
在树莓派中跑迷你Llama2中文模型
OpenAI的Karpathy利用周末搞了一个迷你Llama2项目llama2.c用500行C语言实现无任何依赖项的推理程序,此项目在github发布以来衍生出了基于各种语言的迷你Llama推理实现llama2.go、llama2.java、llama2.py等等;
但该项目原本的模型并不支持中文,最近正好看到一个基于llama2的中文训练模型;想着把它跑在树莓派上速度会怎样;
使用Go实现进行模型推理,该在树莓派中的Llama2 迷你中文模型,模型大小为15M使用的数据集为TinyStories 英文翻译后的数据但仅翻译了TinyStories 的部分数据目前为1M,中文词表使用UTF-8编码所以每个汉字为3个字节;
在树莓派中推理:
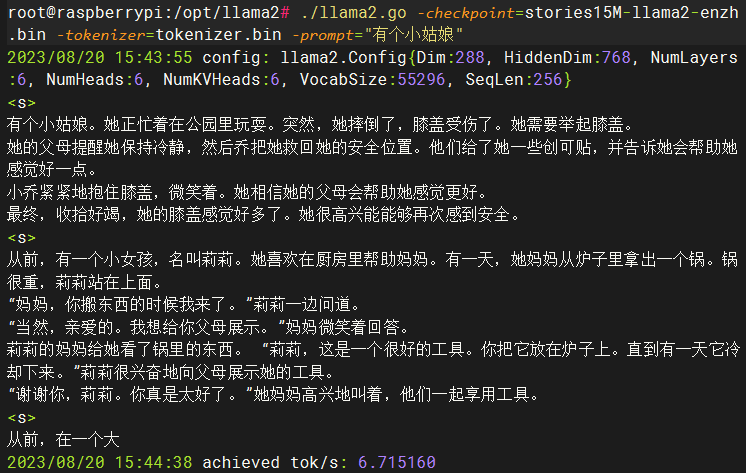
./llama2.go -checkpoint=stories15M-llama2-enzh.bin -tokenizer=tokenizer.bin -prompt="有个小姑娘"
2023/08/20 15:43:55 config: llama2.Config{Dim:288, HiddenDim:768, NumLayers:6, NumHeads:6, NumKVHeads:6,VocabSize:55296, SeqLen:256}
有个小姑娘。她正忙着在公园里玩耍。突然,她摔倒了,膝盖受伤了。她需要举起膝盖。
她的父母提醒她保持冷静,然后乔把她救回她的安全位置。他们给了她一些创可贴,并告诉她会帮助她感觉好一点。
小乔紧紧地抱住膝盖,微笑着。她相信她的父母会帮助她感觉更好。
最终,收拾好竭,她的膝盖感觉好多了。她很高兴能能够再次感到安全。
可以看到在树莓派中跑这个150万参数的llama2模型Tokens/s速度只有每秒不到10;
由于TinyStories只是短篇故事数据集,加上中文翻译数据集也不完全,模型参数也只有百万规模所以讲故事的效果并不好;
Go推理fork于:https://github.com/nikolaydubina/llama2.go
模型、词表来源:https://github.com/chenyangMl/llama2.c-zh
文章首发地址:https://mp.weixin.qq.com/s/3jHg6kYFnd45JUZq9WK3sw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号