谈谈我对服务熔断、服务降级的理解 专题
伴随着微服务架构被宣传得如火如荼,一些概念也被推到了我们面前(管你接受不接受),其实大多数概念以前就有,但很少被提的这么频繁(现在好像不提及都不好意思交流了)。
想起有人总结的一句话,微服务架构的特点就是:“一解释就懂,一问就不知,一讨论就吵架”。
其实对老外的总结能力一直特别崇拜,Kevin Kelly、Martin Fowler、Werner Vogels……,都是著名的“演讲家”。正好这段时间看了些微服务、容器的相关资料,也在我们新一代产品中进行了部分实践,回过头来,再来谈谈对一些概念的理解。
今天先来说说“服务熔断”和“服务降级”。为什么要说这个呢,因为我很长时间里都把这两个概念同质化了,不知道这两个词大家怎么理解,一个意思or有所不同?现在的我是这么来看的:
- 在股票市场,熔断这个词大家都不陌生,是指当股指波幅达到某个点后,交易所为控制风险采取的暂停交易措施。相应的,服务熔断一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。
- 大家都见过女生旅行吧,大号的旅行箱是必备物,平常走走近处绰绰有余,但一旦出个远门,再大的箱子都白搭了,怎么办呢?常见的情景就是把物品拿出来分分堆,比了又比,最后一些非必需品的就忍痛放下了,等到下次箱子够用了,再带上用一用。而服务降级,就是这么回事,整体资源快不够了,忍痛将某些服务先关掉,待渡过难关,再开启回来。
所以从上述分析来看,两者其实从有些角度看是有一定的类似性的:
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
而两者的区别也是明显的:
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
- 实现方式不太一样,这个区别后面会单独来说;
当然这只是我个人对两者的理解,外面把两者归为完全一致的也不在少数,或者把熔断机制理解为应对降级目标的一种实现也说的过去,可能“一讨论就吵架”也正是这个原因吧! 概念算是说完了,避免空谈,我再总结下对常用的实现方法的理解。对于这两个概念,号称支持的框架可不少,Hystrix当属其中的佼佼者。 先说说最裸的熔断器的设计思路,下面这张图大家应该不陌生(我只是参考着又画了画),简明扼要的给出了好的熔断器实现的三个状态机:
- Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
- Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
- Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
那Hystrix,作为Netflix开源框架中的最受喜爱组件之一,是怎么处理依赖隔离,实现熔断机制的呢,他的处理远比我上面说个实现机制复杂的多。
一起来看看核心代码吧,我只保留了代码片段的关键部分:
public abstract class HystrixCommand<R> extends AbstractCommand<R> implements HystrixExecutable<R>, HystrixInvokableInfo<R>, HystrixObservable<R> { protected abstract R run() throws Exception; protected R getFallback() { throw new UnsupportedOperationException("No fallback available."); } @Override final protected Observable<R> getExecutionObservable() { return Observable.defer(new Func0<Observable<R>>() { @Override public Observable<R> call() { try { return Observable.just(run()); } catch (Throwable ex) { return Observable.error(ex); } } }); } @Override final protected Observable<R> getFallbackObservable() { return Observable.defer(new Func0<Observable<R>>() { @Override public Observable<R> call() { try { return Observable.just(getFallback()); } catch (Throwable ex) { return Observable.error(ex); } } }); } public R execute() { try { return queue().get(); } catch (Exception e) { throw decomposeException(e); } }
HystrixCommand是重重之重,在Hystrix的整个机制中,涉及到依赖边界的地方,都是通过这个Command模式进行调用的,显然,这个Command负责了核心的服务熔断和降级的处理,子类要实现的方法主要有两个:
- run方法:实现依赖的逻辑,或者说是实现微服务之间的调用;
- getFallBack方法:实现服务降级处理逻辑,只做熔断处理的则可不实现;
public class TestCommand extends HystrixCommand<String> { protected TestCommand(HystrixCommandGroupKey group) { super(group); } @Override protected String run() throws Exception { //这里需要做实际调用逻辑 return "Hello"; } public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException { TestCommand command = new TestCommand(HystrixCommandGroupKey.Factory.asKey("TestGroup")); //1.这个是同步调用 command.execute(); //2.这个是异步调用 command.queue().get(500, TimeUnit.MILLISECONDS); //3.异步回调 command.observe().subscribe(new Action1<String>() { public void call(String arg0) { } }); } }
细心的同学肯定发现Command机制里大量使用了Observable相关的API,这个是什么呢?原来其隶属于RxJava,这个框架就不多介绍了 --- 响应式开发,也是Netflix的作品之一,具体大家可参考这系列博客,我觉得作者写的很通俗:http://blog.csdn.net/lzyzsd/article/details/41833541/
接着呢,大家一定会问,那之前说的熔断阈值设置等,都在哪块做的呢?再来看看另一块核心代码:
public abstract class HystrixPropertiesStrategy { public HystrixCommandProperties getCommandProperties(HystrixCommandKey commandKey, HystrixCommandProperties.Setter builder) { return new HystrixPropertiesCommandDefault(commandKey, builder); } ...... }
这个类作为策略类,返回相关的属性配置,大家可重新实现。而在具体的策略中,主要包括以下几种策略属性配置:
- circuitBreakerEnabled:是否允许熔断,默认允许;
- circuitBreakerRequestVolumeThreshold:熔断器是否开启的阀值,也就是说单位时间超过了阀值请求数,熔断器才开;
- circuitBreakerSleepWindowInMilliseconds:熔断器默认工作时间,超过此时间会进入半开状态,即允许流量做尝试;
- circuitBreakerErrorThresholdPercentage:错误比例触发熔断;
- ......
