重新认识下JVM级别的本地缓存框架Guava Cache(2)——深入解读其容量限制与数据淘汰策略

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
通过《重新认识下JVM级别的本地缓存框架Guava Cache——优秀从何而来》一文,我们知道了Guava Cache作为JVM级别的本地缓存组件的诸多暖心特性,也一步步地学习了在项目中集成并使用Guava Cache进行缓存相关操作。Guava Cache作为一款优秀的本地缓存组件,其内部很多实现机制与设计策略,同样值得开发人员深入的掌握与借鉴。
作为系列专栏,本篇文章我们将在上一文的基础上,继续探讨下Guava Cache对于缓存容量限制与数据清理相关的使用与设计机制,进而让我们在项目中使用起来可以更加的游刃有余,解锁更多使用技巧。

容量限制时的Size与Weight区别
弄清Size与Weight
Guava Cache提供了对缓存总量的限制,并且支持从两个维度进行限制,这里我们首先要厘清size与weight两个概念的区别与联系。

- 限制缓存条数size
public Cache<String, User> createUserCache() {
return CacheBuilder.newBuilder().maximumSize(10000L).build();
}
- 限制缓存权重weight
public Cache<String, String> createUserCache() {
return CacheBuilder.newBuilder()
.maximumWeight(50000)
.weigher((key, value) -> (int) Math.ceil(value.length() / 1000))
.build();
}
一般而言,我们限制容器的容量的初衷,是为了防止内存占用过大导致内存溢出,所以本质上是限制内存的占用量。从实现层面,往往会根据总内存占用量与预估每条记录字节数进行估算,将其转换为对缓存记录条数的限制。这种做法相对简单易懂,但是对于单条缓存记录占用字节数差异较大的情况下,会导致基于条数控制的结果不够精准。
比如:
需要限制缓存最大占用
500M总量,缓存记录可能大小范围是1k~100k,按照每条50k进行估算,设定缓存容器最大容量为限制最大容量1w条。如果存储的都是1k大小的记录,则内存总占用量才10M(内存没有被有效利用起来);若都存储的是100k大小的记录,又会导致内存占用为1000M,远大于预期的内存占用量(容易造成内存溢出)。
为了解决这个问题,Guava Cache中提供了一种相对精准的控制策略,即基于权重的总量控制,根据一定的规则,计算出每条value记录所占的权重值,然后以权重值进行总量的计算。
还是上面的例子,我们按照权重进行设定,假定1k对应基础权重1,则100k可转换为权重100。这样一来:
限制缓存最大占用
500M,1k对应权重1,Nk代表权重N,则我们可以限制总权重为50w。这样假如存储的都是1k的记录,则最多可以缓存5w条记录;而如果都是100k大小的记录,则最多仅可以缓存5000条记录。根据存储数据的大小不同,最大存储的记录条数也不相同,但是最终占用的总体量可以实现基本吻合。
所以,基于weight权重的控制方式,比较适用于这种对容器体量控制精度有严格诉求的场景,可以在创建容器的时候指定每条记录的权重计算策略(比如基于字符串长度或者基于bytes数组长度进行计算权重)。
使用约束说明
在实际使用中,这几个参数之间有一定的使用约束,需要特别注意一下:
-
如果没有指定weight实现逻辑,则使用
maximumSize来限制最大容量,按照容器中缓存记录的条数进行限制;这种情况下,即使设定了maximumWeight也不会生效。 -
如果指定了weight实现逻辑,则必须使用
maximumWeight来限制最大容量,按照容器中每条缓存记录的weight值累加后的总weight值进行限制。
看下面的一个反面示例,指定了weighter和maximumSize,却没有指定 maximumWeight属性:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.weigher((key, value) -> 2)
.maximumSize(2)
.build();
cache.put("key1", "value1");
cache.put("key2", "value2");
System.out.println(cache.size());
} catch (Exception e) {
e.printStackTrace();
}
}
执行的时候,会报错,提示weighter和maximumSize不可以混合使用:
java.lang.IllegalStateException: maximum size can not be combined with weigher
at com.google.common.base.Preconditions.checkState(Preconditions.java:502)
at com.google.common.cache.CacheBuilder.maximumSize(CacheBuilder.java:484)
at com.veezean.skills.cache.guava.CacheService.main(CacheService.java:205)
Guava Cache淘汰策略
为了简单描述,我们将数据从缓存容器中移除的操作统称数据淘汰。按照触发形态不同,我们可以将数据的清理与淘汰策略分为被动淘汰与主动淘汰两种。
被动淘汰
- 基于数据量(size或者weight)
