
小林同学智能AI大模型语音助手
闲来无事,想起吃灰的树莓派拿来做点什么,貌似去年还专门买了个麦克风还没怎么用过。正好拿来做个类似小爱智能语音助手的小林同学,现在智能助手不接入大模型都不好意思说出来,当然小林同学没有小爱同学的米家生态功能,后续如果加入多模态图片识别貌似会更有点意思。
智能助手涉及到的技术主要由:语音离线唤醒、录音、语音识别(Speech-to-Text)、TTS、大模型,在现在这个时候整合这些技术做出个Demo的玩具并没有多少难度。做了些技术调研还有验证马上就动手。下面简单介绍硬件配置、主要代码实现;
树莓派配置
alsamixer 配置 声音大小等
aplay -l 查看设备情况
修改/etc/asound.conf或.asoundrc
vim .asoundrc
配置默认设备
defaults.pcm.card 1 默认播放设备
defaults.ctl.card 0 默认控制设备
sudo /etc/init.d/alsa-utils restart
录音 arecord -D hw:2,0 -t wav -c 1 -r 44100 -f S16_LE test.wav
-D hw:2,0 第二个声卡的第一个设备 -f S16_LE 指定了采样格式为 16 位小端 -r 44100 设置了采样率为 44100Hz -c 1 表示使用单声道录音
播放 aplay test.wav
语音唤醒—》录音—》语音识别—》大模型—》TTS—》语音播报
语音唤醒
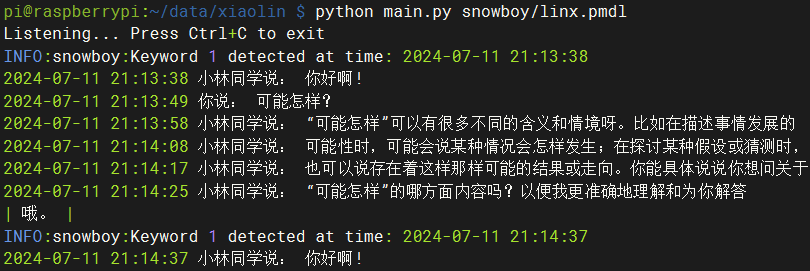
选了开源的Snowboy作为语音唤醒的实现,Snowboy非常适合在树莓派上使用,非常轻量反应很灵敏。它的唤醒为离线实现并不依赖网络,还可以定制个人唤醒词,如小林同学、Alexa、小爱同学等你想要的任何唤醒词,使用也非常简单。
录制唤醒词:https://snowboy.hahack.com
from snowboy import snowboydecoder
def hello_callback():
communicate = edge_tts.Communicate("你好啊",voice)
asyncio.run(communicate.save("./hello.wav"))
playsound("hello.wav")
detector.start(detected_callback=hello_callback,
interrupt_check=interrupt_callback,
sleep_time=0.03)
detector.terminate()
启动程序 python main.py snowboy/linx.pmdl
语音录制
最初选了Sounddevice作为录制语音的框架,在录制固定长度音频是并没有问题生成音频文件没什么杂音,但在加了阈值听到声音才开始录制没有声音停止录制的逻辑之后生成音频有嘟嘟嘟嘟的杂音,搞了一两个小时没有解决换了技术方案。
其实AI助手也不需要听到声音开始录制,只需要在唤醒时录制即可。最终选择了SpeechRecognition作为技术方案,录制效果也不错。
import speech_recognition as sr
import baidu
import json
def rec(rate=16000):
try:
r = sr.Recognizer()
file = "recording.wav"
with sr.Microphone(sample_rate=rate) as source:
audio = r.listen(source,timeout=12,phrase_time_limit=6)
with open(file, "wb") as f:
f.write(audio.get_wav_data())
text = json.loads(baidu.tts(file))
if(text is not None):
return text.get("result")[0]
else:
return None
except sr.WaitTimeoutError:
print("录音超时,没有检测到声音。")
except Exception as e:
print(f"发生错误: {e}")
语音识别
想着搞离线语音识别最近有一个OpenAi开源的神器Whisper Live不仅可以对视频进行转为文本还可以进行实时视频转录,如生成视频字幕。在笔记本上试了下效果的确不错,但由于算力硬件原因,在树莓派上效果并不理想一个几秒语音转录就要几十秒。没办法最终换成了百度的在线语音识别。
TTS(Text To Speech)
文本转语音选择了微软开源的Edge-TTS效果还不错,在树莓派上体验性能还算能接受。
import edge_tts
def generater_wav(msg:str):
communicate = edge_tts.Communicate(msg,voice)
asyncio.run(communicate.save("./temp.wav"))
playsound("temp.wav")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号