属性很多,这里就不一一说明了,大家可参考HystrixCommandProperties类里的详细定义。还有一点要着重说明的,在熔断器的设计里,隔离采用了线程的方式(据说还有信号的方式,这两个区别我还没搞太明白),处理依赖并发和阻塞扩展,示意图如下:
如上图,好处也很明显,对于每个依赖都有独立可控的线程池,当然高并发时,CPU切换较多,有一定的影响。
啰嗦了一堆,最后总结一下,我认为服务熔断和服务降级两者是有区别的,同时通过对Hystrix的简单学习,了解了其实现机制,会逐步引入到我们的产品研发中。当然还有好多概念:服务限流、分流,请求与依赖分离等,后面有时间一一与大家分享。
http://blog.csdn.net/guwei9111986/article/details/51649240
http://www.primeton.com/read.php?id=2230&his=1

Sentinel: 分布式系统的流量防卫兵
Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:

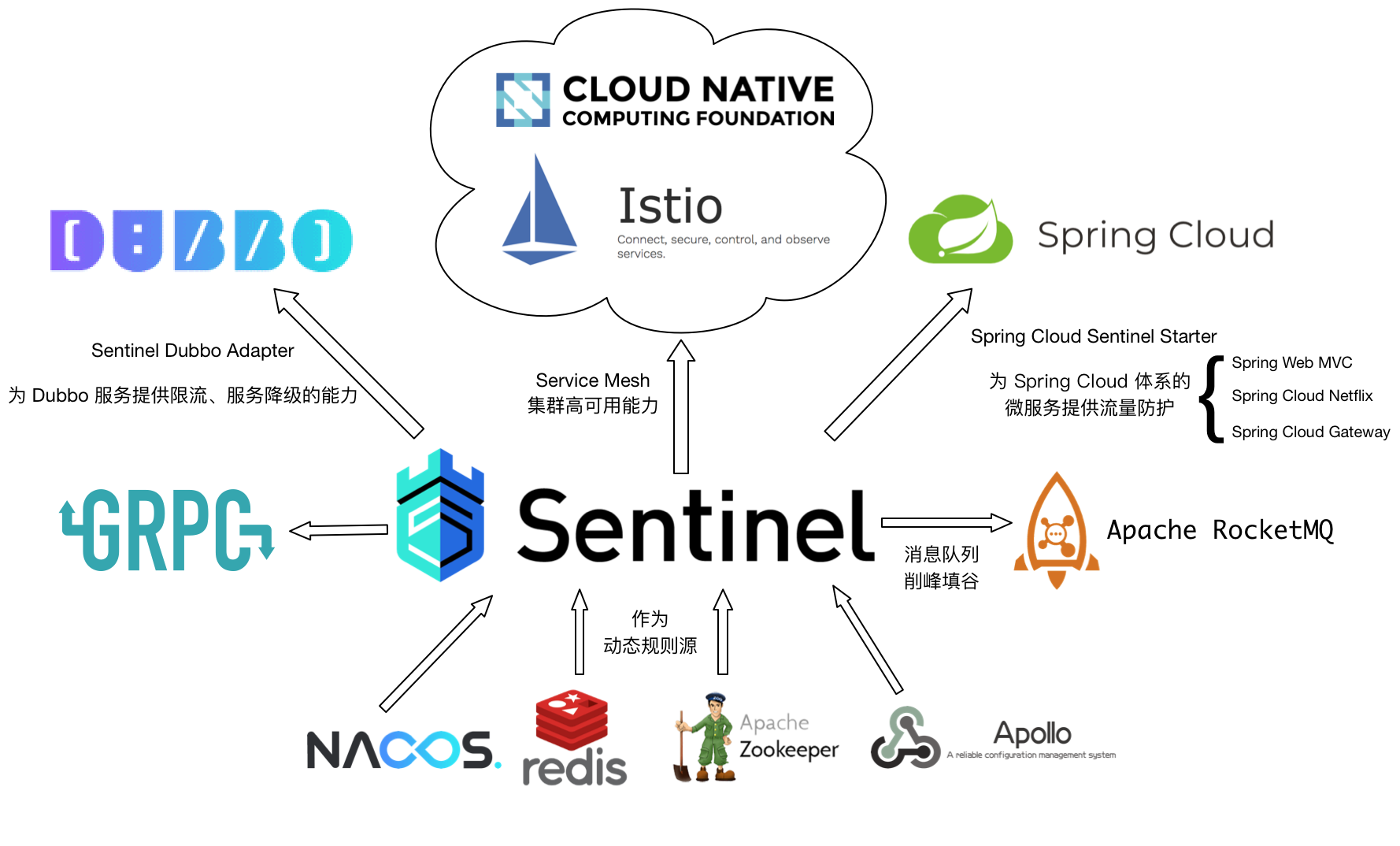
Sentinel 的开源生态:
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Quick Start
1.1 公网Demo:
如果你想最快的了解Sentinel在做什么,你可以通过Sentinel 新手指南 来运行一个例子,并且能在控制台上看到最直观的监控,流控效果等。
1.2 手动接入Sentinel以及Dashboard
下面的例子将展示应用如何三步接入 Sentinel。同时,Sentinel 也提供所见即所得的控制台,可以实时监控资源以及管理规则。
STEP 1. 在应用中引入Sentinel Jar包
如果应用使用 pom 工程,则在 pom.xml 文件中加入以下代码即可:
<dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-core</artifactId> <version>x.y.z</version> </dependency>
注意: Sentinel 仅支持 Java 6 或者以上版本。如果您未使用依赖管理工具,请到 Maven Center Repository 直接下载 JAR 包。
STEP 2. 定义资源
接下来,把需要控制流量的代码用 Sentinel API SphU.entry("HelloWorld") 和 entry.exit() 包围起来即可。在下面的例子中,我们将 System.out.println("hello wolrd"); 作为资源,用 API 包围起来。参考代码如下:
public static void main(String[] args) { initFlowRules(); while (true) { Entry entry = null; try { entry = SphU.entry("HelloWorld"); /*您的业务逻辑 - 开始*/ System.out.println("hello world"); /*您的业务逻辑 - 结束*/ } catch (BlockException e1) { /*流控逻辑处理 - 开始*/ System.out.println("block!"); /*流控逻辑处理 - 结束*/ } finally { if (entry != null) { entry.exit(); } } } }
完成以上两步后,代码端的改造就完成了。当然,我们也提供了 注解支持模块,可以以低侵入性的方式定义资源。
STEP 3. 定义规则
接下来,通过规则来指定允许该资源通过的请求次数,例如下面的代码定义了资源 HelloWorld 每秒最多只能通过 20 个请求。
private static void initFlowRules(){ List<FlowRule> rules = new ArrayList<>(); FlowRule rule = new FlowRule(); rule.setResource("HelloWorld"); rule.setGrade(RuleConstant.FLOW_GRADE_QPS); // Set limit QPS to 20. rule.setCount(20); rules.add(rule); FlowRuleManager.loadRules(rules); }
完成上面 3 步,Sentinel 就能够正常工作了。更多的信息可以参考 使用文档。
STEP 4. 检查效果
Demo 运行之后,我们可以在日志 ~/logs/csp/${appName}-metrics.log.xxx 里看到下面的输出:
|--timestamp-|------date time----|--resource-|p |block|s |e|rt
1529998904000|2018-06-26 15:41:44|hello world|20|0 |20|0|0
1529998905000|2018-06-26 15:41:45|hello world|20|5579 |20|0|728
1529998906000|2018-06-26 15:41:46|hello world|20|15698|20|0|0
1529998907000|2018-06-26 15:41:47|hello world|20|19262|20|0|0
1529998908000|2018-06-26 15:41:48|hello world|20|19502|20|0|0
1529998909000|2018-06-26 15:41:49|hello world|20|18386|20|0|0
其中 p 代表通过的请求, block 代表被阻止的请求, s 代表成功执行完成的请求个数, e 代表用户自定义的异常, rt 代表平均响应时长。
可以看到,这个程序每秒稳定输出 "hello world" 20 次,和规则中预先设定的阈值是一样的。
更详细的说明可以参考: 如何使用
更多的例子可以参考: Demo
STEP 5. 启动 Sentinel 控制台
您可以参考 Sentinel 控制台文档 启动控制台,可以实时监控各个资源的运行情况,并且可以实时地修改限流规则。
详细文档
请移步 Wiki,查阅详细的文档、示例以及使用说明。若您希望从其它熔断降级组件(如 Hystrix)迁移或进行功能对比,可以参考 迁移指南。
Please refer to README for README in English。
与 Sentinel 相关的生态(包括社区用户实现的扩展、整合、示例以及文章)可以参见 Awesome Sentinel,欢迎补充!
如果您正在使用 Sentinel,欢迎在 Wanted: Who is using Sentinel 留言告诉我们您的使用场景,以便我们更好地去改进。
https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D
Sentinel 与 Hystrix 的对比
Sentinel 是阿里中间件团队研发的面向分布式服务架构的轻量级高可用流量控制组件,最近正式开源。Sentinel 主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。大家可能会问:Sentinel 和之前常用的熔断降级库 Netflix Hystrix 有什么异同呢?本文将从多个角度对 Sentinel 和 Hystrix 进行对比,帮助大家进行技术选型。
Overview
先来看一下 Hystrix 的官方介绍:
Hystrix is a library that helps you control the interactions between these distributed services by adding latency tolerance and fault tolerance logic. Hystrix does this by isolating points of access between the services, stopping cascading failures across them, and providing fallback options, all of which improve your system’s overall resiliency.