当容器内的缓存数量接近(注意是接近、而非达到)设定的最大阈值的时候,会触发guava cache的数据清理机制,会基于LRU或FIFO删除一些不常用的key-value键值对。这种方式需要在创建容器的时候指定其maximumSize或者maximumWeight,然后才会基于size或者weight进行判断并执行上述的清理操作。
看下面的实验代码:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.removalListener(notification -> {
System.out.println("---监听到缓存移除事件:" + notification);
})
.build();
System.out.println("put放入key1");
cache.put("key1", "value1");
System.out.println("put放入key2");
cache.put("key2", "value1");
System.out.println("put放入key3");
cache.put("key3", "value1");
System.out.println("put操作后,当前缓存记录数:" + cache.size());
System.out.println("查询key1对应值:" + cache.getIfPresent("key1"));
} catch (Exception e) {
e.printStackTrace();
}
}
上面代码中,没有设置数据的过期时间,理论上数据是长期有效、不会被过期删除。为了便于测试,我们设定缓存最大容量为2条记录,然后往缓存容器中插入3条记录,观察下输出结果如下:
put放入key1
put放入key2
put放入key3
---监听到缓存移除事件:key1=value1
put操作后,当前缓存记录数:2
查询key1对应值:null
从输出结果可以看到,即使数据并没有过期,但在插入第3条记录的时候,缓存容器还是自动将最初写入的key1记录给移除了,挪出了空间用于新的数据的插入。这个就是因为触发了Guava Cache的被动淘汰机制,以确保缓存容器中的数据量始终是在可控范围内。
- 基于过期时间
Guava Cache支持根据创建时间或者根据访问时间来设定数据过期处理,实际使用的时候可以根据具体需要来选择对应的方式。
| 过期策略 | 具体说明 |
|---|---|
| 创建过期 | 基于缓存记录的插入时间判断。比如设定10分钟过期,则记录加入缓存之后,不管有没有访问,10分钟时间到则 |
| 访问过期 | 基于最后一次的访问时间来判断是否过期。比如设定10分钟过期,如果缓存记录被访问到,则以最后一次访问时间重新计时;只有连续10分钟没有被访问的时候才会过期,否则将一直存在缓存中不会被过期。 |
看下面的实验代码:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.expireAfterWrite(1L, TimeUnit.SECONDS)
.recordStats()
.build();
cache.put("key1", "value1");
cache.put("key2", "value2");
cache.put("key3", "value3");
System.out.println("put操作后,当前缓存记录数:" + cache.size());
System.out.println("查询key1对应值:" + cache.getIfPresent("key1"));
System.out.println("统计信息:" + cache.stats());
System.out.println("-------sleep 等待超过过期时间-------");
Thread.sleep(1100L);
System.out.println("执行key1查询操作:" + cache.getIfPresent("key1"));
System.out.println("当前缓存记录数:" + cache.size());
System.out.println("当前统计信息:" + cache.stats());
System.out.println("剩余数据信息:" + cache.asMap());
} catch (Exception e) {
e.printStackTrace();
}
}
在实验代码中,我们设置了缓存记录1s有效期,然后等待其过期之后查看其缓存中数据情况,代码执行结果如下:
put操作后,当前缓存记录数:3
查询key1对应值:value1
统计信息:CacheStats{hitCount=1, missCount=0, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=0}
-------sleep 等待超过过期时间-------
执行key1查询操作:null
当前缓存记录数:1
当前统计信息:CacheStats{hitCount=1, missCount=1, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=2}
剩余数据信息:{}
从结果中可以看出,超过过期时间之后,再次执行get操作已经获取不到已过期的记录,相关记录也被从缓存容器中移除了。请注意,上述代码中我们特地是在过期之后执行了一次get请求然后才去查看缓存容器中存留记录数量与统计信息的,主要是因为Guava Cache的过期数据淘汰是一种被动触发技能。
当然,细心的小伙伴可能会发现上面的执行结果有一个“问题”,就是前面一起put写入了3条记录,等到超过过期时间之后,只移除了2条过期数据,还剩了一条记录在里面?但是去获取剩余缓存里面的数据的时候又显示缓存里面是空的?
