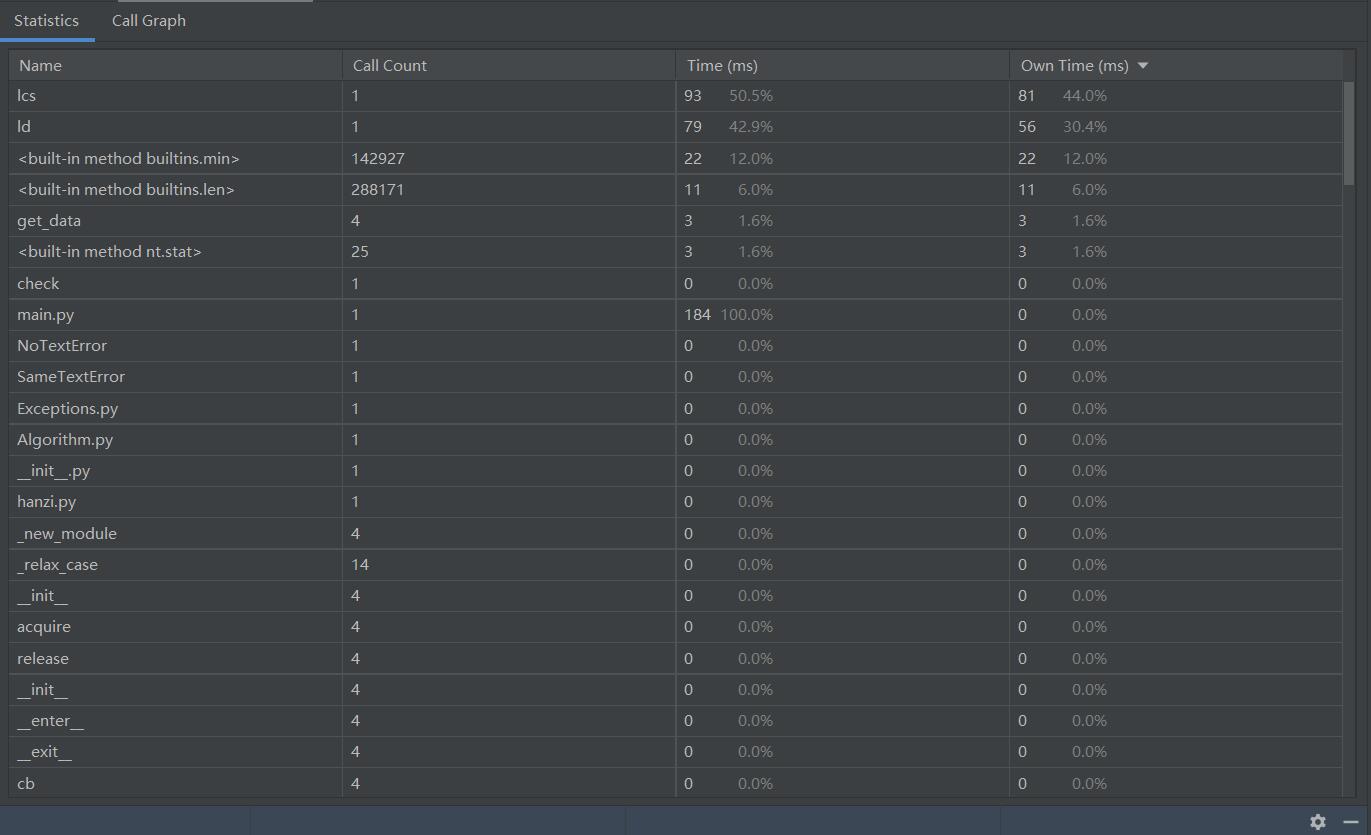
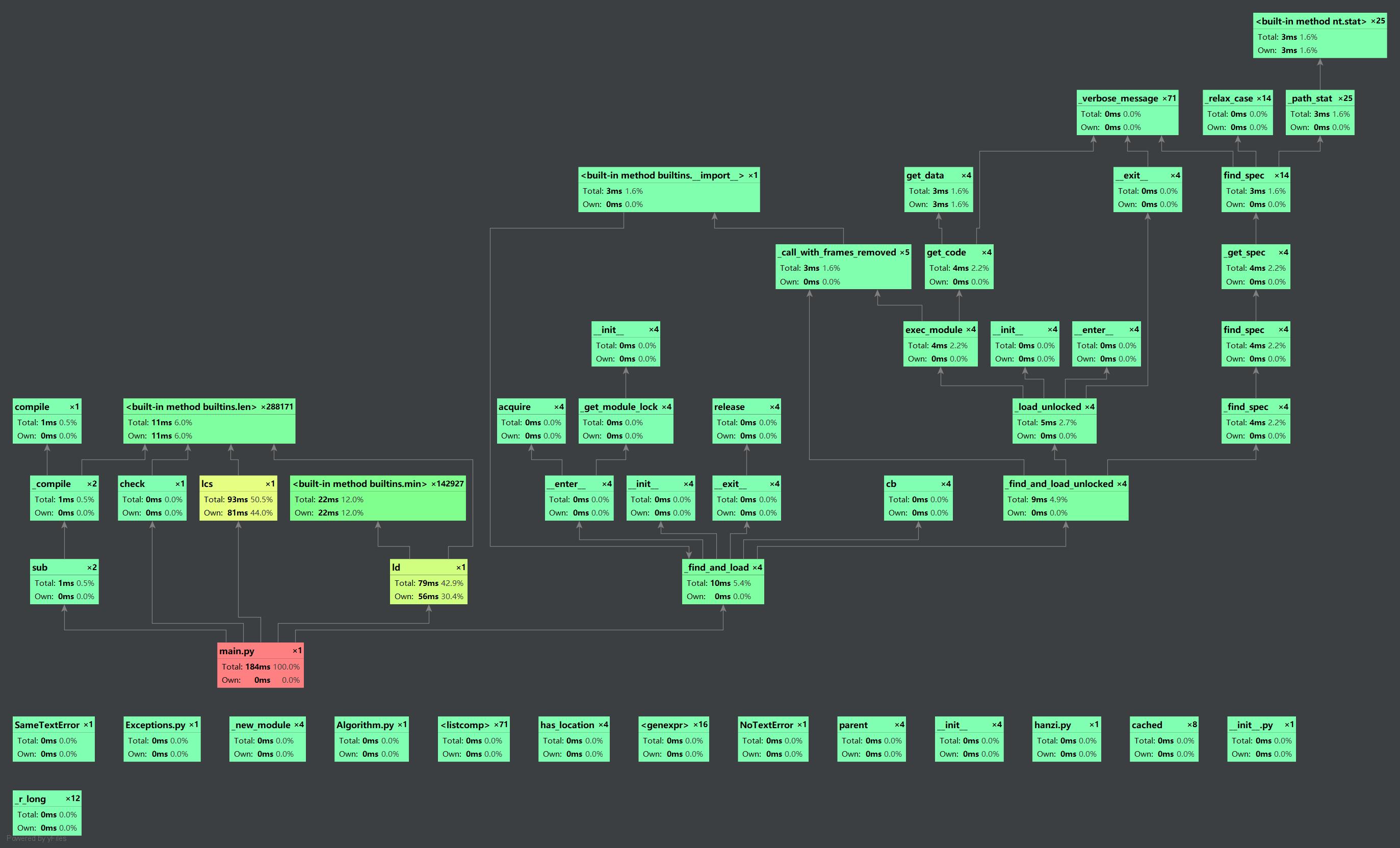
这是使用了pycharm内置的profile进行测试。
请注意:由于pycharm不支持直接调用argv参数,所以这一结果是我将路径直接导入代码中测试的,实际消耗时间应当更多
目前没有优化思路,抱歉
四、计算模块部分单元测试
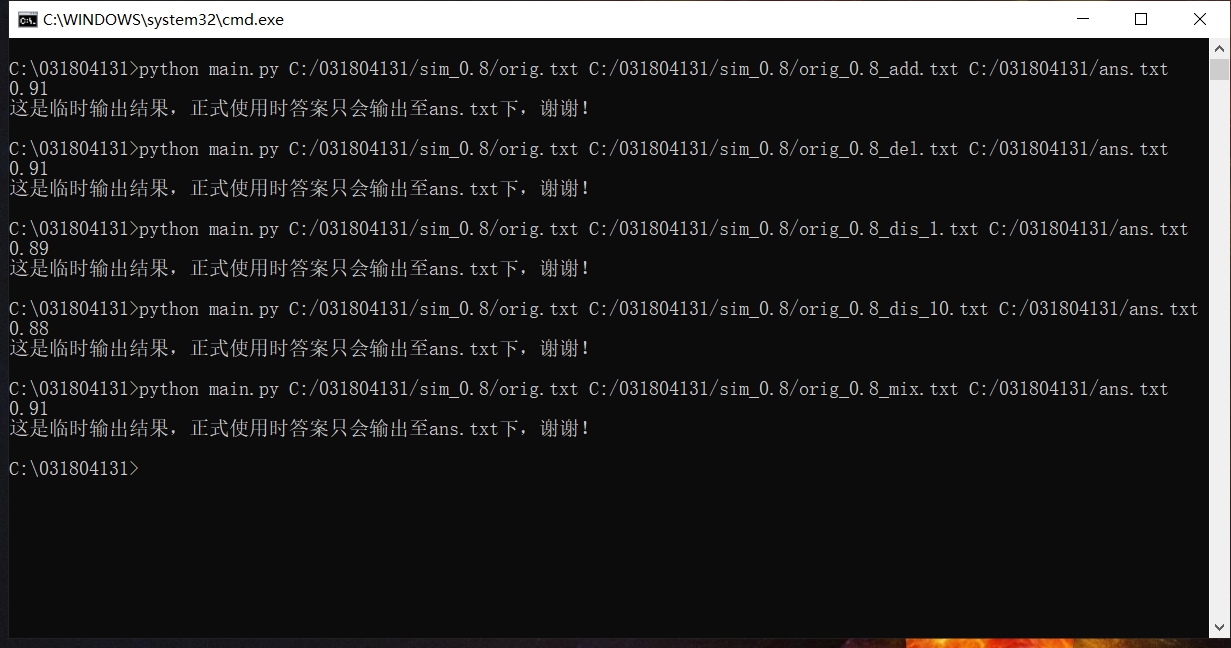
