正则表达式断言精讲 Java语法实现
断言
本文目的是讲解正则表达式之断言用法。目前互联网上有很多博文对断言讲解的并不透彻,如果您刚开始学习断言,相信此博文会对您有帮助。
本文谢绝转载,此文属原创文章,如有雷同,不胜荣幸。
https://cloud.tencent.com/developer/article/1149481
https://www.aqee.net/post/regular-expression-to-match-string-not-containing-a-word.html
1.2.3.1 情景导入
假设,我要获得一个字符串里面所有以空格开头的英文词语。
//检测由空格开始的词汇
Pattern pattern4 = Pattern.compile("\\s(?i)\\w+");
Matcher matcher3 = pattern4.matcher(" hello world");
while (matcher3.find()) {
String group = matcher3.group();
//可以用下面这种方法去除空格
System.out.println("group.trim() = " + group.trim());
// group.trim() = hello
// group.trim() = world
}
在使用上面的代码过程中存在一些问题,我获得的单词默认是前头带空格的,纵然我可以通过String类的trim来解决这些问题,可是这样用起来会很麻烦,有没有一种正则表达式的规则可以检测那些开头带空格的词汇但是适配到的词汇不带空格呢?答案是有的,那就是断言
什么是断言
在使用正则表达式时,有时我们需要捕获的内容前后必须是特定内容,但又不捕获这些特定内容的时候,零宽断言就起到作用了。
断言全称为零宽断言
断言的语法规则
(?=X)X, via zero-width positive lookahead 零宽前行正向断言 (?!X)X, via zero-width negative lookahead 零宽前行负向断言 (?<=X)X, via zero-width positive lookbehind 零宽后行正向断言 (?<!X)X, via zero-width negative lookbehind 零宽后行负向断言
零宽断言为什么叫零宽断言
理解这一点至关重要,拿零宽前行正向断言来举例
零宽
零宽的含义为断言部分不占据宽度,举个例子12(?=la)匹配12la匹配到的是12,含义是la前面的12。12la匹配12la匹配到的是12la,含义为匹配value为12la的字符串。不知道通过这个例子你能否看懂零宽的意义,不懂也没关系,看完接下来几章就会懂了。
前行
前行的含义我可以确定我说的是正确的,现在互联网上好多人对前行的理解是错误的,虽然按照他们的解释是可以解释的通大多数情况,但是我们还是要抱着实事求是的态度,还原前行真正的含义,参考网站:正则表达式零宽断言详解(?=,?<=,?!,?<!),Regular expression to match a line that doesn't contain a word。
在正则表达式中,每个字符串都是有定位的,所谓定位,就是确定字符串中每个字符位置的数字,这个只可意会,我给您看几张图,通过图片,或许可以理解
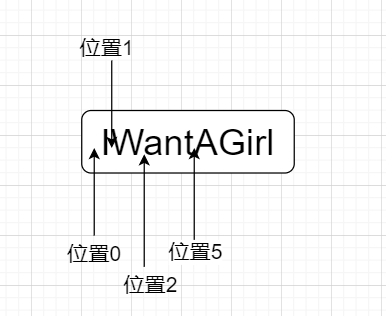
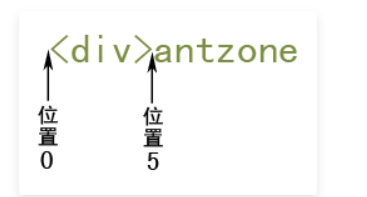
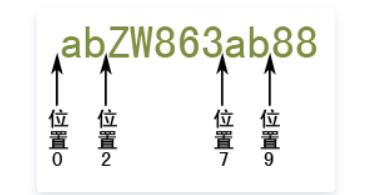
看到没有,字符串每一个字符间隔就是一个个位置点,字符串第一个字符前为位置0,字符串第一个字符和第二个字符之间为位置1,字符串第一个字符位于位置0和位置1之间,以此类推……
前行的意义为位置之前,后行的意义为位置之后
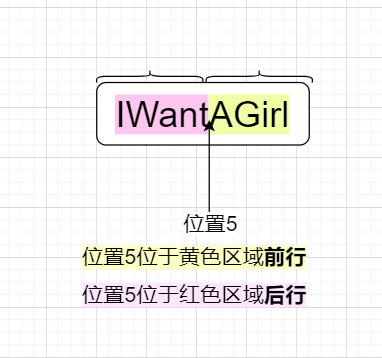
如上图,位置5位于红色区域后行,位置5位于黄色区域前行
那么,在断言中前行和后行代表着什么呢?
