Ray一个通用分布式计算框架基本使用
Ray一个开源的通用分布式计算框架,支持传统的并行任务并支持AI模型的分布式训练,分布式任务包括有状态与无状态任务,Ray能够快速的构建分布式系统,支持按需申请CPU或GPU;Ray提供了统一的接口提供了基于任务的并行计算与基于行动器的计算,前者通常用于无状态的任务后者用于有状态的任务;Ray为一个具有高可扩展性、容错性的分布式计算集群框架;集群即可逻辑运行亦支持K8S生态与Docker环境运行;
Ray架构分为应用层和系统层组成,应用层提供了Ray API,系统层保障Ray的高可扩展和容错性;
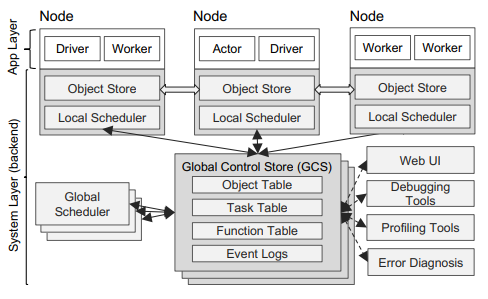
应用层对应了三种类型的进程:驱动进程、工作器进程、行动器进程组成;
驱动器 (Driver ): 执行用户程序的进程,所有操作都需要由主进程来驱动。
工作器 (Worker ): 执行由驱动器或其他工作器调用的任务(远程函数)的无状态的进程。工作器是在系统层分配任务时自动启动的。当声明一个远程函数时,该函数将被自动发送到所有的工作器中。在同一个工作器中,任务是串行地执行的,工作器并不维护其任务与任务之间的局部状态,即在工作器中,一个远程函数执行完后,其局部作用域的所有变量将不再能被其他任务所访问。
行动器 (Actor ): 行动器被调用时只执行其所暴露的方法。行动器由工作器或驱动器显式地进行实例化。与工作器相同的是,行动器也会串行地执行任务,不同的是行动器上执行的每个方法都依赖于其前面所执行的方法所变更的状态。
三种进程在代码中的体现:
def f(x):
# 工作器进程
return x * x
@ray.remote
class Counter(object):
def __init__(self):
# 行动器进程
self.value = 0
def increment(self):
#行动器进程
self.value += 1
return self.value
if __name__ == "__main__":
#驱动器进程
object_ref = f.remote(2)
assert ray.get(object_ref) == 4
counter = Counter.remote()
ref = counter.increment.remote()
assert ray.get(ref) == 1
系统层由三个主要部件组成:全局控制存储器 (Global Control Store)、分布式调度器 (Distributed Scheduler)和分布式对象存储器 (Distributed Object Store)。这些部件在横向上是可扩展的,可以增减这些部件的数量,同时还具有一定容错性。
Ray安装
Ray框架有多个组成部分,可单独或组合安装,组件包括Ray Core、Ray Data、Ray Data、Ray Train、Ray Tune、Ray Serve、Dashboard等;其中Ray Core提供了分布式应用的核心的基础部分的支持如Tasks、Actors、Objects等;Ray Train是一个可扩展的机器学习库,用于分布式训练和微调。其支持PyTorch、TensorFlow、Keras、XGBoost、LightGBM、Hugging Face Transformers等框架;
pip install -U "ray[default]" Core, Dashboard, Cluster Launcher
pip install -U "ray[train]" Core, Train
pip install -U "ray[all]" Core, Dashboard, Cluster Launcher, Data, Train, Tune, Serve, RLlib
Ray集群
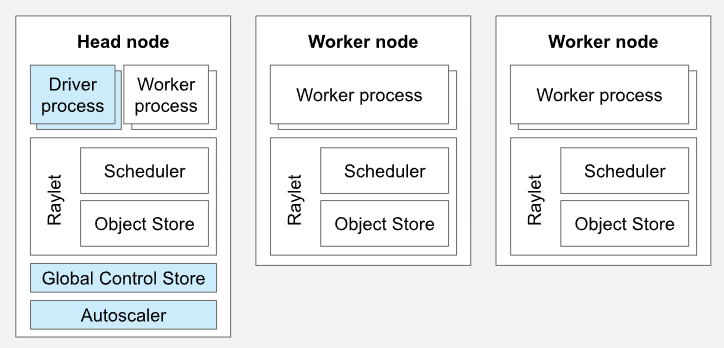
Ray实现了工作负载从笔记本电脑到大型集群的无缝扩展。Ray只需调用Ray.init即可在单机上开箱即用;但如要在多个节点上运行Ray应用程序,必须首先部署Ray集群。