可以看到 Hystrix 的关注点在于以 隔离 和 熔断 为主的容错机制,超时或被熔断的调用将会快速失败,并可以提供 fallback 机制。
而 Sentinel 的侧重点在于:
- 多样化的流量控制
- 熔断降级
- 系统负载保护
- 实时监控和控制台
可以看到两者解决的问题还是有比较大的不同的,下面我们来分别对比一下。
共同特性
资源模型和执行模型上的对比
Hystrix 的资源模型设计上采用了命令模式,将对外部资源的调用和 fallback 逻辑封装成一个命令对象(HystrixCommand / HystrixObservableCommand),其底层的执行是基于 RxJava 实现的。每个 Command 创建时都要指定 commandKey 和 groupKey(用于区分资源)以及对应的隔离策略(线程池隔离 or 信号量隔离)。线程池隔离模式下需要配置线程池对应的参数(线程池名称、容量、排队超时等),然后 Command 就会在指定的线程池按照指定的容错策略执行;信号量隔离模式下需要配置最大并发数,执行 Command 时 Hystrix 就会限制其并发调用。
Sentinel 的设计则更为简单。相比 Hystrix Command 强依赖隔离规则,Sentinel 的资源定义与规则配置的耦合度更低。Hystrix 的 Command 强依赖于隔离规则配置的原因是隔离规则会直接影响 Command 的执行。在执行的时候 Hystrix 会解析 Command 的隔离规则来创建 RxJava Scheduler 并在其上调度执行,若是线程池模式则 Scheduler 底层的线程池为配置的线程池,若是信号量模式则简单包装成当前线程执行的 Scheduler。而 Sentinel 并不指定执行模型,也不关注应用是如何执行的。Sentinel 的原则非常简单:根据对应资源配置的规则来为资源执行相应的限流/降级/负载保护策略。在 Sentinel 中资源定义和规则配置是分离的。用户先通过 Sentinel API 给对应的业务逻辑定义资源(埋点),然后可以在需要的时候配置规则。埋点方式有两种:
- try-catch 方式(通过
SphU.entry(...)),用户在 catch 块中执行异常处理 / fallback - if-else 方式(通过
SphO.entry(...)),当返回 false 时执行异常处理 / fallback
未来 Sentinel 还会引入基于注解的资源定义方式,同时可以通过注解参数指定异常处理函数和 fallback 函数。
Sentinel 提供多样化的规则配置方式。除了直接通过 loadRules API 将规则注册到内存态之外,用户还可以注册各种外部数据源来提供动态的规则。用户可以根据系统当前的实时情况去动态地变更规则配置,数据源会将变更推送至 Sentinel 并即时生效。
隔离设计上的对比
隔离是 Hystrix 的核心功能之一。Hystrix 提供两种隔离策略:线程池隔离(Bulkhead Pattern)和信号量隔离,其中最推荐也是最常用的是线程池隔离。Hystrix 的线程池隔离针对不同的资源分别创建不同的线程池,不同服务调用都发生在不同的线程池中,在线程池排队、超时等阻塞情况时可以快速失败,并可以提供 fallback 机制。线程池隔离的好处是隔离度比较高,可以针对某个资源的线程池去进行处理而不影响其它资源,但是代价就是线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。
但是,实际情况下,线程池隔离并没有带来非常多的好处。首先就是过多的线程池会非常影响性能。考虑这样一个场景,在 Tomcat 之类的 Servlet 容器使用 Hystrix,本身 Tomcat 自身的线程数目就非常多了(可能到几十或一百多),如果加上 Hystrix 为各个资源创建的线程池,总共线程数目会非常多(几百个线程),这样上下文切换会有非常大的损耗。另外,线程池模式比较彻底的隔离性使得 Hystrix 可以针对不同资源线程池的排队、超时情况分别进行处理,但这其实是超时熔断和流量控制要解决的问题,如果组件具备了超时熔断和流量控制的能力,线程池隔离就显得没有那么必要了。
Sentinel 可以通过并发线程数模式的流量控制来提供信号量隔离的功能。这样的隔离非常轻量级,仅限制对某个资源调用的并发数,而不是显式地去创建线程池,所以 overhead 比较小,但是效果不错。并且结合基于响应时间的熔断降级模式,可以在不稳定资源的平均响应时间比较高的时候自动降级,防止过多的慢调用占满并发数,影响整个系统。而 Hystrix 的信号量隔离比较简单,无法对慢调用自动进行降级,只能等待客户端自己超时,因此仍然可能会出现级联阻塞的情况。
熔断降级对比
Sentinel 和 Hystrix 的熔断降级功能本质上都是基于熔断器模式(Circuit Breaker Pattern)。Sentinel 与 Hystrix 都支持基于失败比率(异常比率)的熔断降级,在调用达到一定量级并且失败比率达到设定的阈值时自动进行熔断,此时所有对该资源的调用都会被 block,直到过了指定的时间窗口后才启发性地恢复。上面提到过,Sentinel 还支持基于平均响应时间的熔断降级,可以在服务响应时间持续飙高的时候自动熔断,拒绝掉更多的请求,直到一段时间后才恢复。这样可以防止调用非常慢造成级联阻塞的情况。
实时指标统计实现对比