比如说正则表达式12(?=la)在匹配字符串qwew12bb12la的时候,他会先,匹配到从左往右第一个12,如下图所示👇
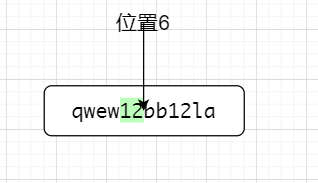
因为(?=x)是前行匹配,这个时候12是占位置的,位置点走到了第一个12的后面,即位置6,👆。因为是零宽,(?=la)不占位置,接下来以位置6为前行,匹配位置6的后面,位置6的后面不是la,故不匹配位置6前面的12,接下来位置转到了第二个12后面,如下图所示👇
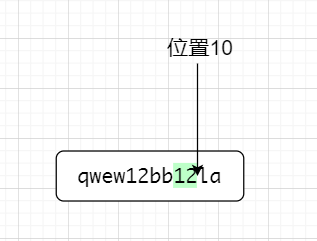
因为是前行匹配,位置10作为前行,匹配后面的字符,后面是la符合要求,因为零宽,匹配到的最终字符不包括零宽,如下图所示

不懂也没关系,看完接下来几章就会懂了。
负向
所谓负向,不符合为负向,如(?<!x)就是负向,该断言匹配的是不符合x标准的字符串作为目标字符串的后行
再来熟悉一下几个断言
(?=X)X, via zero-width positive lookahead 零宽前行正向断言 (?!X)X, via zero-width negative lookahead 零宽前行负向断言 (?<=X)X, via zero-width positive lookbehind 零宽后行正向断言 (?<!X)X, via zero-width negative lookbehind 零宽后行负向断言
断言DEMO
-
后行正向断言,该断言匹配前面是aa的字符
//后行正向断言 Pattern compile = Pattern.compile("(?<=aa)\\w+"); Matcher matcher = compile.matcher(" aadfds fdgs daafs"); while (matcher.find()) { System.out.println(matcher.group());//dfds }👆运行结果为👇
dfds fs -
后行负向断言,该断言匹配的是前面不是$的数字
Pattern compile1 = Pattern.compile("(?<!\\$|\\d)\\d+"); Matcher matcher1 = compile1.matcher("$14 23");//23 while (matcher1.find()) { System.out.println("matcher1.group() = " + matcher1.group()); }👆运行结果为👇
matcher1.group() = 23我来解释一下,正则表达式
(?<!\\$|\\d)\\d+,断言的意思是不匹配前面为$或数字的数字。模拟一下匹配的过程,也许会更加明白是怎么一回事儿,先说一下"$14 23",位置我就不在图中标了,自己数一下吧👇
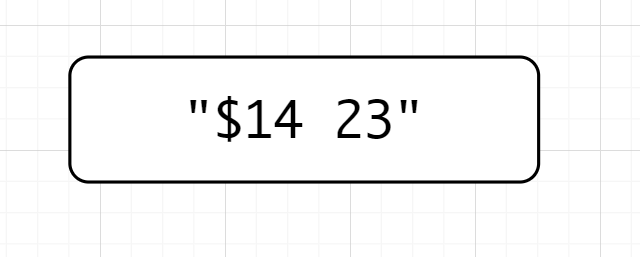
(?<!\\$|\\d)\\d+先匹配数字,匹配到了1,位置是1,因为断言是不占宽度的。因为是后行,检测到左边是\(,不符合断言要求,就来到了位置2(1和4之间),位置二前面是数字不符合要求,类推,位置来到了2的前面,前面是空格,既不是数字也不是\),符合要求,故匹配23 -
先行正向断言
Matcher matcher2 = Pattern.compile("(?i)windows(?=2000|xp|10)").matcher("windowsXp"); while (matcher2.find()) { System.out.println("matcher2.group() = " + matcher2.group()); }运行结果是👇
matcher2.group() = windows我来稍微解释一下,
"(?i)windows(?=2000|xp|10)"(?i)表明不区分大小写,Windows表明适配windows,(?=2000|xp|10)表明是零宽先行正向断言。我说一下匹配的过程,首先匹配windows,位置来到了windows后,零宽先行,后面是xp适配成功。 -
先行负向断言
