RAG知识库之针对长文档的Raptor索引
在现有的朴素RAG应用中其只是简单的对文档进行分块后存储的向量库中,然后在使用是根据 提问问题 从查询向量库中查询相识度较高的文档快作为问题上下文提交到LLM让其根据上下文去回答用户所提问的问题。对于小文本可以直接将整个文档作为上下文或使用上篇文章所提到的多表示索引(Multi-representation indexing)进行Context上下文的优化处理。
朴素RAG分块大小、文本叠加值设置都对向量检索质量有着重要的影响,如文档太多可能会丢失长尾知识,缺乏对整个文档上下文的理解从而影响到RAG的质量;如针对某篇长小说文档提问主角出生经历对其结尾的结局产生了什么影响?通常小说前面几张描述的是主角出生与经历结尾描述的是其结局,文档过长不可能将整个文档作为问题上下文,异无法理解整篇文档,而只是使用 从向量库中检索到相识度最高的top K文本块最为问题上下文;
Raptor使用树形结构来捕获文本的高层级和低层级细节,其对文本块进行递归聚类、生成聚类的文本摘要总结自下而上生成一棵树,所生成的 Raptor能够作为问题上下文代表了不同级别的问题,可以回答不同层级的问题。
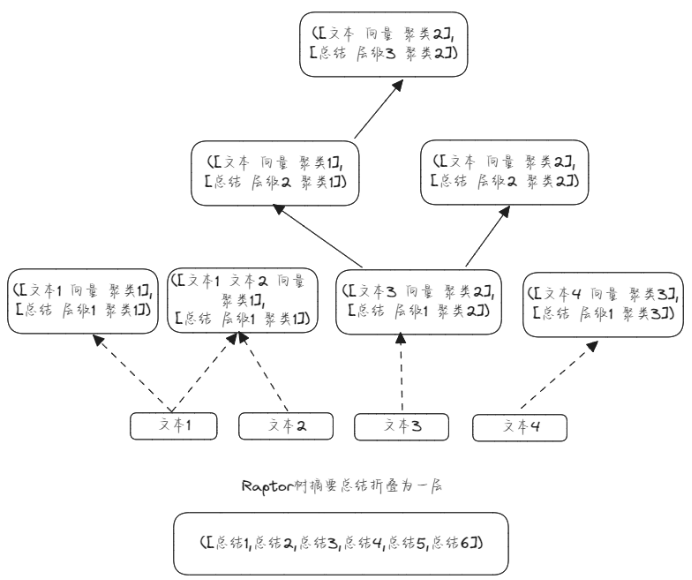
图为Raptor所生成的树结构,从下往上递归生成,此树为三个层级从文本块上一层级算起。文本1、文本2、文本3、文本4为叶子结点使用长文档分割而成,先对文本块进行文本词嵌入,然后使用UMAP对嵌入向量进行降维接着使用高斯混合模型(GMM) 对降维后的向量进行聚类,嵌入词向量通常维度较高直接使用GMM可能会表现不佳所以须先 UMAP(Uniform Manifold Approximation and Projection)降维。聚类时使用软聚类,因为每个文本块通常包含多个主题信息所以一个文本块属于多个聚类主题更加合理,保证总结摘要包含多个主题信息。
1、对文档初始分割后的文本块嵌入向量后进行降维后使用GMM聚类
2、合并同一个聚类中的文本块使用LLM对该聚类文本块进行总结摘要
3、如生成的聚类数大于1与层级小于指定层级则重复1、2、3、操作递归对上层级 生成的总结摘要进行:嵌入、聚类、生成摘要;
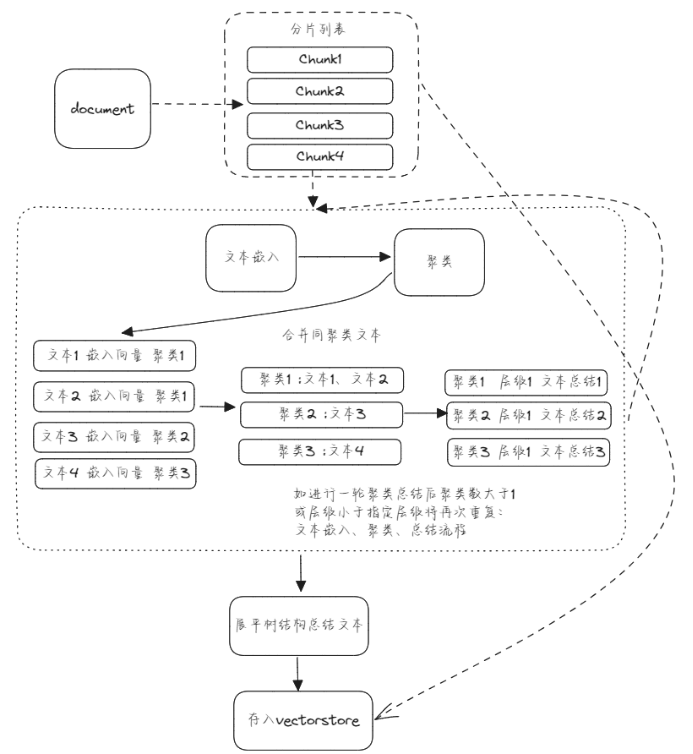
此图为Raptor算法总体流程与层级1内部数据结构图具体流程如下:
1、先将长文档分割为文本块。
2、对文本块进行此嵌入,UMAP降维后使用GMM生成聚类。
3、合并同聚类文本块,使用LLM对每个聚类文本块进行总结摘要。
4、根据条件判断是否递归重复1、2、3流程。
5、Raptor树折叠展平获取总结摘要列表写入向量存储。
6、原始文本块写入向量存储。
而本篇文章所描述的RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)正能够避免出现这种情况,可以说其是为了大文本而生的。Raptor通过递归的对长文本块进行嵌入、聚类总结从而构造了一棵具有对该文档具有不同层级总结的树结构从而能够更全面的理解与整合该长文档信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号