Hystrix 和 Sentinel 的实时指标数据统计实现都是基于滑动窗口的。Hystrix 1.5 之前的版本是通过环形数组实现的滑动窗口,通过锁配合 CAS 的操作对每个桶的统计信息进行更新。Hystrix 1.5 开始对实时指标统计的实现进行了重构,将指标统计数据结构抽象成了响应式流(reactive stream)的形式,方便消费者去利用指标信息。同时底层改造成了基于 RxJava 的事件驱动模式,在服务调用成功/失败/超时的时候发布相应的事件,通过一系列的变换和聚合最终得到实时的指标统计数据流,可以被熔断器或 Dashboard 消费。
Sentinel 目前抽象出了 Metric 指标统计接口,底层可以有不同的实现,目前默认的实现是基于 LeapArray 的滑动窗口,后续根据需要可能会引入 reactive stream 等实现。
Sentinel 的特色
除了之前提到的两者的共同特性之外,Sentinel 还提供以下的特色功能:
轻量级、高性能
Sentinel 作为一个功能完备的高可用流量管控组件,其核心 sentinel-core 没有任何多余依赖,打包后只有不到 200 KB,非常轻量级。开发者可以放心地引入 sentinel-core 而不需担心依赖问题。同时,Sentinel 提供了多种扩展点,用户可以很方便地根据需求去进行扩展,并且无缝地切合到 Sentinel 中。
引入 Sentinel 带来的性能损耗非常小。只有在业务单机量级超过 25W QPS 的时候才会有一些显著的影响(5% - 10% 左右),单机 QPS 不太大的时候损耗几乎可以忽略不计。
流量控制
Sentinel 可以针对不同的调用关系,以不同的运行指标(如 QPS、并发调用数、系统负载等)为基准,对资源调用进行流量控制,将随机的请求调整成合适的形状。
Sentinel 支持多样化的流量整形策略,在 QPS 过高的时候可以自动将流量调整成合适的形状。常用的有:
- 直接拒绝模式:即超出的请求直接拒绝。
- 慢启动预热模式:当流量激增的时候,控制流量通过的速率,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。

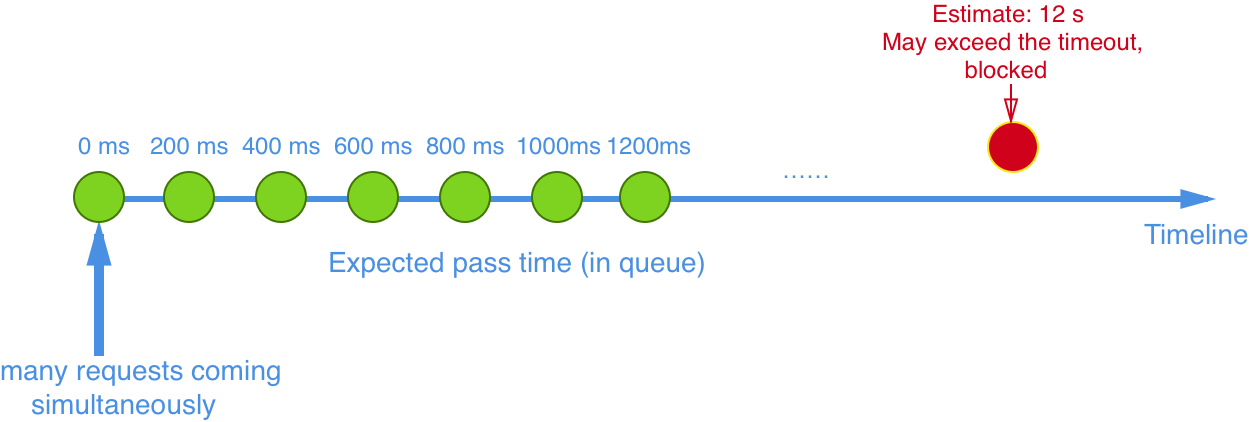
- 匀速器模式:利用 Leaky Bucket 算法实现的匀速模式,严格控制了请求通过的时间间隔,同时堆积的请求将会排队,超过超时时长的请求直接被拒绝。
Sentinel 还支持基于调用关系的限流,包括基于调用方限流、基于调用链入口限流、关联流量限流等,依托于 Sentinel 强大的调用链路统计信息,可以提供精准的不同维度的限流。
目前 Sentinel 对异步调用链路的支持还不是很好,后续版本会着重改善支持异步调用。
系统负载保护
Sentinel 对系统的维度提供保护,负载保护算法借鉴了 TCP BBR 的思想。当系统负载较高的时候,如果仍持续让请求进入,可能会导致系统崩溃,无法响应。在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。针对这个情况,Sentinel 提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。

实时监控与控制面板
Sentinel 提供 HTTP API 用于获取实时的监控信息,如调用链路统计信息、簇点信息、规则信息等。如果用户正在使用 Spring Boot/Spring Cloud 并使用了 Sentinel Spring Cloud Starter,还可以方便地通过其暴露的 Actuator Endpoint 来获取运行时的一些信息,如动态规则等。未来 Sentinel 还会支持标准化的指标监控 API,可以方便地整合各种监控系统和可视化系统,如 Prometheus、Grafana 等。
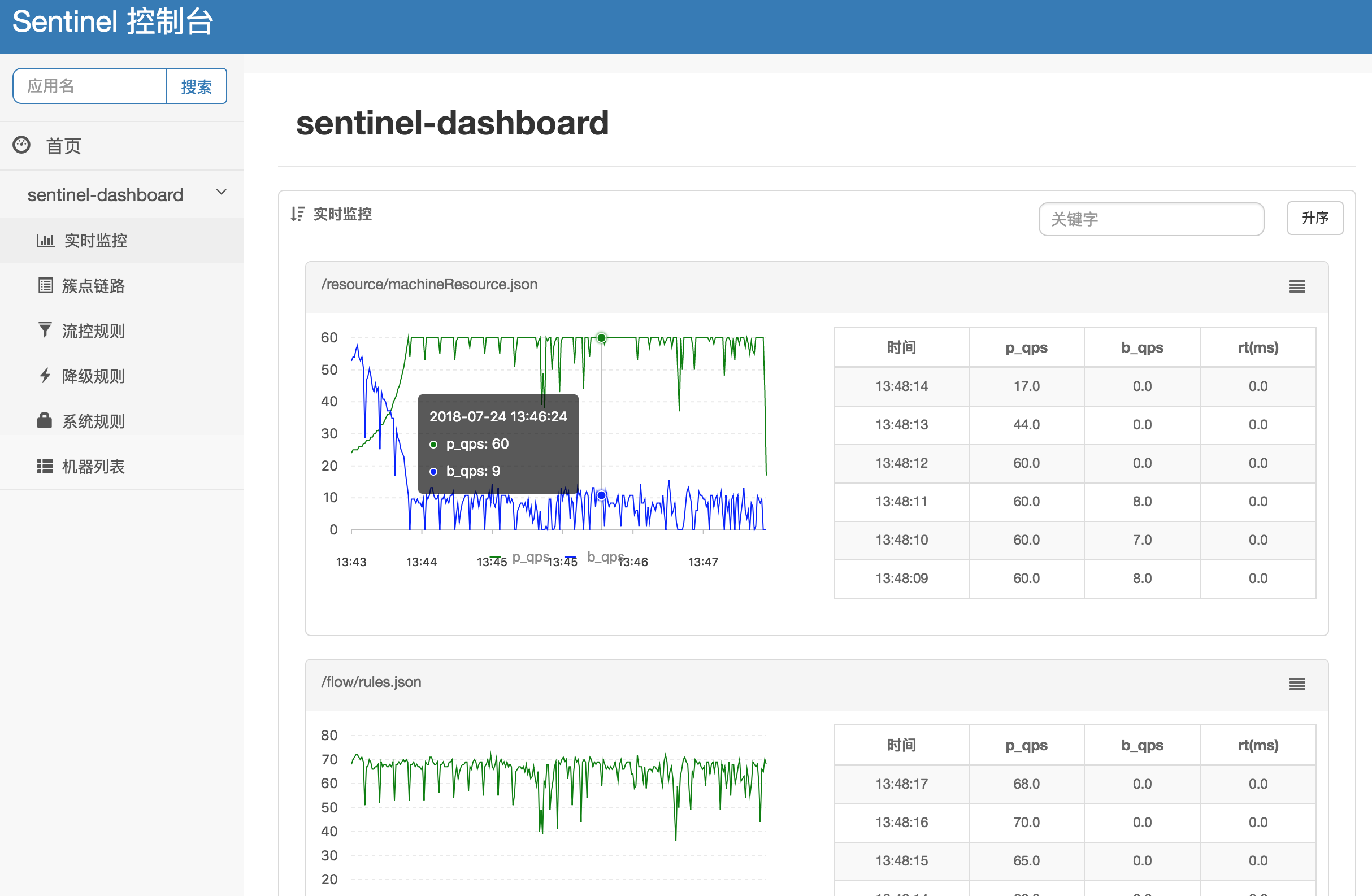
Sentinel 控制台(Dashboard)提供了机器发现、配置规则、查看实时监控、查看调用链路信息等功能,使得用户可以非常方便地去查看监控和进行配置。
生态
Sentinel 目前已经针对 Servlet、Dubbo、Spring Boot/Spring Cloud、gRPC 等进行了适配,用户只需引入相应依赖并进行简单配置即可非常方便地享受 Sentinel 的高可用流量防护能力。未来 Sentinel 还会对更多常用框架进行适配,并且会为 Service Mesh 提供集群流量防护的能力。
总结
最后用表格来进行对比总结:
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 基于并发数 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于响应时间或失败比率 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 即将发布 | 支持 |
| 调用链路信息 | 支持同步调用 | 不支持 |
| 限流 | 基于 QPS / 并发数,支持基于调用关系的限流 | 不支持 |
| 流量整形 | 支持慢启动、匀速器模式 | 不支持 |
| 系统负载保护 | 支持 | 不支持 |
| 实时监控 API | 各式各样 | 较为简单 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
若有 Sentinel 设计上的疑问或讨论,欢迎来提 issue。若对 Sentinel 的开发感兴趣,不要犹豫,欢迎加入我们,我们随时欢迎贡献!