Matcher matcher3 = Pattern.compile("(?i)Linux(?!12.3)").matcher("linux12."); while (matcher3.find()) { System.out.println("matcher3.group() = " + matcher3.group()); }运行结果是👇
matcher3.group() = linux这个就不解释了,自行理解吧
以上四个demo是最最基础的demo,在很多教程上对断言的讲解止步于此(实际上,很短教程连最基本的匹配过程都没讲,只讲了匹配的结果,这个要出大问题的),务须掌握好上面的四个demo。
断言的基础应用和实际用处
放一张思维导图
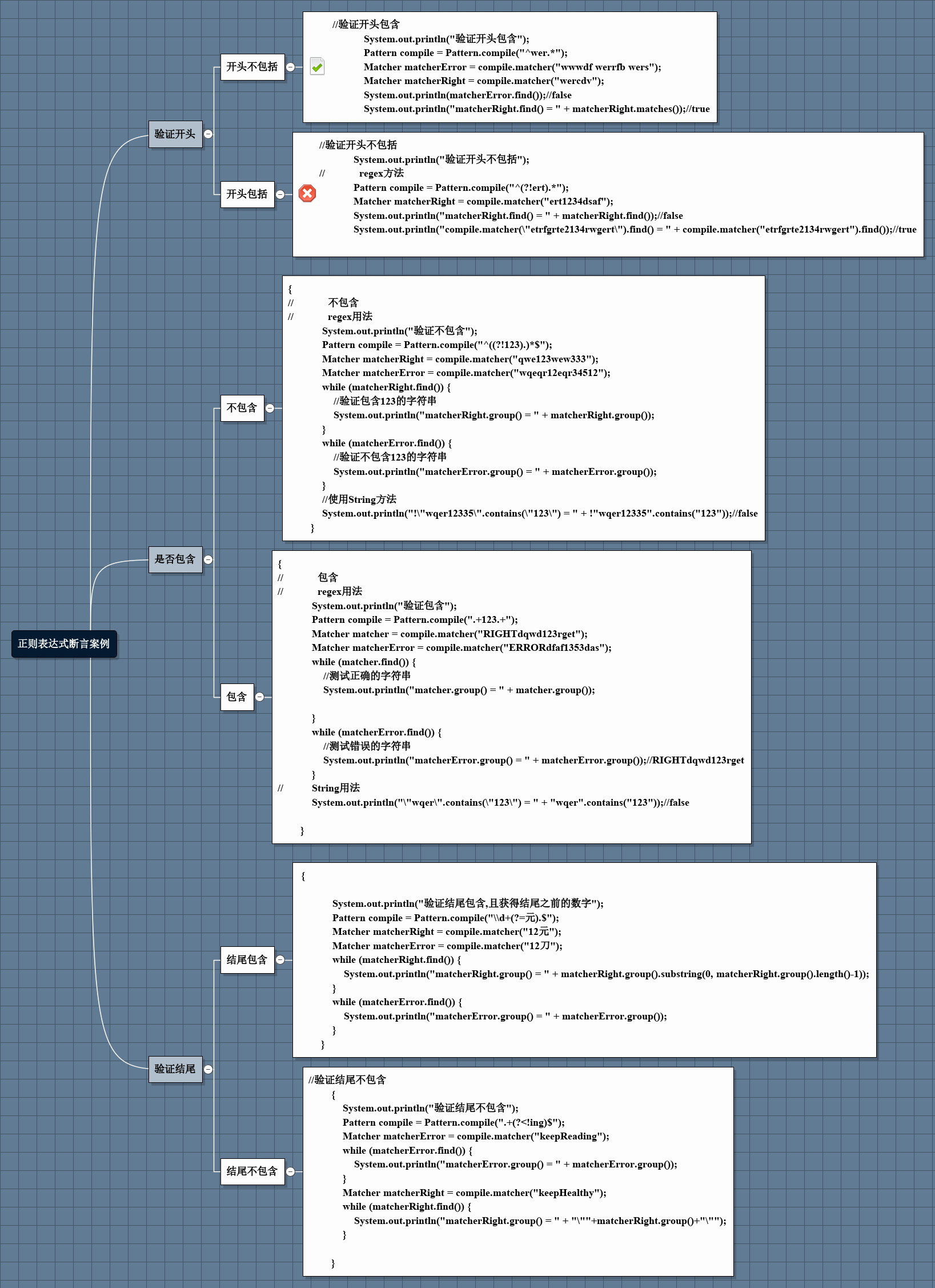
这个我先说一下结论,在实际应用开发中,在应用诸如验证开头或结尾(只要求一行的开头或结尾)的实践中,大概有两种,一种是零宽,一种是非零宽。所谓零宽即匹配的数据不包括断言,非零宽反之,在某些情况下需要借助String方法的subString()方法。
一般情况下,使用断言,主要是用它零宽的属性,验证开头包含,结尾包含时一般不用断言,分组就能解决问题,当开头不包含或结尾不包含等问题时,使用断言是很好的办法。
演示三个👇
验证不包含
/*
不包含
*/
{
// 不包含
// regex用法
System.out.println("验证不包含");
Pattern compile = Pattern.compile("^((?!123).)*$");
Matcher matcherRight = compile.matcher("qwe123wew333");
Matcher matcherError = compile.matcher("wqeqr12eqr34512");
while (matcherRight.find()) {
//验证包含123的字符串
System.out.println("matcherRight.group() = " + matcherRight.group());
}
while (matcherError.find()) {
//验证不包含123的字符串
System.out.println("matcherError.group() = " + matcherError.group());//matcherError.group() = wqeqr12eqr34512
}
//使用String方法
System.out.println("!\"wqer12335\".contains(\"123\") = " + !"wqer12335".contains("123"));//!"wqer12335".contains("123") = false
}
运行结果如下👇
验证不包含
matcherError.group() = wqeqr12eqr34512
!"wqer12335".contains("123") = false
解析:正则表达式里字符串"不包含"匹配技巧 | 外刊IT评论
验证开头包含
一行字符串,验证开头是否包含某字符串,若包含则输出匹配到的数据,此方法会包括断言。也就是说假如验证“123erre”的开头是否是123,匹配到的数据为123erre而不是erre。验证开头包含且匹配数据不包括断言请看下一章
{
System.out.println("验证开头包含");
Pattern compile = Pattern.compile("^(?=wer).*");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
// System.out.println("matcherRight.find() = " + matcherRight.find());//true
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());//wercdv
}
}
结果如下👇
验证开头包含
false
matcherRight.group() = wercdv
解析:
^(?=wer).*匹配wercdv的时候,先因为^来到了位置0,位置0后面是符合.*的,遂开始匹配断言,注意这时候位置依然在位置0,因为是先行断言,位置0后面是wer符合断言要求,故匹配到了wercdv
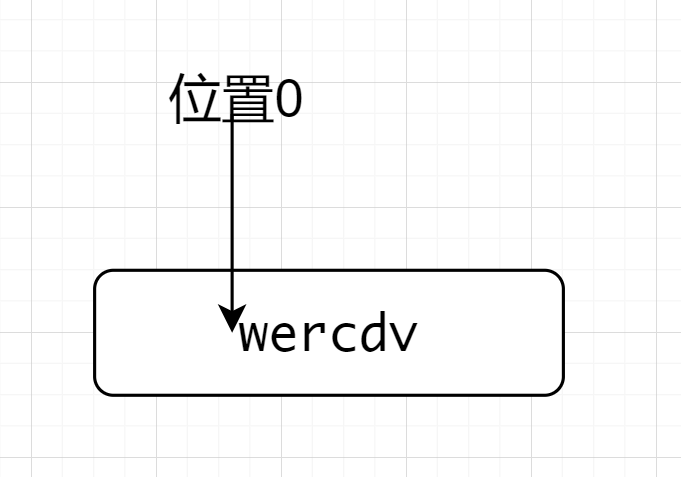
验证开头包含且匹配到的数据不包括断言
假如说要匹配开头是wer的字符串,字符串是wercdv,匹配到的是cdv而不是wercdv
{
System.out.println("验证开头包含,匹配到的数据不包括断言");
Pattern compile = Pattern.compile("^wer(?<=wer)(.*)");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.start() = " + matcherRight.start());//0
System.out.println("matcherRight.end() = " + matcherRight.end());//6
System.out.println("matcherRight.group() = " + matcherRight.group(1));//cdv
}
}
结果如下👇
验证开头包含,匹配到的数据不包括断言
false
matcherRight.start() = 0
matcherRight.end() = 6
matcherRight.group() = cdv
解析:
^wer(?<=wer)(.*)因为^所以先来到了位置0,然后匹配wer,来到了位置3,位置3后面符合.*的要求,因为后行匹配,前面是wer,符合要求,在取出的过程中,有一个分组,选取的是.*故最终取出cdv
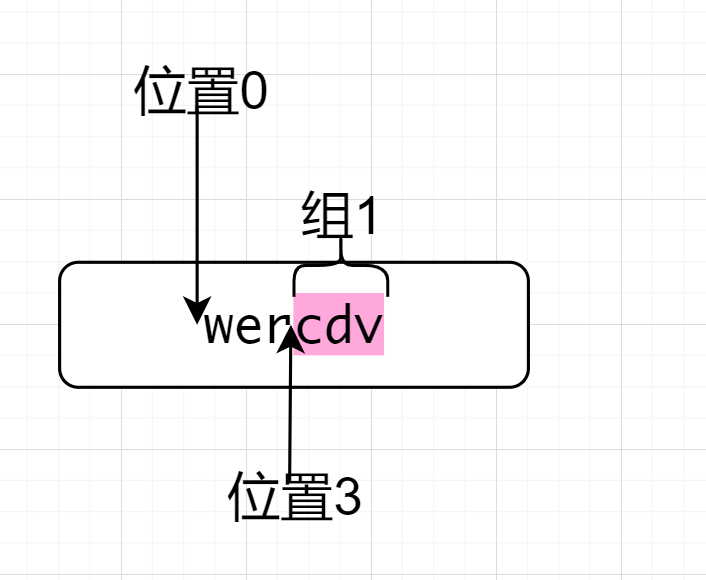
验证结尾包含,且匹配到的数据不包括断言
举个例子,匹配以“元”结尾的词汇,且匹配到的数据不包括“元”,譬如“12元”,匹配到的数据是12。
//验证结尾包含
{
System.out.println("验证结尾包含,且获得结尾之前的数字");
Pattern compile = Pattern.compile("(\\d+)(?=元).$");
Matcher matcherRight = compile.matcher("12元");
Matcher matcherError = compile.matcher("12刀");
while (matcherRight.find()) {
System.out.println("matcherRight.group(1) = " + matcherRight.group(1));//12
}
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
}
运行结果是👇
验证结尾包含,且获得结尾之前的数字
matcherRight.group(1) = 12
解析:
(\\d+)(?=元).$因为$先来到位置3,如图所示👇
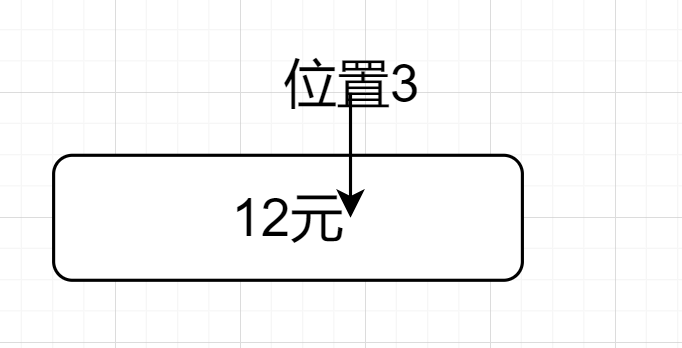
然后因为(\\d+)(?=元).$的.,位置向前一步,来到了位置2,然后前行断言,位置2的后面是元,前面是数字符合要求,如下图所示👇
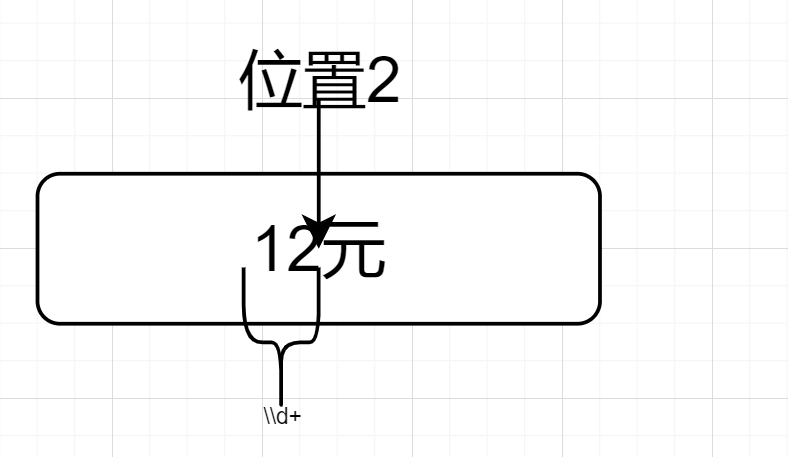
匹配到了“12元”,因为输出组①,故最终输出12。
断言基础应用总体代码
代码文件👇,运行结果写在了注释里面
/**
* 基础正则表达式实例
*/
@Test
public void testRegexOne() {
System.out.println(
"{\"name\": \"正则表达式相关断言有关的demo\",\n" +
" " +
"\"个数\": 2" +
"}");
/*
包含
*/
{
// 包含
// regex用法
System.out.println("验证包含");
Pattern compile = Pattern.compile(".+123.+");
Matcher matcher = compile.matcher("RIGHTdqwd123rget");
