并发模型之——共享内存模型(线程与锁)理论篇
这里我们使用Java的线程与锁来解析共享内存模型;做过java开发并且了解线程安全问题的知道,要使某段代码是线程安全的那必须要满足两个条件:内存可见性、原子性;
内存可见性
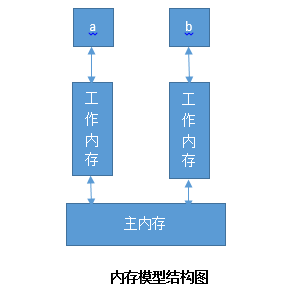
在JVM规定多个线程进行通讯是通过共享变量进行的,而Java内存模型规定了有主内存是所有线程共享的,而各个线程又有自己的工作内存,线程只能访问自己的工作内存中数据;
如:有一个共享变量x,两个线程a、b变量x存储在主内存中然后又两个x的拷贝分别存储在a、b线程的工作内存中线程a、b只能对自己工作内存中的x的拷贝进行操作,不可直接操作主内存;
线程a对x修改时先把值放到自己的工作内存中,然后再把工作内存中的x拷贝更新到主内存中,线程b同样如此;当线程a更新了主内存后线程b刷新工作内存后就能看到a更新后的最新值这就是内存可见性问题;
内存可见性要保证两点:1、线程修改后的共享变量更新到主内存;2、从主内存中更新最新值到工作内存中;
内存可见性:线程对共享变量的修改其他线程可以看到修改后的值;
原子性
当线程引用共享变量时,工作内存中没有共享变量时它会从主内存复制共享变量到自己工作内存中,当工作内存有共享变量时线程可能会从主内存更新也有可能直接使用工作内存中的共享变量;
有代码块,count为共享变量:
1 ++count;
// count初始值为0,这时有a、b线程都执行这行代码,可能有不少人以为线程a , b执行完成后count的值为2,但真实情况是count最终值可能为1也可能为2,因为这里有一个原子性问题;
熟悉Java的都知道在Java中++count非原子操作,流程为:
1、把主内存共享变量count拷贝到工作内存
2、把工作内存中count值+1
3、把结果写回更新回主内存
当只有一个线程时这个操作没有问题;
当有多个线程时有可能出现:
1、 线程a把主内存共享变量count拷贝到工作内存
2、 线程b把主内存共享变量count拷贝到工作内存
3、 线程a把工作内存中count进行+1
4、 线程b把工作内存中count进行+1
5、 线程a把工作内存更新到主内存
6、 线程b把工作内存更新到主内存
a,b线程执行完后最终count的值只是1而不是我们期望得到的2,因为这里出现了多个线程交叉执行导致破坏了程序的有序性,而且count+1操作又不是原子的,所以我们必须要保证这程序的原子性,可以使用Java中的synchronized(同步)或Lock机制来解决;
使用共享内存模型进行并发编程时必须要解决我们上面介绍的两个点:内存可见性、原子性,但现在大部分编程语言原生都支持共享内存模型方式的并发所以我们很容易就可以达到这两个要求;
现在代码的执行要经过多层的优化对指令重排序,如:编译器、处理器等级别的优化,经过这些优化重排序后最终代码执行顺序可能与之前是不一致的,在单线程时中编译器、处理会保持as-if-serial,对不存在数据依赖的进行重排序,所以不会出现重排序问题;但在多线程情况下就会出现问题,不过还好Java中有些机制可以使程序在编译器、处理器优化时会对有数据依赖的禁止指令重排序,如:volatile、synchronized等,所以我们可以很轻松应对这问题;

指令重排序问题
在Java中我们要使代码在多线程中同时满足内存可见性与有序性那就要使用Java提供给我们的同步与锁机制如:synchronized、volatile、Lock、concurrent类等;
优点:共享内存模型(线程与锁)可以说是最常见的并发模型大多数编程语言都原生支持,也适合解决很多问题,通过线程与锁实现起来相对也简单点;
缺点:通过多线程实现并发,而线程耗费的资源比较多,线程总数有限制;通过共享内存来实现多线程通讯又会涉及到锁、竟态、死锁等问题影响程序性能;一不小心就会陷入可见性问题、重排序问题等而且多线程程序不容易测试、维护等;
文章首发地址:Solinx
http://www.solinx.co/archives/179

 浙公网安备 33010602011771号
浙公网安备 33010602011771号