Python 爬取生成中文词云以爬取知乎用户属性为例
代码如下:
# -*- coding:utf-8 -*-
import requests
import pandas as pd
import time
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
header={
'authorization':'Bearer 2|1:0|10:1515395885|4:z_c0|92:Mi4xOFQ0UEF3QUFBQUFBRU1LMElhcTVDeVlBQUFCZ0FsVk5MV2xBV3dDLVZPdEhYeGxaclFVeERfMjZvd3lOXzYzd1FB|39008996817966440159b3a15b5f921f7a22b5125eb5a88b37f58f3f459ff7f8',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36',
'X-UDID':'ABDCtCGquQuPTtEPSOg35iwD-FA20zJg2ps=',
}
user_data = []
def get_user_data(page):
for i in range(page):
url = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
#response = requests.get(url, headers=header).text
response = requests.get(url, headers=header).json()['data']#['data'] 只有JSON格式中选择data节点
user_data.extend(response)
print('正在爬取%s页' % str(i+1))
time.sleep(1)
if __name__=='__main__':
get_user_data(10)
#pandas 的函数 from_dict()可以直接将一个response变成一个对象
#df = pd.DataFrame.from_dict(user_data)
#df.to_csv('D:/PythonWorkSpace/TestData/zhihu/user2.csv')
df = pd.DataFrame.from_dict(user_data).get('headline')
df.to_csv('D:/PythonWorkSpace/TestData/zhihu/headline.txt')
text_from_file_with_apath = open('D:/PythonWorkSpace/TestData/zhihu/headline.txt').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
需要安装准备的库:
pip install matplotlib
pip install jieba
pip install wordcloud(发现这方法安装不成功)
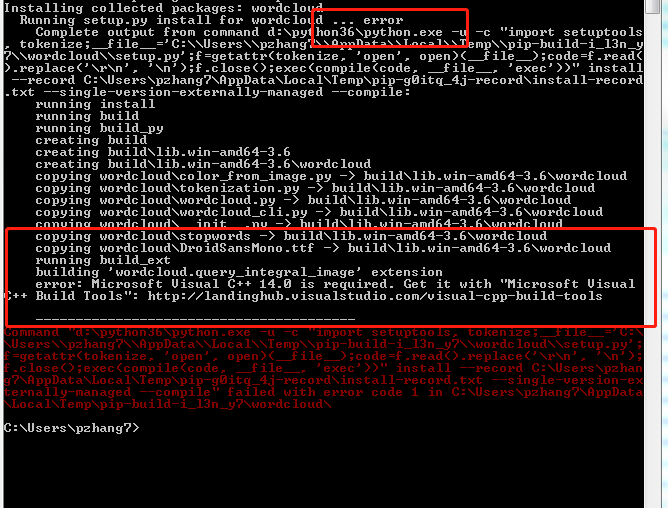
换种安装方式到 https://github.com/amueller/word_cloud 这里下载库文件,解压,然后进入到解压后的文件,按住shift+鼠标右键 打开命令窗口运行一下命令:
python setup.py install 然后同样报错
然后我又换了一张安装方式:
到 http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud 页面下载所需的wordcloud模块的whl文件,下载后进入存储该文件的路径,按照方法一,执行“pip install wordcloud-1.3.3-cp36-cp36m-win_amd64.whl”,这样就会安装成功。
然后生成词云的代码如下:
text_from_file_with_apath = open('D:\Python\zhihu\headline.txt','r',encoding='utf-8').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
但是发现不显示中文,这可就头疼了。
显示的是一些大大小小的彩色框框。这是因为,我们使用的wordcloud.py中,FONT_PATH的默认设置不识别中文。
仔细研究之后做了改进,终于可以正常显示中文了
text_from_file_with_apath = open('D:\Python\zhihu\headline.txt','r',encoding='utf-8').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
#FONT_PATH = os.environ.get("FONT_PATH", os.path.join(os.path.dirname(__file__), "simkai.ttf"))
cloud = WordCloud(
#设置字体,不指定就会出现乱码
font_path="simkai.ttf",
#设置背景色
background_color='white',
#允许最大词汇
max_words=9000,
#词云形状
#mask=color_mask
)#.generate(wl_space_split)
## 产生词云
word_cloud = cloud.generate(wl_space_split)
word_cloud.to_file('D:\Python\zhihu\headline.jpg')#将图片保存到指定文件中
#直接显示图片,并且可编辑
# plt.imshow(word_cloud)
# plt.axis("off")
# plt.show()

坑:
Python读取文件时经常会遇到这样的错误:python3.4 UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
import codecs,sys
f = codecs.open("***.txt","r","utf-8")
指明打开文件的编码方式就可以消除错误了
***********若有错误欢迎指正
欢迎关注微信公众号【软测小生】,号内有大量免费软件测试学习资料,欢迎自取,还望多多交流软件测试相关的内容*********

 浙公网安备 33010602011771号
浙公网安备 33010602011771号