梯度下降法与反向传播
一、梯度下降法
1.什么是梯度下降法
顺着梯度下滑,找到最陡的方向,迈一小步,然后再找当前位,置最陡的下山方向,再迈一小步…
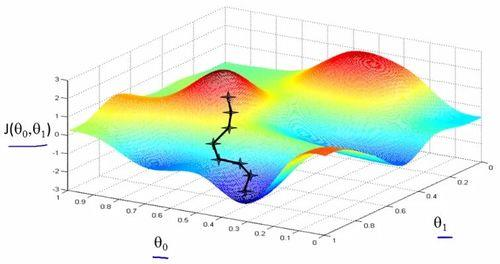
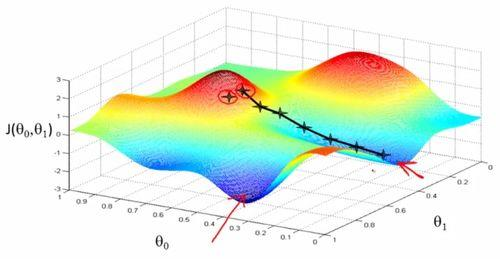
通过比较以上两个图,可以会发现,由于初始值的不同,会得到两个不同的极小值,所以权重初始值的设定也是十分重要的,通常的把W全部设置为0很容易掉到局部最优解,一般可以按照高斯分布的方式分配初始值。
2.有两种计算梯度的方法:
(1)慢一些但是简单一些的数值梯度/numerical gradient
对每个维度,都在原始值上加上一个很小的h,然后计算这个维度/方向上的偏导,最后组在一起得到梯度grad。
#encoding:utf-8 import numpy as np def eval_numeriical(f,x): """"计算x上f的梯度算法,x是一个vector,f为参数为x的函数""" fx=f(x) grad=np.zero(x.shape) h=0.00001 #对x的每个维度都计算一遍 it=np.nditer(x,flags=['multi_index'],op_flags=['readwrite']) while not it.finished: #计算x+h处的函数值 ix=it.multi_index old_value=x[ix] x[ix]=old_value+h fxh=f(x) x[ix]=old_value #计算偏导数 grad[ix]=(fxh-fx)/h it.iternext()
return grad
关于迭代的步长:1)步子迈得太小,时间耗不起。 2)步子迈得太大,容易跳过最小值,可能找不到最优点
(2) 速度快但是更容易出错的解析梯度/analytic gradient
解析法计算梯度:速度非常快,但是容易出错(反倒之前的数值法就显出优势),我们可以先计算解析梯度和数值梯度,然后比对结果和校正,然后就可以大胆地进行解析法计算了(这个过程叫做梯度检查/检测)
举例:一个样本点的SVM损失函数:
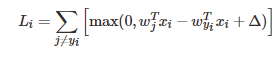
求偏导:
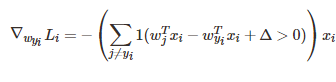
这个求偏导的意思是:当括号里的l是个布尔函数,表示如果括号里的表达式成立的话就是1,不成立的话就是0.
3.这个简单的循环就是很多神经网络库的核心

4.什么是Mini-batch,以及其作用
Mini-batch就是从所有的训练样本中抽出一部分来训练,被抽出的训练样本就是Mini-batch。
对整个训练数据集的样本都算一遍损失函数,以完成参数迭代是一件非常耗时的事情,一个我们通常会用到的替代方法是,采样出一个子集在其上计算梯度。