Matcher matcherError = compile.matcher("ERRORdfaf1353das");
while (matcher.find()) {
//测试正确的字符串
System.out.println("matcher.group() = " + matcher.group());
}
while (matcherError.find()) {
//测试错误的字符串
System.out.println("matcherError.group() = " + matcherError.group());//RIGHTdqwd123rget
}
// String用法
System.out.println("\"wqer\".contains(\"123\") = " + "wqer".contains("123"));//false
}
/*
不包含
*/
{
// 不包含
// regex用法
System.out.println("验证不包含");
Pattern compile = Pattern.compile("^((?!123).)*$");
Matcher matcherRight = compile.matcher("qwe123wew333");
Matcher matcherError = compile.matcher("wqeqr12eqr34512");
while (matcherRight.find()) {
//验证包含123的字符串
System.out.println("matcherRight.group() = " + matcherRight.group());
}
while (matcherError.find()) {
//验证不包含123的字符串
System.out.println("matcherError.group() = " + matcherError.group());//matcherError.group() = wqeqr12eqr34512
}
//使用String方法
System.out.println("!\"wqer12335\".contains(\"123\") = " + !"wqer12335".contains("123"));//!"wqer12335".contains("123") = false
}
/*
验证开头
*/
//验证开头不包含
{
//验证开头不包括
System.out.println("验证开头不包括");
// regex方法
Pattern compile = Pattern.compile("^(?!ert).*");
Matcher matcherRight = compile.matcher("ert1234dsaf");
// System.out.println("matcherRight.find() = " + matcherRight.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());
}
// System.out.println("compile.matcher(\"etrfgrte2134rwgert\").find() = " + compile.matcher("etrfgrte2134rwgert").find());//true
Matcher matcherError = compile.matcher("etrfgrte2134rwgert");
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());//etrfgrte2134rwgert
}
}
{
System.out.println("验证开头包含");
Pattern compile = Pattern.compile("^(?=wer).*");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
// System.out.println("matcherRight.find() = " + matcherRight.find());//true
