
海南话语音识别模型——模型训练(一)
上篇文章已经介绍了语料数据的预处理,对数据集中的音频数据分别做了重采样、静音切除、降噪以及在Fbank和MFCC中特征提取方式中选择了Fbank对音频数据进行特征提取的方法;在经过上面的处理后已经可以将提取出的音频数据Fbank丢到Transformer中进行训练,但还漏了一个比较重要的数据预处理,音频对应的文本预处理。下面除了介绍文本预处理之外还会介绍模型训练的相关内容;
数据集结构
数据集结构如下,train文件夹下存放训练集wav音频文件,trains.text文件每行对应一个音频文件的中文标注,trans.paths文件每行对应一个wav音频文件的路径其与trains.text文件同一行对应同一个文件标注。
train/x.wav
trains.text
trains.paths
标签文本预处理
在ASR模型中其预测出来的结果文本并不是固定长度的,模型推理出的结果也不会是只是输出中文,它输出的只是一句话或某个词的向量/数字标识,基于此我们需要对语料集中的音频所对应的文本进行数据预处理将其转为向量/数字标识,建立其对应关系。
音频所对应的文本可能是一个句子也可能是一两个词我们就将文本分词(tokenization),在分词,按分词粒度分目前存在三种算法方案:char、word、subword;
char: 对于英文来说由26个字母词表以及其他特殊字符组成,对于中文由5000多个中文字以及特殊组成,词表很简单。
word: 词表由单词、中文词组成,但可能词覆盖得不够全,词表大。
subword: 介于char与word之间分词粒度比char大又比word小,如承上启下,可能分为了:承上、启下两个子词。
目前subword(子词)分词算法主要有三种:Byte Pair Encoding (BPE)、WordPiece、Unigram Language Model。在这里使用了Sentencepiece分词框架,其支持BPE、ULM子词算法、支char, word分词。它使用了Unicode编码字符支持多语言、编解码可逆、可控词表大小。
词表生成
这里使用了Sentencepiece用于生成词表,会生成两个文件,一个为模型文件、另一个为词表文件,具体词表生成代码如下:
pip install sentencepiece
parser = ArgumentParser()
parser.add_argument("--txt_file_path", type=str, required=True)
parser.add_argument("--vocab_size", type=int, required=True)
parser.add_argument("--model_type", type=str, required=True)
parser.add_argument("--model_prefix", type=str, required=True)
parser.add_argument("--sos", type=int, required=True)
parser.add_argument("--eos", type=int, required=True)
parser.add_argument("--unk", type=int, required=True)
parser.add_argument("--norm", type=str, default="identity", help="no normalization")
parser.add_argument("--unk_str", type=str, default=chr(ord('a') + 72))
args = parser.parse_args()
os.makedirs(os.path.dirname(args.model_prefix), exist_ok=True)
spm.SentencePieceTrainer.train(' '.join([
f"--input={args.txt_file_path} ",
f"--model_prefix={args.model_prefix}",
f"--vocab_size={args.vocab_size}",
f"--model_type={args.model_type}",
f"--normalization_rule_name={args.norm}",
f"--control_symbols=<blank>", # for CTC loss
f"--bos_id={args.sos} --eos_id={args.eos} --unk_id={args.unk}", # we don't need to set `pad_id` since it's -1 by default
f"--pad_piece=<ig> --bos_piece=<sos> --eos_piece=<eos> --unk_piece={args.unk_str}",
]))
参数描述
txt_file_path:数据集文本标签文档
model_prefix:模型前缀
model_type:模型类型
vocab_size:词表大小
sos:文本开始标志
eos:文本结束标志
简单看词表就是经过分词后词与数字的映射关系表,词表文件在语音识别模型中至关重要,在ASR训练模型时会将音频文件所对应的中文词汇(子词)所对应的数字编码与音频文件丢到模型中训练。训练处模型完成后语音识别模型在推理时推理出来的也是概率相对较高的一个/一串数字,将数字丢到Sentencepiece分词模型就可得到某个音频所对应的中文。
tokenizer = SubwordTokenizer('hainan.model')
tokenizer.tokenize('槟榔') #获取槟榔获取在词汇表中的编码870
tokenizer.detokenize([870]) #获取编码870在词汇表中对应的词 槟榔
模型推理
由于数据集规模较小,模型泛化能力不太好。通常在语音识别中通过使用词错误率(Word Error Rate) 与字符错误率(Character Error Rate) 这两个指标来了评估语音识别模型性能,观察模型训练的效果。在英文中可以用两者来评估。英文最小单位为Word(单词)中文最小单位为字(字符)所以在中文语音识别中通常用CER来表示字错误率。
WER、CER其原理为编辑距离(Edit distance)中的Levenshtein Distance的计算过程,编辑距离指两个字串之间,由一个转成另一个所需的最少编辑操作次数。操作包括:插入、删除、替换。
还有一个常用指标SER(Sentence Error Rate)句错率描述识别句子错误的概率。
WER:在词维度评估错误率,关注词的插入、删除和替换错误。WER的计算公式是将识别结果中的替换、删除和插入词的数量除以参考文本中的总词数。WER的值越低,说明语音识别系统的性能越好,因为它表示识别出的词序列与参考词序列之间的差异越小。
CER:则是在字符维度上评估错误率,关注的是字符的插入、删除和替换错误。CER的计算公式是将识别结果中的替换(S)、删除(D)和插入(I)字符的数量除以参考文本中的总字符数。CER的值越低,同样表示生成文本与参考文本越接近,系统性能越好。
公式:CER = (S+D+I)/N
S:替换数(识别错误) D:删除数(识别少了) I:插入次数(预测文本比参考文本多出的)
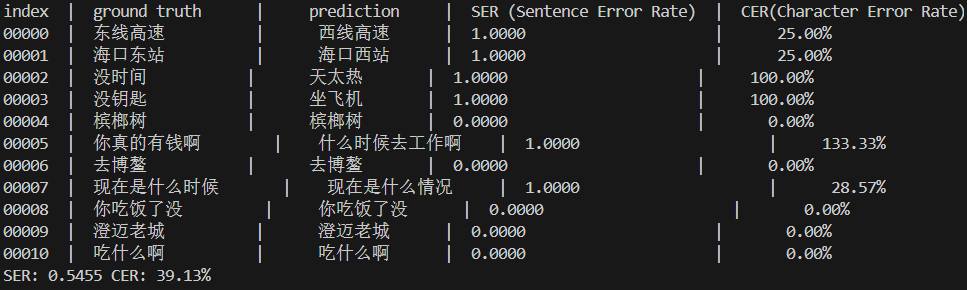
参考文本(真实): 东线高速 预测文本: 西线高速
CER = (1+0+0)/4 = 0.25
参考文本(真实): 你真的有钱啊 预测文本: 什么时候去工作啊
CER = (6+0+2)/6 = 1.33
SER: 识别错误的文本个数除以参考文本总数*100,只要有一个字错都算识别错误。
这里使用了SER(句错率)与字错率(CER)来评估模型训练的性能。
经过评测句错误率(SER)比较高达到54%,字错误率(CER)为36%,两者都比较高不太理想。理想语音识别系统通常准确率要达到95%+以上才会有比较好的可用性。
后续将通过各种方法继续扩大数据集规模、优化训练模型,争取提高海南话语音识别模型的正确率。
参考资料:
Edit distance
WER
Automatic-Speech-Recognition-from-Scratch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号