https://yq.aliyun.com/articles/623424
Hystrix工作原理(官方文档翻译)
工作流程图
下面的流程图展示了当使用Hystrix的依赖请求,Hystrix是如何工作的。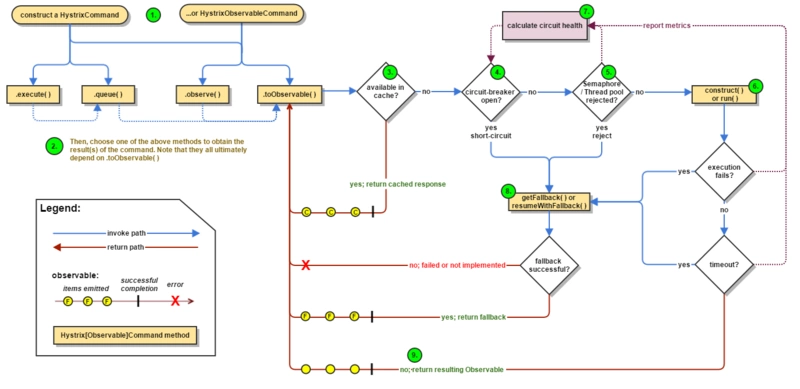
下面将更详细的解析每一个步骤都发生哪些动作:
-
构建一个
HystrixCommand或者HystrixObservableCommand对象。第一步就是构建一个
HystrixCommand或者HystrixObservableCommand对象,该对象将代表你的一个依赖请求,向构造函数中传入请求依赖所需要的参数。如果构建
HystrixCommand中的依赖返回单个响应,例如:HystrixCommand command = new HystrixCommand(arg1, arg2);如果依赖需要返回一个
Observable来发射响应,就需要通过构建HystrixObservableCommand对象来完 成,例如:HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2); -
执行命令
有4种方式可以执行一个Hystrix命令。
execute()—该方法是阻塞的,从依赖请求中接收到单个响应(或者出错时抛出异常)。queue()—从依赖请求中返回一个包含单个响应的Future对象。observe()—订阅一个从依赖请求中返回的代表响应的Observable对象。toObservable()—返回一个Observable对象,只有当你订阅它时,它才会执行Hystrix命令并发射响应。
K value = command.execute(); Future<K> fValue = command.queue(); Observable<K> ohValue = command.observe(); //hot observable Observable<K> ocValue = command.toObservable(); //cold observable
同步调用方法execute()实际上就是调用queue().get()方法,queue()方法的调用的是toObservable().toBlocking().toFuture().也就是说,最终每一个HystrixCommand都是通过Observable来实现的,即使这些命令仅仅是返回一个简单的单个值。
- 响应是否被缓存
如果这个命令的请求缓存已经开启,并且本次请求的响应已经存在于缓存中,那么就会立即返回一个包含缓存响应的
Observable(下面将Request Cache部分将对请求的cache做讲解)。 - 回路器是否打开
当命令执行执行时,Hystrix会检查回路器是否被打开。
如果回路器被打开(或者tripped),那么Hystrix就不会再执行命名,而是直接路由到第
8步,获取fallback方法,并执行fallback逻辑。如果回路器关闭,那么将进入第
5步,检查是否有足够的容量来执行任务。(其中容量包括线程池的容量,队列的容量等等)。 - 线程池、队列、信号量是否已满
如果与该命令相关的线程池或者队列已经满了,那么Hystrix就不会再执行命令,而是立即跳到第
8步,执行fallback逻辑。 -
HystrixObservableCommand.construct() 或者 HystrixCommand.run()
在这里,Hystrix通过你写的方法逻辑来调用对依赖的请求,通过下列之一的调用:
HystrixCommand.run()—返回单个响应或者抛出异常。HystrixObservableCommand.construct()—返回一个发射响应的Observable或者发送一个onError()的通知。如果执行
run()方法或者construct()方法的执行时间大于命令所设置的超时时间值,那么该线程将会抛出一个TimeoutException异常(或者如果该命令没有运行在它自己的线程中,[or a separate timer thread will, if the command itself is not running in its own thread])。在这种情况下,Hystrix将会路由到第8步,执行fallback逻辑,并且如果run()或者construct()方法没有被取消或者中断,会丢弃这两个方法最终返回的结果。请注意,没有任何方式可以强制终止一个潜在[latent]的线程的运行,Hystrix能够做的最好的方式是让JVM抛出一个
InterruptedException异常,如果你的任务被Hystrix所包装,并不意味着会抛出一个InterruptedExceptions异常,该线程在Hystrix的线程池内会进行执行,虽然在客户端已经接收到了TimeoutException异常,这个行为能够渗透到Hystrix的线程池中,[though the load is 'correctly shed'],绝大多数的Http Client不会将这一行为视为InterruptedExceptions,所以,请确保正确配置连接或者读取/写入的超时时间。如果命令最终返回了响应并且没有抛出任何异常,Hystrix在返回响应后会执行一些log和指标的上报,如果是调用
run()方法,Hystrix会返回一个Observable,该Observable会发射单个响应并且会调用onCompleted方法来通知响应的回调,如果是调用construct()方法,Hystrix会通过construct()方法返回相同的Observable对象。
- 计算回路指标[Circuit Health]
Hystrix会报告成功、失败、拒绝和超时的指标给回路器,回路器包含了一系列的滑动窗口数据,并通过该数据进行统计。
它使用这些统计数据来决定回路器是否应该熔断,如果需要熔断,将在一定的时间内不在请求依赖[短路请求](译者:这一定的时候可以通过配置指定),当再一次检查请求的健康的话会重新关闭回路器。