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + matcherRight.group());//wercdv
}
}
//验证开头包含
{
System.out.println("验证开头包含,匹配到的数据不包括断言");
Pattern compile = Pattern.compile("^wer(?<=wer)(.*)");
Matcher matcherError = compile.matcher("wwwdf werrfb wers");
Matcher matcherRight = compile.matcher("wercdv");
System.out.println(matcherError.find());//false
while (matcherRight.find()) {
System.out.println("matcherRight.start() = " + matcherRight.start());//0
System.out.println("matcherRight.end() = " + matcherRight.end());//6
System.out.println("matcherRight.group() = " + matcherRight.group(1));//cdv
}
}
//验证结尾不包含
{
System.out.println("验证结尾不包含");
Pattern compile = Pattern.compile(".+(?<!ing)$");
Matcher matcherError = compile.matcher("keepReading");
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
Matcher matcherRight = compile.matcher("keepHealthy");
while (matcherRight.find()) {
System.out.println("matcherRight.group() = " + "\""+matcherRight.group()+"\"");//"keepHealthy"
}
}
//验证结尾包含
{
System.out.println("验证结尾包含,且获得结尾之前的数字");
Pattern compile = Pattern.compile("(\\d+)(?=元).$");
Matcher matcherRight = compile.matcher("12元");
Matcher matcherError = compile.matcher("12刀");
while (matcherRight.find()) {
System.out.println("matcherRight.group(1) = " + matcherRight.group(1));//12
}
while (matcherError.find()) {
System.out.println("matcherError.group() = " + matcherError.group());
}
}
}
不按套路出牌,帮你彻底理解断言
一般情况下,使用断言,主要是用它零宽的属性,向验证开头包含,结尾包含时一般不用断言,分组就能解决问题,当开头不包含或结尾不包含等问题时,使用断言是很好的办法。
@Test
public void testOther(){
System.out.println("不按套路来,帮您彻底理解断言");
Pattern compile = Pattern.compile("(?=re)\\w+");
Matcher matcher = compile.matcher("reading a book");
System.out.println("不按套路来的零宽先行正向断言");
while (matcher.find()) {