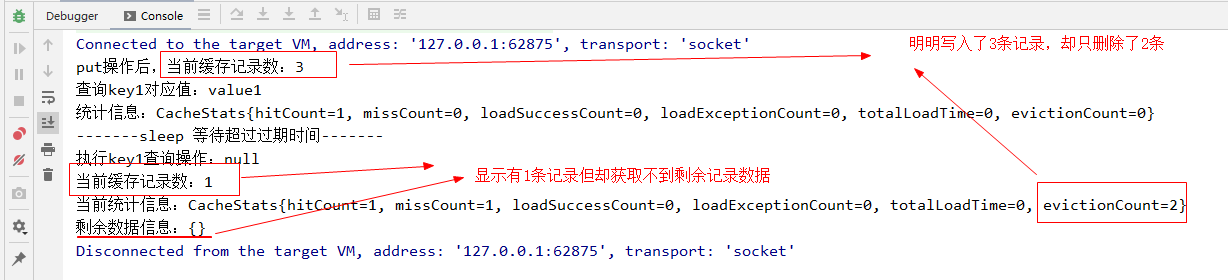
Guava Cache作为一款优秀的本地缓存工具包,是不可能有这么个大的bug遗留在里面的,那是什么原因呢?
这个现象其实与Guava Cache的缓存淘汰实现机制有关系,前面说过Guava Cache的过期数据清理是一种被动触发技能,我们看下getIfPresent方法对应的实现源码,可以很明显的看出每次get请求的时候都会触发一次cleanUp操作:
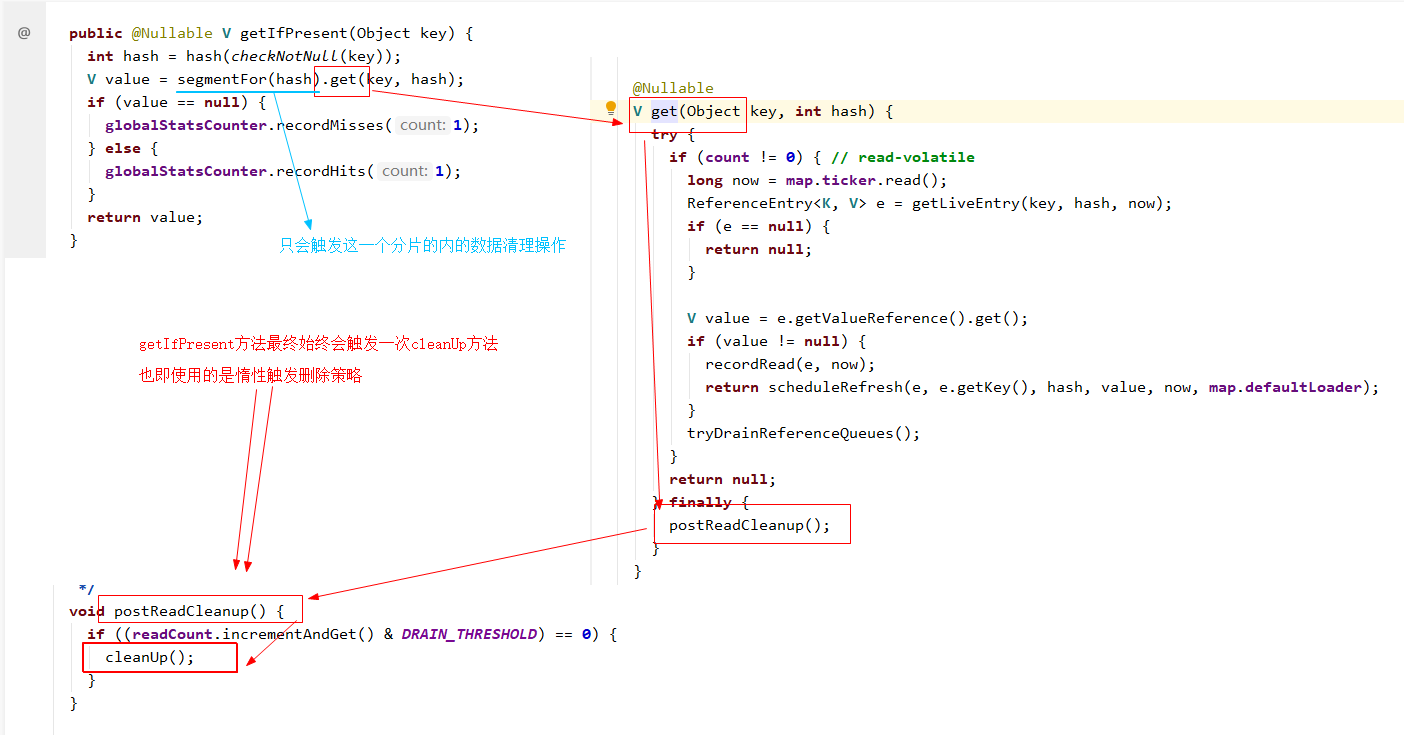
为了实现高效的多线程并发控制,Guava Cache采用了类似ConcurrentHashMap一样的分段锁机制,数据被分为了不同分片,每个分片同一时间只允许有一个线程执行写操作,这样降低并发锁争夺的竞争压力。而上面代码中也可以看出,执行清理的时候,仅针对当前查询的记录所在的Segment分片执行清理操作,而其余的分片的过期数据并不会触发清理逻辑 —— 这个也就是为什么前面例子中,明明3条数据都过期了,却只清理掉了其中的2条的原因。
为了验证上述的原因说明,我们可以在创建缓存容器的时候将concurrencyLevel设置为允许并发数为1,强制所有的数据都存放在同一个分片中:
public static void main(String[] args) {
try {
Cache<String, String> cache = CacheBuilder.newBuilder()
.expireAfterWrite(1L, TimeUnit.SECONDS)
.concurrencyLevel(1) // 添加这一约束,强制所有数据放在一个分片中
.recordStats()
.build();
// ...省略其余逻辑,与上一段代码相同
} catch (Exception e) {
e.printStackTrace();
}
}
重新运行后,从结果可以看出,这一次3条过期记录全部被清除了。
put操作后,当前缓存记录数:3
查询key1对应值:value1
统计信息:CacheStats{hitCount=1, missCount=0, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=0}
-------sleep 等待超过过期时间-------
