
RAG知识库之构建知识库图谱
前面几篇文章谈了多种针对RAG的优化如多表示索引(Multi-representation indexing)、Raptor等但其都是存储在向量库中的,这里将介绍一种新的存储模式,图数据库,适合存储数据高度相关的数据。其存储实体与实体间的关系,存储着丰富的关系类型数据,能给RAG知识库带来更精准的上下文信息。
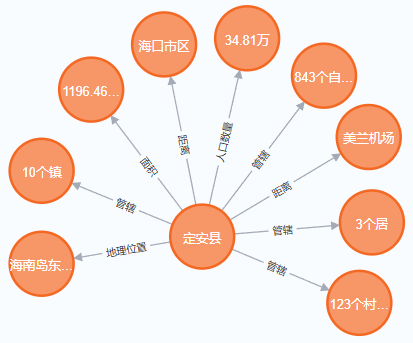
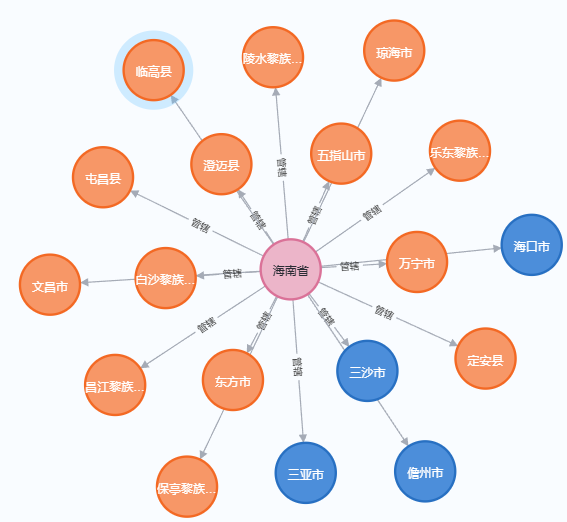
在图数据库中三元组是数据存储的基本单位,它由头实体、关系和尾实体组成,用于表示实体之间的关系。三元组通常用于构建知识图谱,其中每个三元组代表一个事实或断言。例如,在知识图谱中,一个三元组可以表示“(海南,管辖,定安)”这样的关系,其中“海南”是头实体,“管辖”是关系,“定安”是尾实体。
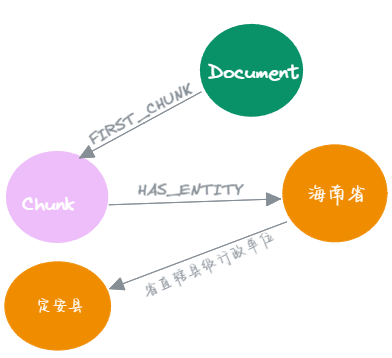
图形数据模型使得节点和关系可以自然地表示实体之间的连接。使用知识图谱后RAG除了能获取到与问题相关的上下文描述外还能得到上下文所包含的实体间的三元组使得其上下文信息更丰富。
但知识图谱的构建并不容易,往往要花很多时间去识别三元组(头实体、关系、尾市体)有了大模型之后三元组的识别会方便很多,但三元组的质量可能还需要人工去识别修正。
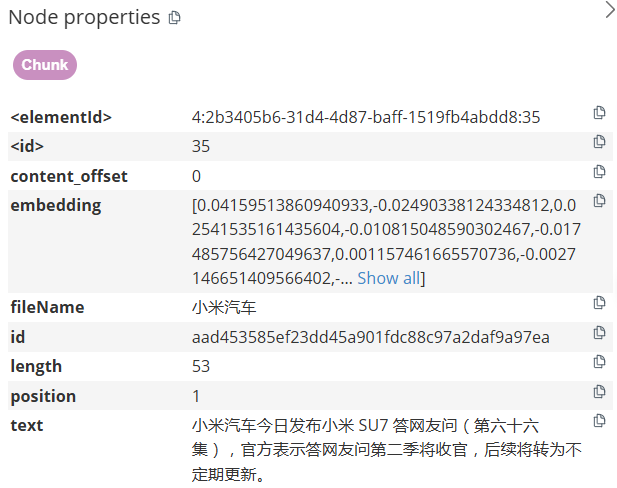
这里先介绍如何用LLM构建neo4j知识图谱,后面再看图谱如何与RAG的结合应用,在这里由于要结合知识图谱RAG使用所以加了两个特殊的节点:Document与Chunk节点,每个文档会有一个Document节点,文档分割后的块为Chunk节点,分割为几块就有几个Chunk节点。
图谱构造
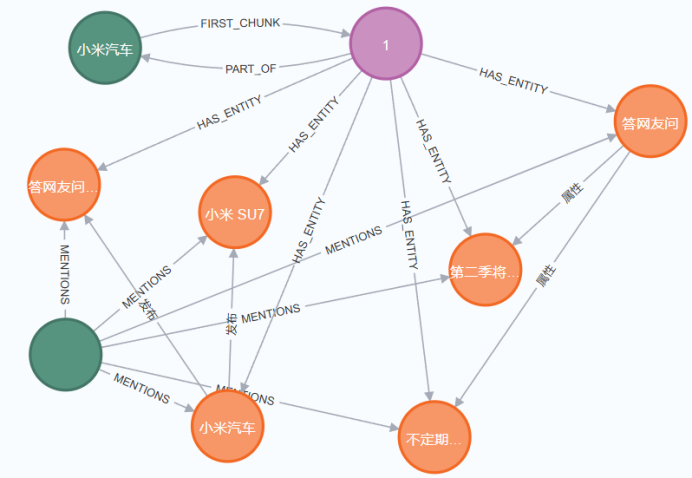
知识图谱构造最重要的工作时识别三元组,这边我们把它交给了LLM来完成,所以剩下了的主要任务是拿到三元组数据集后我们怎么构造图谱的节点及其关系比较使其能够适应与RAG结合的场景。