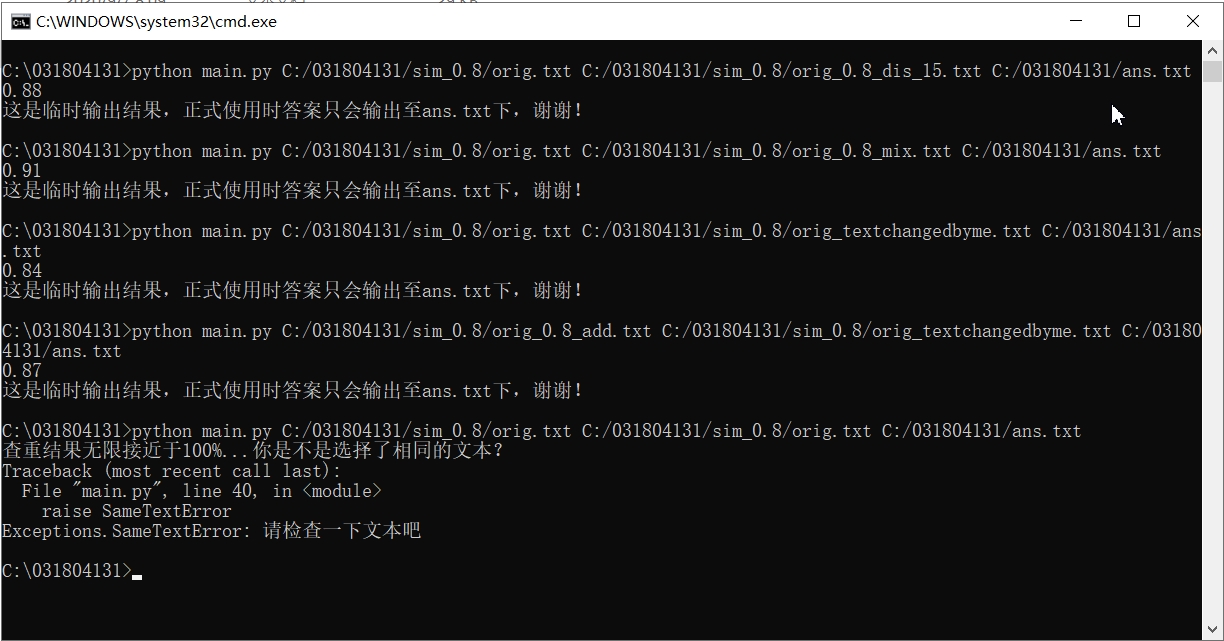
(其中的orig_textchangedbyme是我自己拼接的一个文本)
五、模块部分异常处理说明
模块异常我主要设计了两种:导入空白文本和导入相同文本
`class NoTextError(Exception):
def __init__(self):
print("你载入了一个空文本...?")
def __str__(self, *arg1, **arg2):