执行key1查询操作:null
当前缓存记录数:0
当前统计信息:CacheStats{hitCount=1, missCount=1, loadSuccessCount=0, loadExceptionCount=0, totalLoadTime=0, evictionCount=3}
剩余数据信息:{}
在实际的使用中,我们倒也无需过于关注数据过期是否有被从内存中真实移除这一点,因为Guava Cache会在保证业务数据准确的情况下,尽可能的兼顾处理性能,在该清理的时候,自会去执行对应的清理操作,所以也无需过于担心。
- 基于引用
基于引用回收的策略,核心是利用JVM虚拟机的GC机制来达到数据清理的目的。按照JVM的GC原理,当一个对象不再被引用之后,便会执行一系列的标记清除逻辑,并最终将其回收释放。这种实际使用的较少,此处不多展开。
主动淘汰
上述通过总体容量限制或者通过过期时间约束来执行的缓存数据清理操作,是属于一种被动触发的机制。
实际使用的时候也会有很多情况,我们需要从缓存中立即将指定的记录给删除掉。比如执行删除或者更新操作的时候我们就需要删除已有的历史缓存记录,这种情况下我们就需要主动调用 Guava Cache提供的相关删除操作接口,来达到对应诉求。
| 接口名称 | 含义描述 |
|---|---|
| invalidate(key) | 删除指定的记录 |
| invalidateAll(keys) | 批量删除给定的记录 |
| invalidateAll() | 清空整个缓存容器 |
小结回顾
好啦,关于Guava Cache中的容量限制与数据淘汰策略,就介绍到这里了。关于本章的内容,你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
📣 补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
📣 补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

本文来自博客园,作者:是Vzn呀,欢迎关注公众号[架构悟道]持续获取更多干货,转载请注明原文链接:https://www.cnblogs.com/softwarearch/p/16920807.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号