-
获取FallBack
当命令执行失败时,Hystrix会尝试执行自定义的Fallback逻辑:
- 当
construct()或者run()方法执行过程中抛出异常。 - 当回路器打开,命令的执行进入了熔断状态。
- 当命令执行的线程池和队列或者信号量已经满容。
- 命令执行超时。
- 当
写一个fallback方法,提供一个不需要网络依赖的通用响应,从内存缓存或者其他的静态逻辑获取数据。如果再fallback内必须需要网络的调用,更好的做法是使用另一个HystrixCommand或者HystrixObservableCommand。
如果你的命令是继承自HystrixCommand,那么可以通过实现HystrixCommand.getFallback()方法返回一个单个的fallback值。
如果你的命令是继承自HystrixObservableCommand,那么可以通过实现HystrixObservableCommand.resumeWithFallback()方法返回一个Observable,并且该Observable能够发射出一个fallback值。
Hystrix会把fallback方法返回的响应返回给调用者。
如果你没有为你的命令实现fallback方法,那么当命令抛出异常时,Hystrix仍然会返回一个Observable,但是该Observable并不会发射任何的数据,并且会立即终止并调用onError()通知。通过这个onError通知,可以将造成该命令抛出异常的原因返回给调用者。
失败或不存在回退的结果将根据您如何调用Hystrix命令而有所不同:-
execute():抛出一个异常。queue():成功返回一个Future,但是如果调用get()方法,将会抛出一个异常。observe():返回一个Observable,当你订阅它时,它将立即终止,并调用onError()方法。toObservable():返回一个Observable,当你订阅它时,它将立即终止,并调用onError()方法。
- 返回成功的响应
如果Hystrix命令执行成功,它将以Observable形式返回响应给调用者。根据你在第
2步的调用方式不同,在返回Observablez之前可能会做一些转换。

execute():通过调用queue()来得到一个Future对象,然后调用get()方法来获取Future中包含的值。queue():将Observable转换成BlockingObservable,在将BlockingObservable转换成一个Future。observe():订阅返回的Observable,并且立即开始执行命令的逻辑,toObservable():返回一个没有改变的Observable,你必须订阅它,它才能够开始执行命令的逻辑。
回路器
下面的图展示了HystrixCommand和HystrixObservableCommand如何与HystrixCircuitBroker进行交互。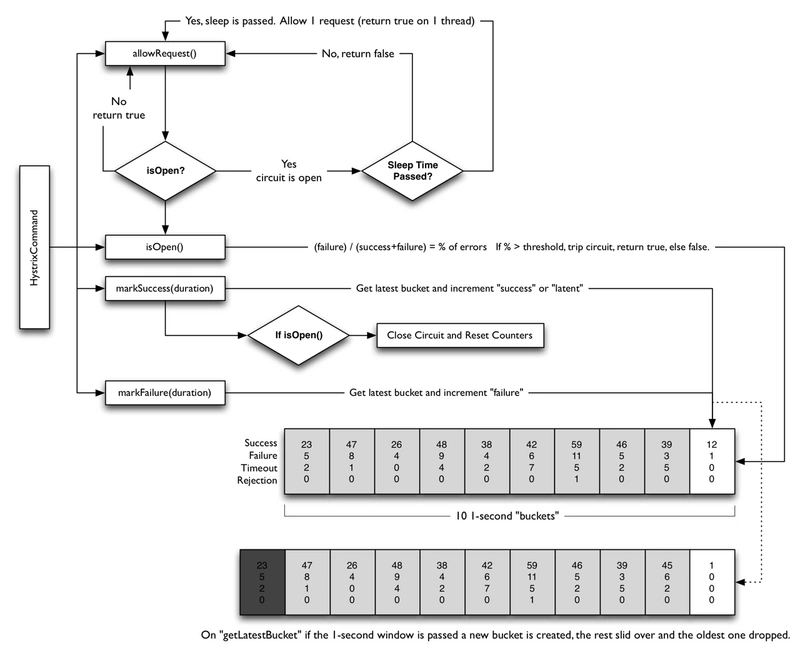
回路器打开和关闭有如下几种情况:
- 假设回路中的请求满足了一定的阈值(
HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()) - 假设错误发生的百分比超过了设定的错误发生的阈值
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage() - 回路器状态由
CLOSE变换成OPEN - 如果回路器打开,所有的请求都会被回路器所熔断。
- 一定时间之后
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds(),下一个的请求会被通过(处于半打开状态),如果该请求执行失败,回路器会在睡眠窗口期间返回OPEN,如果请求成功,回路器会被置为关闭状态,重新开启1步骤的逻辑。
隔离
Hystrix采用舱壁模式来隔离相互之间的依赖关系,并限制对其中任何一个的并发访问。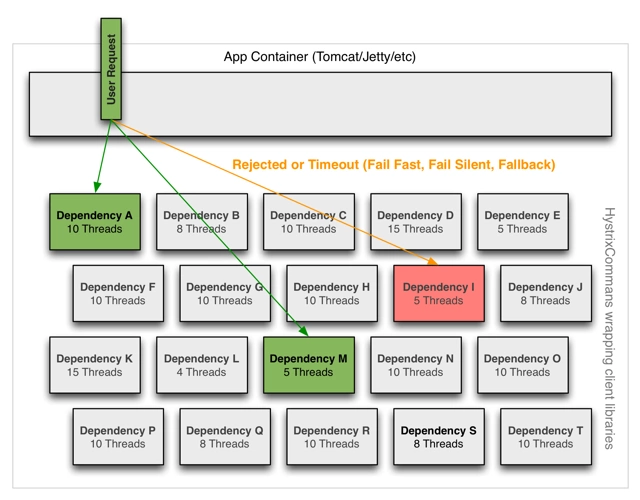
- 线程和线程池
客户端(第三方包、网络调用等)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。
[Hystrix uses separate, per-dependency thread pools as a way of constraining any given dependency so latency on the underlying executions will saturate the available threads only in that pool]

您可以在不使用线程池的情况下防止出现故障,但是这要求客户端必须能够做到快速失败(网络连接/读取超时和重试配置),并始终保持良好的执行状态。
Netflix,设计Hystrix,并且选择使用线程和线程池来实现隔离机制,有以下几个原因:
- 很多应用会调用多个不同的后端服务作为依赖。
- 每个服务会提供自己的客户端库包。
- 每个客户端的库包都会不断的处于变更状态。
- [Client library logic can change to add new network calls]
- 每个客户端库包都可能包含重试、数据解析、缓存等等其他逻辑。
- 对用户来说,客户端库往往是“黑盒”的,对于实现细节、网络访问模式。默认配置等都是不透明的。
- [In several real-world production outages the determination was “oh, something changed and properties should be adjusted” or “the client library changed its behavior.]