二、反向传播
简单来说就是高数中得链式法则。
比如函数f(x,y,z)=(x+y)*z

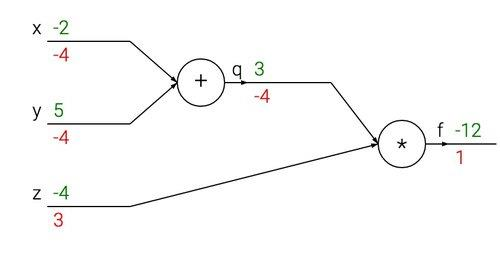
Sigmoid例子
函数: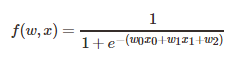
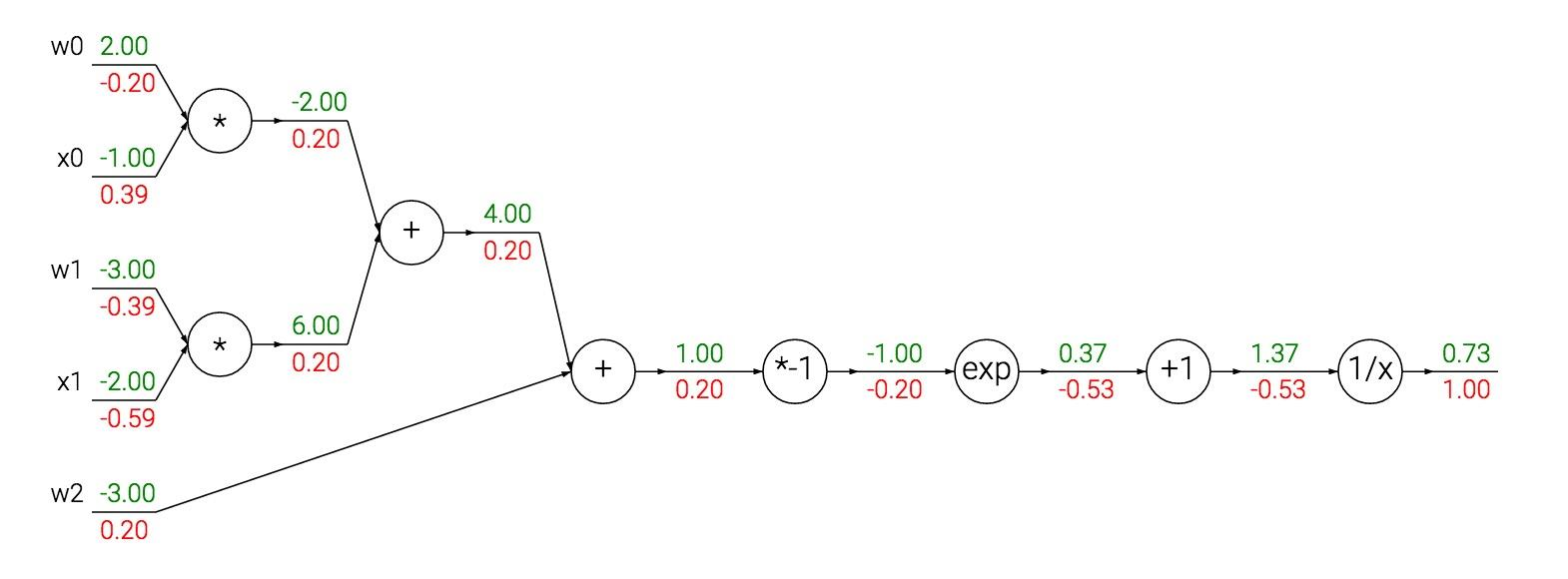
Sigmoid函数 的导数

具体算一下:

Sigmoid神经网络的例子
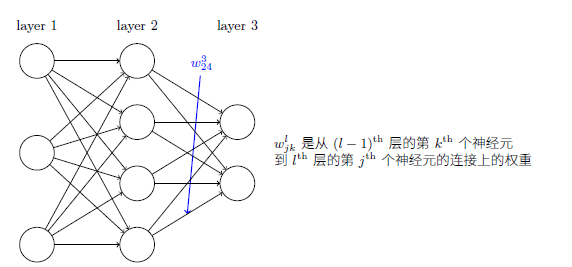
(1) 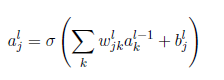
(2)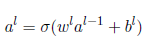
(3)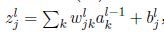
(4)
以上为正向传播的公式,(2)是对(1)的简单缩写,a=sigmod(z),c为cost损失函数,c对z的偏导为输出层的误差

损失函数要可导,第一个公式是求损失函数对于L层的神经元的偏导,为了更容易理解,不是对a求偏导,而是对z求偏导,其中a=sigmod(a)。也就是可以得出dc/dz,我们要求得dc/dw=dc/dz * dz/dw,而dz/dw就是a的值,最终推得第四个公式。
概括的一个描述:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号