Spark编译与打包
编译打包
Spark支持Maven与SBT两种编译工具,这里使用了Maven进行编译打包;
在执行make-distribution脚本时它会检查本地是否已经存在Maven还有当前Spark所依赖的Scala版本,如果不存在它会自动帮你下载到build目录中并解压使用;Maven源最好配置成OSChina的中央库,这下载依赖包比较快;
耐心等待,我编译过多次所以没有下载依赖包,大概半个小时左右编译完成;注意:如果使用的是Java 1.8需要给JVM配置堆与非堆内存,如:export MAVEN_OPTS="-Xmx1.5g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m";
进入Spark根目录下,执行:
./make-distribution.sh --tgz
--tgz 参数是指编译后生成tgz包
- PHadoop 支持Hadoop
-Pyarn :支持yarn
-Phive :支持hive
--with-tachyon:支持tachyon内存文件系统
-name:与--tgz一起用时,name代替Hadoop版本号
./make-distribution.sh --tgz --name 2.6.0 -Pyarn -Phadoop-2.6 -Phive
开始编译检查本地环境,如不存在合适的Scala与Maven就在后台下载;
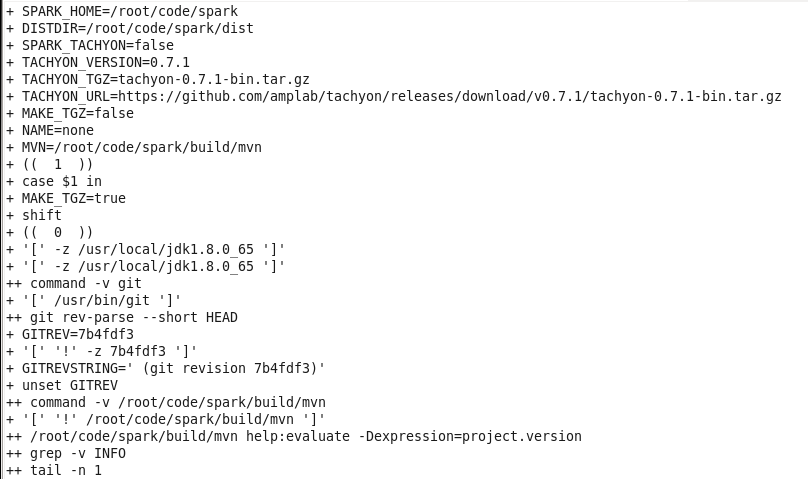
编译中:
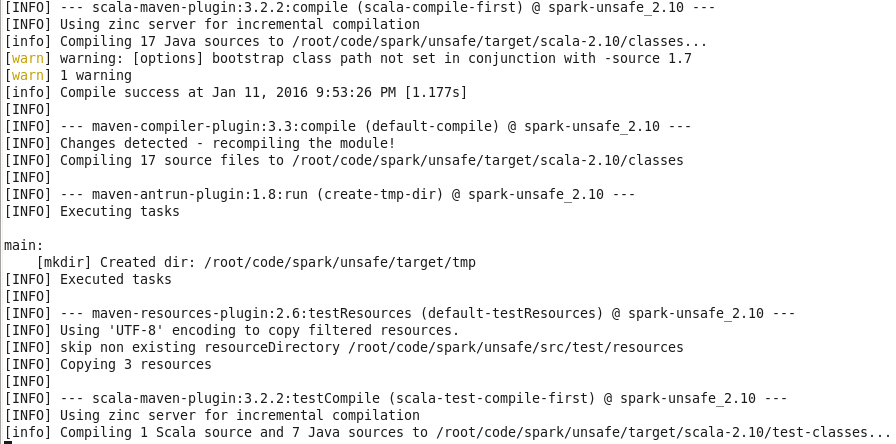
编译完成并打包生成tgz:
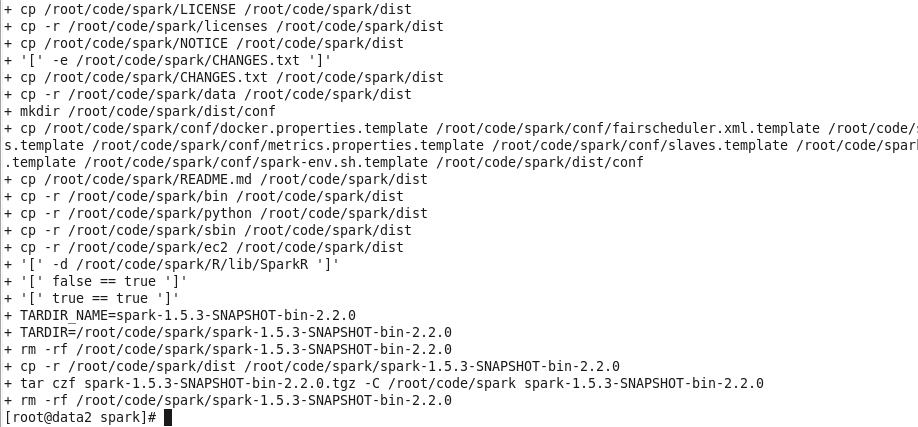
编译完成后把生成的文件拷贝到当前Spark的dist目录中并且打包生成spark-1.5.3-SNAPSHOT-bin-2.2.0.tgz文件;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号