- 即使客户端本身没有改变,服务本身也可能发生变化,这些因素都会影响到服务的性能,从而导致客户端配置失效。
- 传递依赖可以引入其他客户端库,这些客户端库不是预期的,也许没有正确配置。
- 大部分的网络访问是同步执行的。
- 客户端代码中也可能出现失败和延迟,而不仅仅是在网络调用中。
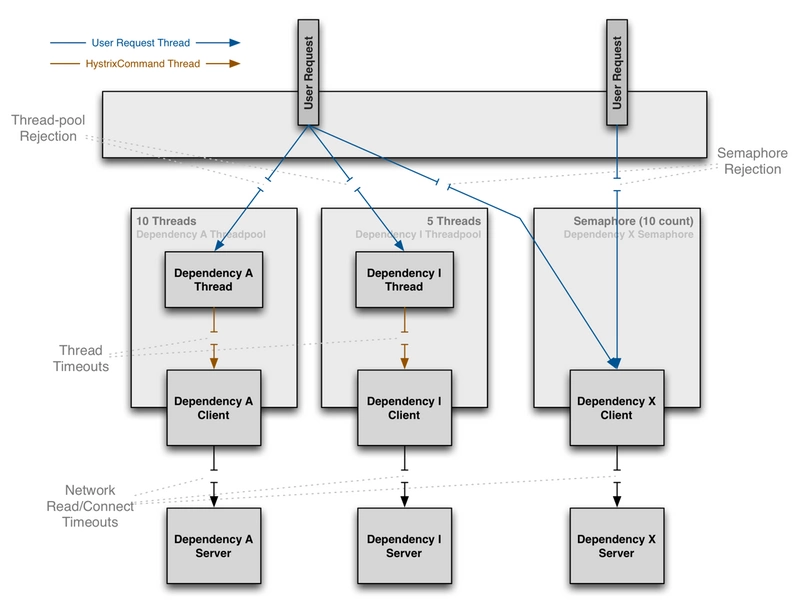
-
使用线程池的好处
通过线程在自己的线程池中隔离的好处是:
- 该应用程序完全可以不受失控的客户端库的威胁。即使某一个依赖的线程池已满也不会影响其他依赖的调用。
- 应用程序可以低风险的接受新的客户端库的数据,如果发生问题,它会与出问题的客户端库所隔离,不会影响其他依赖的任何内容。
- 当失败的客户端服务恢复时,线程池将会被清除,应用程序也会恢复,而不至于使得我们整个Tomcat容器出现故障。
- 如果一个客户端库的配置错误,线程池可以很快的感知这一错误(通过增加错误比例,延迟,超时,拒绝等),并可以在不影响应用程序的功能情况下来处理这些问题(可以通过动态配置来进行实时的改变)。
- 如果一个客户端服务的性能变差,可以通过改变线程池的指标(错误、延迟、超时、拒绝)来进行属性的调整,并且这些调整可以不影响其他的客户端请求。
- 除了隔离的优势之外,拥有专用的线程池可以提供内置的请求任务的并发性,可以在同步客户端上构建异步门面。
简而言之,由线程池提供的隔离功能可以使客户端库和子系统性能特性的不断变化和动态组合得到优雅的处理,而不会造成中断。
注意:虽然单独的线程提供了隔离,但您的底层客户端代码也应该有超时和/或响应线程中断,而不能让Hystrix的线程池处于无休止的等待状态。
- 线程池的缺点
线程池最主要的缺点就是增加了CPU的计算开销,每个命令都会在单独的线程池上执行,这样的执行方式会涉及到命令的排队、调度和上下文切换。
Netflix在设计这个系统时,决定接受这个开销的代价,来换取它所提供的好处,并且认为这个开销是足够小的,不会有重大的成本或者是性能影响。
- 线程成本
Hystrix在子线程执行
construct()方法和run()方法时会计算延迟,以及计算父线程从端到端的执行总时间。所以,你可以看到Hystrix开销成本包括(线程、度量,日志,断路器等)。Netflix API每天使用线程隔离的方式处理10亿多的Hystrix Command任务,每个API实例都有40多个线程池,每个线程池都有5-20个线程(大多数设置为10)
下图显示了一个HystrixCommand在单个API实例上每秒执行60个请求(每个服务器每秒执行大约350个线程执行总数):
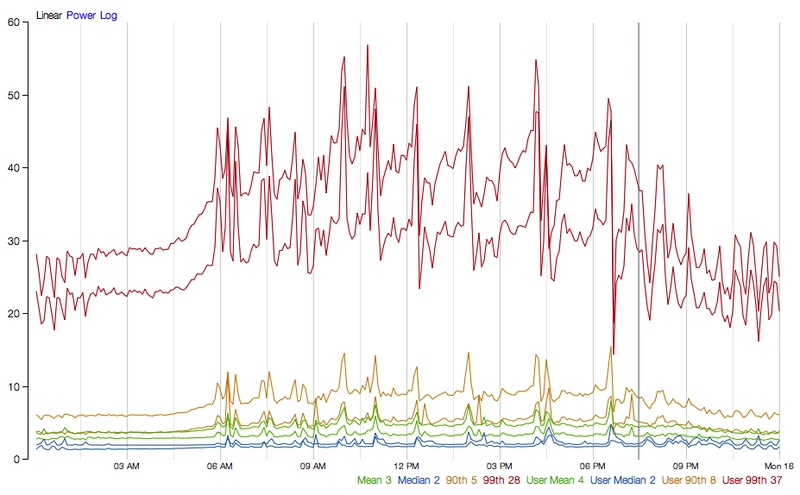
在中间位置(或者下线位置)不需要单独的线程池。
在第90线上,单独线程的成本为3ms。
在第99线上,单独的线程花费9ms。但是请注意,线程成本的开销增加远小于单独线程(网络请求)从2跳到28而执行时间从0跳到9的增加。
对于大多数Netflix用例来说,这样的请求在90%以上的开销被认为是可以接受的,这是为了实现韧性的好处。
对于非常低延迟请求(例如那些主要触发内存缓存的请求),开销可能太高,在这种情况下,可以使用另一种方法,如信号量,虽然它们不允许超时,提供绝大部分的有点,而不会产生开销。然而,一般来说,开销是比较小的,以至于Netflix通常更偏向于通过单独的线程来作为隔离实现。
请求合并
您可以使用请求合并器(HystrixCollapser是抽象父代)来提前发送HystrixCommand,通过该合并器您可以将多个请求合并为一个后端依赖项调用。
下面的图展示了两种情况下的线程数和网络连接数,第一张图是不使用请求合并,第二张图是使用请求合并(假定所有连接在短时间窗口内是“并发的”,在这种情况下是10ms)。
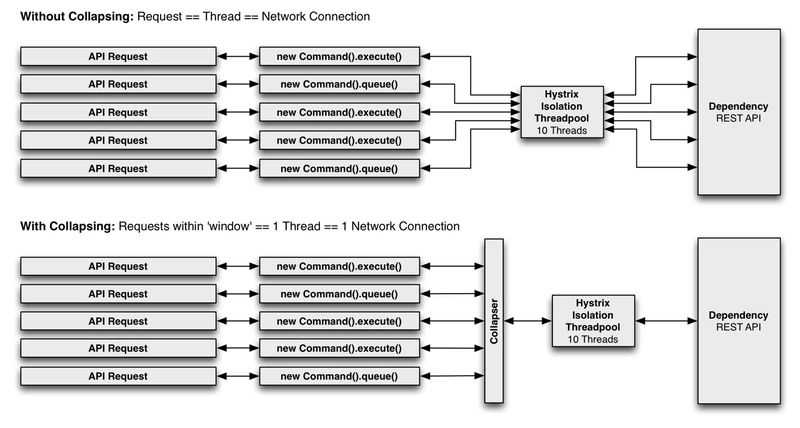
-
为什么使用请求合并
事情请求合并来减少执行并发HystrixCommand请求所需要的线程数和网络连接数。请求合并以自动方式执行的,不需要代码层面上进行批处理请求的编码。
- 全局上下文(所有的tomcat线程)
理想的合并方式是在全局应用程序级别来完成的,以便来自任何用户的任何Tomcat线程的请求都可以一起合并。
例如,如果将HystrixCommand配置为支持任何用户请求获取影片评级的依赖项的批处理,那么当同一个JVM中的任何用户线程发出这样的请求时,Hystrix会将该请求与其他请求一起合并添加到同一个JVM中的网络调用。
请注意,合并器会将一个HystrixRequestContext对象传递给合并的网络调用,为了使其成为一个有效选项,下游系统必须处理这种情况。
- 用户请求上下文(单个tomcat线程)
如果将HystrixCommand配置为仅处理单个用户的批处理请求,则Hystrix仅仅会合并单个Tomcat线程的请求。
例如,如果一个用户想要加载300个影片的标签,Hystrix能够把这300次网络调用合并成一次调用。
- 对象建模和代码的复杂性
有时候,当你创建一个对象模型对消费的对象而言是具有逻辑意义的,这与对象的生产者的有效资源利用率不匹配。
例如,给你300个视频对象,遍历他们,并且调用他们的
getSomeAttribute()方法,但是如果简单的调用,可能会导致300次网络调用(可能很快会占满资源)。有一些手动的方法可以解决这个问题,比如在用户调用
getSomeAttribute()方法之前,要求用户声明他们想要获取哪些视频对象的属性,以便他们都可以被预取。或者,您可以分割对象模型,以便用户必须从一个位置获取视频列表,然后从其他位置请求该视频列表的属性。
这些方法可以会使你的API和对象模型显得笨拙,并且这种方式也不符合心理模式与使用模式(译者:不太懂什么意思)。由于多个开发人员在代码库上工作,可能会导致低级的错误和低效率开发的问题。因为对一个用例的优化可以通过执行另一个用例和通过代码的新路径来打破。
通过将合并逻辑移到Hystrix层,不管你如何创建对象模型,调用顺序是怎样的,或者不同的开发人员是否知道是否完成了优化或者是否完成。
getSomeAttribute()方法可以放在最适合的地方,并以任何适合使用模式的方式被调用,并且合并器会自动将批量调用放置到时间窗口。
- 全局上下文(所有的tomcat线程)
####请求Cache
*
HystrixCommand和HystrixObservableCommand实现可以定义一个缓存键,然后用这个缓存键以并发感知的方式在请求上下文中取消调用(不需要调用依赖即可以得到结果,因为同样的请求结果已经按照缓存键缓存起来了)。