在RAG的使用场景中通常是抓取Web网页源作为内容或上传的文档作为内容生成知识图谱后,对所上传或抓取得到的内容进行提问,从图谱中搜索问题相关内容作为上下文提交给LLM,让LLM进行回答。这里需要考虑的问题有:文档太大、答案溯源等。
这两个问题在RAG向量库存储时也是比较常见的问题:分割、打标签就能解决。
构建知识图谱主要有这么几个流程:
1、创建原文件节点
主要用于文档溯源其属性包括文件名称等;
2、分割文档并创建分割文档后块节点、创建chunk以及块与源文档的关系
文档分割主要用于解决文件过大问题,主要参数有:chunk_size、 chunk_overlap控制块大小与重叠大小。
3、创建向量索引
为每个chunk创建embeddings属性,为chunk文本内容的词嵌入向量,为chunk块节点embeddings创建向量索引,用于问题上下文的检索。
4、合并chunk
将指定数量的chunk合并组合为一个combined chunks,得到combined chunks列表
如果不合并chunk直接每个chunk生成一个图谱可能会由于文档分割时某些上下文丢失导致生成的图谱可靠性下降,多个chunk合并组合为一个chunk组可能会减少此类情况出现。也可不合并因为文本分割重叠参数从一定程度上也避免了类似情况。也可以不合并chunk直接将每个chunk文档提交给LLM生成返回图谱json,在neo4j中创建图谱并创建源文档节点。
5、生成图谱数据集
将chunks列表遍历提交给LLM,LLM返回节点及节点间关系集后生成图谱以及源文档节点,图谱质量取决与LLM返回数据集的质量;
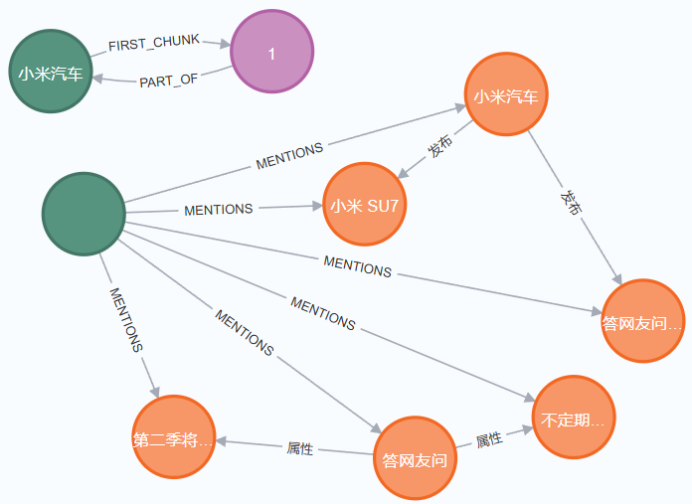
6、创建chunks与实体的关系
7、获取未进行词嵌入的实体节点、并对实体节点的text生成词嵌入向量
大模型现阶段生成知识图谱完全没问题,但是要高质量的图谱恐怕还需要人为介入对数据进行清洗、修复重复项错误数据、验证完整性等。不过对于只是需要将知识图谱作为RAG知识库的内容引用来说有一定影响,但只要不是胡说八道的错误视乎影响不是特别大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号