Ray集群是由一组工作节点连接到一个公共Ray Head节点组成。Ray集群可以是固定大小的,也可以根据集群上运行的应用程序请求的资源自动上下缩放。Head节点运行集群控制进程如自动收缩、GCS、驱动器等,每个节点都有一组助手进程用于分布式调度与内存管理;
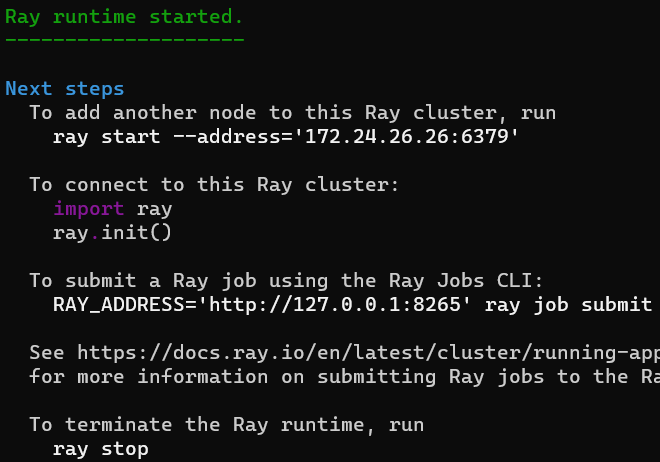
Ray集群启动
ray start --head
启动Work节点
ray start --address='127.0.0.1:6379'
节点退出
ray stop
集群监控地址:http://127.0.0.1:8265
Resource Status
Usage:
0.0/36.0 CPU
0B/17.76GiB memory
0B/8.04GiB object_store_memory
Demands:
(no resource demands)
往集群提交任务
ray.init(address='ray://127.0.0.1:10001')
@ray.remote
def sum(a):
return a * 2
ret = ray.get(h.remote(100))
print(ret)
Ray两种计算模式:任务Task、行动器Actor;
任务Task
任务执行为无状态的,任务无法修改作为本地变量传入的值,Ray远程函数为无副作用的;
编写任务流程:
1、注册任务:在注册为任务的函数上添加@ray.remote修饰器
2、提交任务:在调用@ray.remote修饰器的函数时需带上.remote()
3、非阻塞提交:提交任务后立即返回ObjectRef对象
4、阻塞获取结果:通过ray.get传入返回的ObjectRef对象获取函数返回值
行动器Actor
有状态的的计算任务,行动器方法调用可能会修改行动器状态,属于有副作用的函数,因此同一行动器下的方法需按顺序串行调用;
编写行动器流程:
1、注册行动器:在注册行为器的类上加上@ray.remote装饰器
2、实例化行动器:实例化类实例时需在类名后加上.remote()
3、提交方法调用:调用行动器方法需加上.remote()
4、非阻塞提交:提交后返回一个ObjectRef对象,同一行动器实例下方法会按提交顺序执行
5、阻塞获取结果:通过ray.get传入ObjectRef获取结果
class Computer(object):
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
computer = Computer.remote()
ref = computer.increment.remote()
ray.get(ref)
下面程序会提交三个任务:
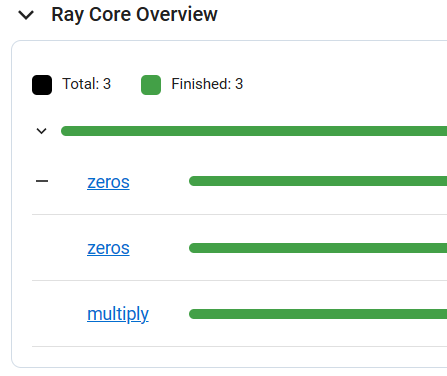
import ray
@ray.remote
def multiply(x,y):
return np.dot(x,y)
@ray.remote
def zeros(size):
return np.zeros(size)
x = zeros.remote((10,10))
y = zeros.remote((10,10))
z = multiply.remote(x,y)
z = ray.get(z)
print(z)
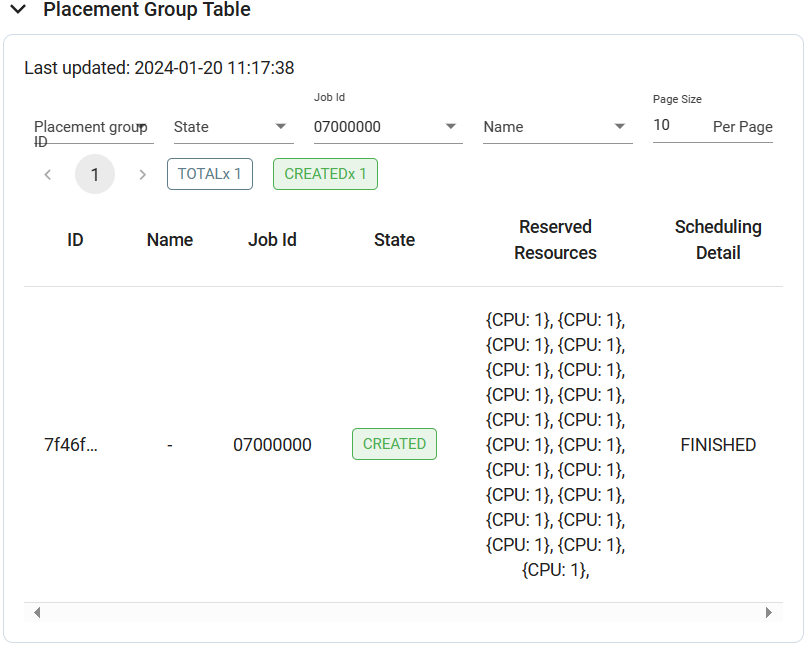
单节点12CPU,申请超过12CPU时任务就会分布到其他节点上,如申请20CPU,任务20个epochs,那20个epochs将分布到20CPU上执行,申请20CPU时Ray会申请创建21个Actor其中20个为RayTrainWorker训练工作用;
参考资料
https://arxiv.org/pdf/1712.05889.pdf
Ray v2 Architecture - Google 文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号