Spark Application、Driver、Job、stage、task
1、Application
application(应用)其实就是用spark-submit提交的程序。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储。
2、Driver
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。通俗讲,driver可以理解为用户自己编写的程序。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程.
Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(常用的如 yarn)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
3、Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4、Stage
stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。Spark的Stage是分割RDD执行的各种transformation而来。分割Stage的规则,其实只有一个:从宽依赖处分割。
RDD被设计为可以记录依赖关系,关系可以分为两类:窄依赖和宽依赖。窄依赖:表示父亲 RDD 的一个分区最多被子 RDD 一个分区所依赖。宽依赖:表示父亲 RDD 的一个分区可以被子 RDD 的多个子分区所依赖。如下图,左边是窄依赖,右边是宽依赖:
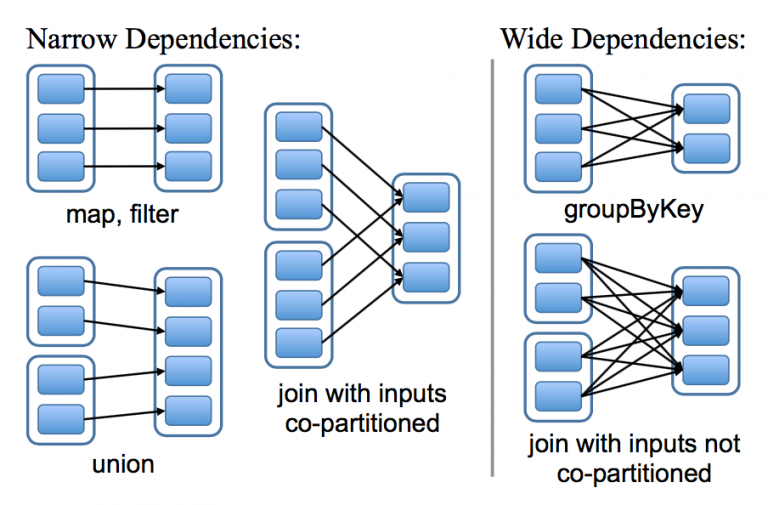
知道了这个分割规则,其实还是有一点疑惑,为什么这么分?
其实道理蛮明显的,子RDD的partition会依赖父RDD中多个partition,这样就可能会有一些partition没有准备好,导致计算不能继续,所以就分开了,直到准备好了父RDD中所有partition,再继续进行将父RDD转换为子RDD的计算。而窄依赖完全不会有这个顾虑,窄依赖是父RDD一个partition对应子RDD一个partition,那么直接计算就可以了。
4、Task
一个Stage内,最终的RDD有多少个partition,就会产生多少个task。一般情况下,我们一个task运行的时候,使用一个cores。task的数量就是我们任务的最大的并行度。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
如果我们的task数量超过cores总数,则先执行cores个数量的task,然后等待cpu资源空闲后,继续执行剩下的task。
参考:https://www.cnblogs.com/wzj4858/p/8204411.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号