System.out.println("matcher.group() = " + matcher.group());//matcher.group() = reading
}
System.out.println("不按套路来的零宽后行正向断言");
Pattern compile1 = Pattern.compile("\\w+(?i)(?<=re)");
Matcher matcher1 = compile1.matcher("i want toReading a book");
while (matcher1.find()) {
System.out.println("matcher1.group() = " + matcher1.group());//matcher1.group() = toRe
}
System.out.println("不按套路来的零宽先行负向断言");
Pattern compile2 = Pattern.compile("(?i)ing(?!re)\\w+");
Matcher matcher2 = compile2.matcher("i am LovingReading a book and HatingBuy a book");
while (matcher2.find()) {
System.out.println("matcher2.group() = " + matcher2.group());//matcher2.group() = ingBuy
}
System.out.println("不按套路来的零宽后行负向断言");
Pattern compile3 = Pattern.compile("(?i)\\w+(?<!re)a");
Matcher matcher3 = compile3.matcher("llrea lla");
while (matcher3.find()) {
System.out.println("matcher3.group() = " + matcher3.group());//matcher3.group() = lla
}
}
绝大多数网站在讲解断言问题的时候总是去引用断言demo一章里面那四个例子,这会给人造成一种“前行断言适配结尾,后行断言适配开头”的错觉,事实上并不是这个样子,重要的是要具体问题具体分析。如同上面的代码,不按所谓常理出牌,有助于正则表达式之理解。
上面取了四个例子,皆不按套路来,为方便理解,选一个细讲
System.out.println("不按套路来的零宽后行负向断言");
Pattern compile3 = Pattern.compile("(?i)\\w+(?<!re)a");
Matcher matcher3 = compile3.matcher("llrea lla");
while (matcher3.find()) {
System.out.println("matcher3.group() = " + matcher3.group());//matcher3.group() = lla
}
运行结果👇
不按套路来的零宽后行负向断言
matcher3.group() = lla
(?i)\\w+(?<!re)a的本意是不区分大小写地去适配结尾是a且a的前面不是re的字符。(?!)是不区分大小写的意思。正则发挥作用时,先找到a,位置来到a的前面,因为后行断言,位置的前面不能是re。因为\\w+,a的前面需要是字母或数字。综合看来,意思是a的前面是除re之外的字母或数字。
如果真的不理解,就死记下面的实例
-
不包含a
Pattern compile = Pattern.compile("^((?!a).)*$"); Matcher matcher = compile.matcher("ssdas"); System.out.println("matcher.find() = " + matcher.find());//matcher.find() = false -
开头不包含a
Pattern compile1 = Pattern.compile("^(?!a).*"); Matcher matcher1 = compile1.matcher("basa"); System.out.println("matcher1.find() = " + matcher1.find());//matcher1.find() = true -