return "请检查一下文本吧" # 为什么要加这个Exception?因为我在测试阶段真的犯过这种错`
`class SameTextError(Exception):
def __init__(self):
print("查重结果无限接近于100%...你是不是选择了相同的文本?")
def __str__(self, *arg1, **arg2):
return "请检查一下文本吧"`
六、PSP表格
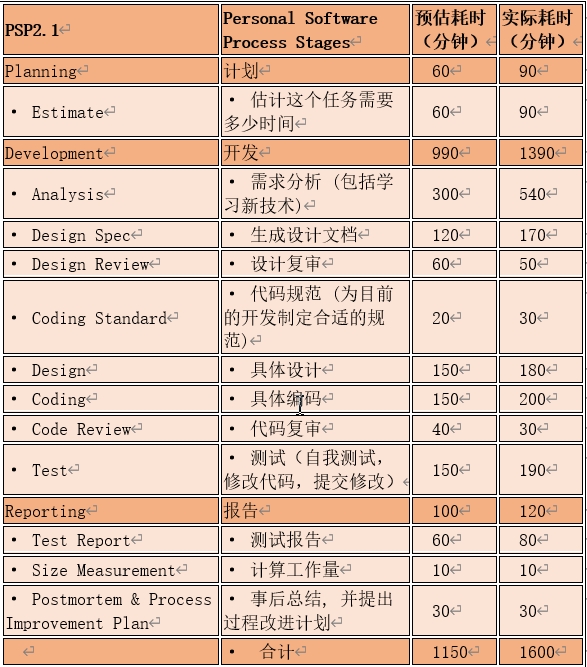
等到真正做下来我才发现原来我这么菜
七、总结&吐槽
从第一天做到了最后一天,大部分时间不是花在具体项目而是耗费在了各种自学上,现在心里感慨万分。
但是,这也是我第一次独立完成一个小型项目,第一次往GitHub上上传东西,第一次走完了软工设计的几乎全部流程......这都是很有意义的一次体验。
无论最后这个项目能得几分,我都已经比较满意了(有BUG另说),期待之后的结对作业和团队作业去抱dalao的大腿吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号