Alertmanager高可用
Alertmanager高可用
日常部署alertmanager组件的时候,都是用的单点架构,架构图如下所示:
那么显然这样是存在单点故障的,另外对运维而言,其实单点故障是很可怕的,收不到报警有时候是致命的,所以要用高可用的报警方式:
alertmanager的高可用方式有两种方法,都是很好的解决方案,第一种就是引入负载均衡,通过负载均衡的方法保证服务可用,架构如下:
这种方式可以实现高可用 并且可以灵活扩展,云服务的话一般都有负载均衡。
今天主要介绍官方提供的集群方法,架构如下:
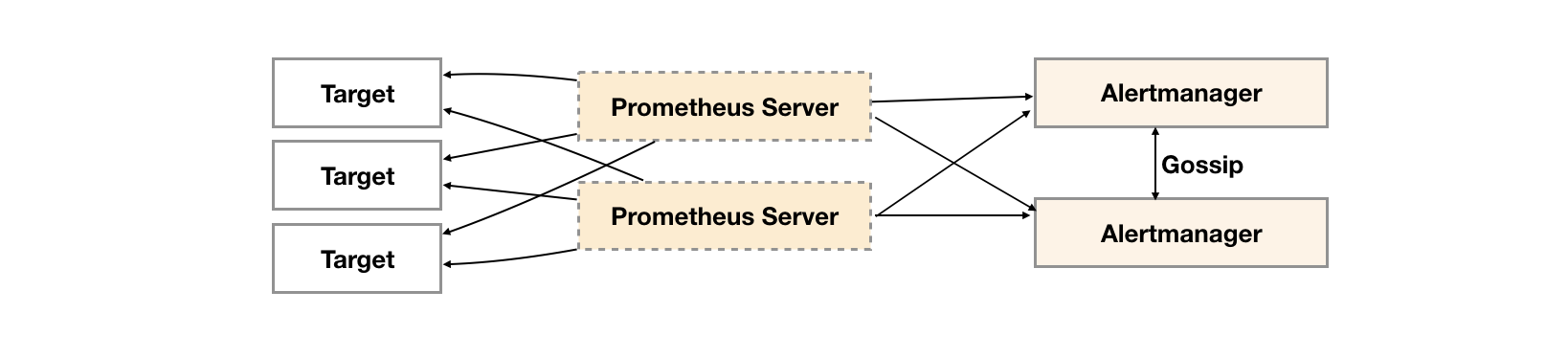
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
集群环境搭建
为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
--cluster.listen-address string: 当前实例集群服务监听地址
--cluster.peer value: 初始化时关联的其它实例的集群服务地址
现在准备一台机器部署Alertmanager集群
机器:
192.168.50.58
这里我为了节约资源 在一台机器启三个实例。
生产环境不建议都装在一台机器
定义Alertmanager实例01,其中Alertmanager的服务运行在9093端口,集群服务地址运行在8001端口。
定义Alertmanager实例02,其中主服务运行在9094端口,集群服务运行在8002端口。
定义Alertmanager实例03,其中主服务运行在9095端口,集群服务运行在8002端口。为了将01,02,03组成集群
02 03 启动时需要定义—cluster.peer参数并且指向01实例的集群服务地址:8001。
| 实例 | 集群端口 | 服务端口 |
|---|---|---|
| Alertmanager-01 | 8001 | 9093 |
| Alertmanager-02 | 8002 | 9094 |
| Alertmanager-03 | 8003 | 9095 |
[root@alert-manager-dev-1 src]# cd alertmanager
[root@alert-manager-dev-1 alertmanager]# ls
alert1.log alert2.log alert3.log alertmanager alertmanager.yml amtool data LICENSE NOTICE
[root@alert-manager-dev-1 alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'ww10e9ec08a926549b' #企业ID
#to_user: '' #userid
to_user: '' #组id
agent_id: '' #agentid
api_secret: '' #生成的secret
send_resolved: true
- name: 'web.hook'
webhook_configs:
- url: 'http://192.168.50.58:5000/webhook'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
启动实例01:
nohup ./alertmanager --web.listen-address=":9093" --cluster.listen-address="127.0.0.1:8001" --config.file="alertmanager.yml" --log.level=debug 2>&1 > alert1.log &
启动实例02:
nohup ./alertmanager --web.listen-address=":9094" --cluster.listen-address="127.0.0.1:8002" --cluster.peer=127.0.0.1:8001 --config.file="alertmanager.yml" --storage.path=/data/0994/ --log.level=debug 2>&1 > alert2.log
启动实例03:
nohup ./alertmanager --web.listen-address=":9095" --cluster.listen-address="127.0.0.1:8003" --cluster.peer=127.0.0.1:8001 --config.file="alertmanager.yml" --storage.path=/data/9095/ --log.level=debug 2>&1 > alert3.log &
修改Prometheus.yaml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.50.58:9093
- 192.168.50.58:9094
- 192.168.50.58:9095
重新加载Prometheus
curl -X POST http://localhost:9090/-/reload
完成后访问任意Alertmanager节点http://localhost:9093/#/status,可以查看当前Alertmanager集群的状态。
到这里就完成了 之后可以测试告警。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号