结尾不包含a
Pattern compile2 = Pattern.compile("\\w*(?<!a)$"); Matcher matcher2 = compile2.matcher("qwerdsa"); System.out.println("matcher2.find() = " + matcher2.find());//matcher2.find() = false -
包含a且不包含b
Pattern compile3 = Pattern.compile("^((?!b).)*a((?!b).)*$"); Matcher matcher3 = compile3.matcher("qwbera"); System.out.println("matcher3.find() = " + matcher3.find());//matcher3.find() = false -
处于a和b之间
Pattern compile4 = Pattern.compile("^.(?<=a)(.*)(?=b).$"); Matcher matcher4 = compile4.matcher("asdbdb"); System.out.println("matcher4.find() = " + matcher4.find());//matcher4.find() = true System.out.println("matcher4.group() = " + matcher4.group(1));//matcher4.group() = sdbd -
适配字符串中所有不以b结尾的数字
Pattern compile5 = Pattern.compile("\\d+(?!b|\\d+)"); Matcher matcher5 = compile5.matcher("1b 123b 123 45"); System.out.println("matcher5.find() = " + matcher5.find());//matcher5.find() = true System.out.println("matcher5.group() = " + matcher5.group());//matcher5.group() = 123 matcher5.find(); System.out.println("matcher5.group() = " + matcher5.group());//matcher5.group() = 45 -
适配字符串中所有以a开头的数字
Pattern compile6 = Pattern.compile("(?<=a)\\d+"); Matcher matcher6 = compile6.matcher("123 123 a231 a34 45a a23"); while (matcher6.find()) { System.out.println("matcher6.group() = " + matcher6.group()); //matcher6.group() = 231 //matcher6.group() = 34 //matcher6.group() = 23 }
在某些时候亦可以用\b来实现某些可以用断言实现的正则表达,举个例子👇
获取所有以b结尾的数字
Pattern compile7 = Pattern.compile("(\\d+)b\\b");
Matcher matcher7 = compile7.matcher("1b 123b 123 45");
while (matcher7.find()) {
System.out.println("matcher7.group() = " + matcher7.group(1));
// matcher7.group() = 1
// matcher7.group() = 123
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号