RAG知识库的可靠性评估(二)
上篇文件介绍了RAG优化与评估的基本概念,以及使用TruLens-Eval在没有Ground-truth的情况下评估RAG应用。本篇文件主要是使用Ragas对RAG应用进行评估;
使用了Gagas生成合成测试数据集,在只有知识库文档并没有Ground-truth(真实答案)的情况下让想评估该知识库文档应用到RAG的的效果如何,这时可以用Ragas生成包含question、context、Ground-truth(真实答案)的数据集。即可在有Ground-truth(真实答案)的情况下评估RAG。
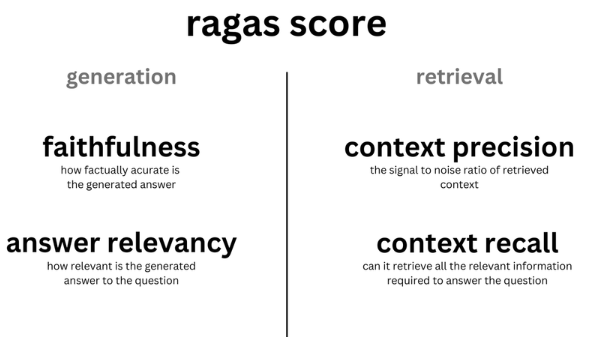
RAG包含两个主要流程,向量检索、响应生成。Ragas把这两个流程评估指标分为:评价检索包括context_relevancy和context_recall)和生成指标(faithfulness和answer_relevancy)。
Context_relevancy:上下文精度,上下文Context与Ground-truth的相关性越高RAG效果越好。
Context_recall:上下文召回率,是否检索到回答问题所需的所有相关信息。根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。
Faithfulness:答案的事实准确性,答案中提出的所有基本事实都可以从给定的上下文context中推断出来,则生成的答案被认为是忠实的。
Answer Relevance: 答案相关性,度量LLM的Response答案与Query提问的相关度。如分低,可能反应了回答不对题。
提示词(prompt)自动适配
在Ragas中默认的Prompt是英文的,如果直接使用生成数据集会出现一些英文数据,所以需要将Ragas内置的Prompt翻译为中文后使用。在Ragas中也提供了Prompt自动适配其他语言的支持;
noun_extractor = Prompt(
name="noun_extractor",
instruction="Extract the noun from given sentence",
examples=[{
"sentence":"The sun sets over the mountains.",
"output":{"nouns":["sun", "mountains"]}
}],
input_keys=["sentence"],
output_key="output",
output_type="json"
)
#生成中文提示词
adapted_prompt =
qa_prompt.adapt(language="chinese",llm=openai_model)
#保存提示词
adapted_prompt.save()
print(adapted_prompt.to_string())
#加载指定提示词
Prompt._load(name="question_generation",language="chinese",cache_dir='/home/linx/.cache/ragas')
Ragas使用LLM将提示词翻译成为目标语言提示词,还可以保存所翻译的提示词到磁盘,默认路径为:/home/linx/.cache/ragas,保存完成后后续可以直接加载使用;
合成测试数据集
在Ragas中生成合成数据集也会是使用LLM配合指定的Prompt用于数据集的生成,还可以生成不同难度级别的问题,生成的数据集按不同难度级别分布,给定LLM、配置文档集即可,其生成原理受到Evol-Inform启发。Ragas中为question_type定义了simple、reasoning、multi_context、conditional四种级别的问题,保证了数据集的多样性。
simple:简单问题,生成的问题在上下文中得到解答。
reasoning:推理问题,该问题的答案从上下文中推理得到。
multi_context:多上下文问题,问题经过重写,问题解答需要从多个上下文中获取信息。
conditional:条件问题,问题经过重写,通过影响上下文的条件使问题复杂化。
testset_generator = TestsetGenerator.from_langchain(
generator_llm=generator_llm,
critic_llm=generator_llm,
embeddings=embedding_model
)
language = "chinese"
testset_generator.adapt(language,evolutions=[simple,
reasoning,conditional,multi_context])
testset_generator.save(evolutions=[simple, reasoning,
multi_context,conditional])
distributions = {
simple:0.4
reasoning:0.2,
multi_context:0.2,
conditional:0.2
}
synthetic_dataset =
testset_generator.generate_with_langchain_docs(
documents=load_documents(),
test_size=10,
with_debugging_logs=True
)
from datasets import Dataset
print(synthetic_dataset.to_pandas().head())
print('-------------------')
Dataset.save_to_disk(synthetic_dataset.to_dataset(),'testset')
评估合成测试数据集
生成的数据集没有经过解答未包含answer字段,这里打算把ground_truth(真实答案)当做answer。
from datasets import load_from_disk,Dataset
#评估生成的数据集
# loading the V2 dataset
ds = load_from_disk("testset")
df = ds.to_pandas()
#复制ground_truth列,由于数据集不存在answer列,将ground_truth复制为该列
answer = df['ground_truth'].copy()
df['answer'] =answer
new_dataset = Dataset.from_pandas(df)
# ds=new_dataset.to_pandas()
# ds.head()
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
result = evaluate(
llm=generator_llm,
dataset=new_dataset,
embeddings=embedding_model,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
df = result.to_pandas()
print(df)
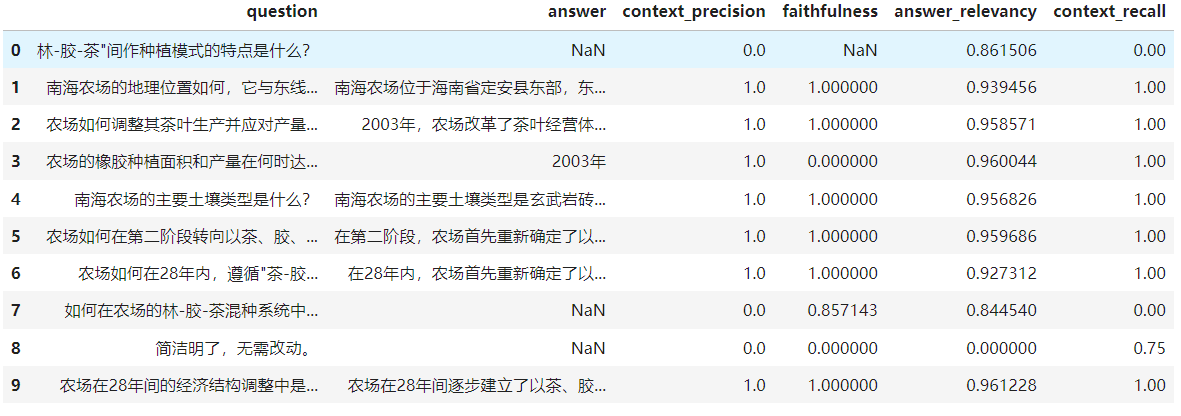
对数据集的评估结果指标如下,这里只列出了部分字段:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号