以下是一个涉及HTTP请求生命周期的示例流程,以及在该请求中执行工作的两个线程: 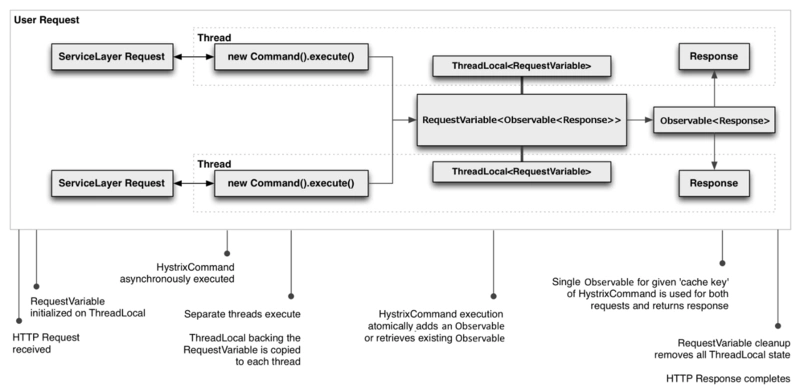
请求cache的好处有:
- 不同的代码路径可以执行Hystrix命令,而不用担心重复的工作。
这在许多开发人员实现不同功能的大型代码库中尤其有用。
例如,多个请求路径都需要获取用户的Account对象,可以像这样请求:
Account account = new UserGetAccount(accountId).execute(); //or Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix RequestCache将只执行一次底层的run()方法,执行HystrixCommand的两个线程都会收到相同的数据,尽管实例化了多个不同的实例。
- 整个请求的数据检索是一致的。
每次执行该命令时,不再会返回一个不同的值(或回退),而是将第一个响应缓存起来,后续相同的请求将会返回缓存的响应。
- 消除重复的线程执行。
由于请求缓存位于construct()或run()方法调用之前,Hystrix可以在调用线程执行之前取消调用。
如果Hystrix没有实现请求缓存功能,那么每个命令都需要在构造或者运行方法中实现,这将在一个线程排队并执行之后进行。
https://segmentfault.com/a/1190000012439580
声明:本文来源于MLDN培训视频的课堂笔记,写在这里只是为了方便查阅。
1、概念:Hystrix 熔断机制
2、具体内容
所谓的熔断机制和日常生活中见到电路保险丝是非常相似的,当出现了问题之后,保险丝会自动烧断,以保护我们的电器, 那么如果换到了程序之中呢?
当现在服务的提供方出现了问题之后整个的程序将出现错误的信息显示,而这个时候如果不想出现这样的错误信息,而希望替换为一个错误时的内容。
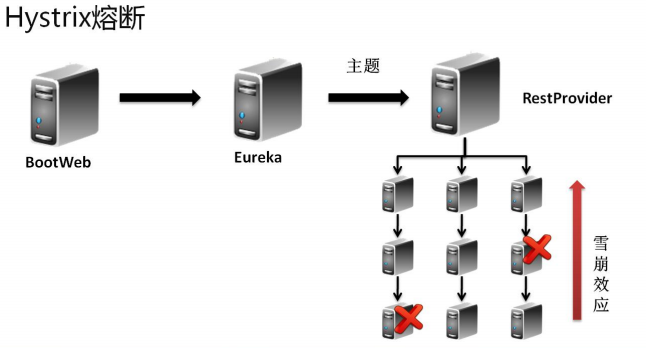
一个服务挂了后续的服务跟着不能用了,这就是雪崩效应
对于熔断技术的实现需要考虑以下几种情况:
· 出现错误之后可以 fallback 错误的处理信息;
· 如果要结合 Feign 一起使用的时候还需要在 Feign(客户端)进行熔断的配置。
2.1、Hystrix 基本配置
1、 【microcloud-provider-dept-hystrix-8001】修改 pom.xml 配置文件,追加 Hystrix 配置类:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
2、 【microcloud-provider-dept-hystrix-8001】修改 DeptRest 程序

package cn.study.microcloud.rest;
import javax.annotation.Resource;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import cn.study.microcloud.service.IDeptService;
import cn.study.vo.Dept;
@RestController
public class DeptRest {
@Resource
private IDeptService deptService;
@RequestMapping(value = "/dept/get/{id}", method = RequestMethod.GET)
@HystrixCommand(fallbackMethod="getFallback") // 如果当前调用的get()方法出现了错误,则执行fallback
public Object get(@PathVariable("id") long id) {
Dept vo = this.deptService.get(id) ; // 接收数据库的查询结果
if (vo == null) { // 数据不存在,假设让它抛出个错误
throw new RuntimeException("部门信息不存在!") ;
}
return vo ;
}
public Object getFallback(@PathVariable("id") long id) { // 此时方法的参数 与get()一致
Dept vo = new Dept() ;
vo.setDeptno(999999L);
vo.setDname("【ERROR】Microcloud-Dept-Hystrix"); // 错误的提示
vo.setLoc("DEPT-Provider");
return vo ;
}
}
一旦 get()方法上抛出了错误的信息,那么就认为该服务有问题,会默认使用“@HystrixCommand”注解之中配置好的 fallbackMethod 调用类中的指定方法,返回相应数据。
3、 【microcloud-provider-dept-hystrix-8001】在主类之中启动熔断处理
package cn.study.microcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
@EnableCircuitBreaker
@EnableDiscoveryClient
public class Dept_8001_StartSpringCloudApplication {
public static void main(String[] args) {
SpringApplication.run(Dept_8001_StartSpringCloudApplication.class, args);
}
}
现在的处理情况是:服务器出现了错误(但并不表示提供方关闭),那么此时会调用指定方法的 fallback 处理。
2.2、服务降级(服务回退)
所有的 RPC 技术里面服务降级是一个最为重要的话题,所谓的降级指的是当服务的提供方不可使用的时候,程序不会出现异常,而会出现本地的操作调用。
例如:在每年年底 12306 都是最繁忙的时候,那么在这个情况会发现有一些神奇的情况:当到了指定的时间大家开始抢票的 时候,如果你不抢,而后查询一些冷门的车次,票有可能查询不出来。因为这个时候会将所有的系统资源给抢票调度了,而其它的 服务由于其暂时不受到过多的关注,这个时候可以考虑将服务降级(服务暂停)。
服务的降级处理是在客户端实现的,与你的服务器端没有关系。
1、 【microcloud-service】扩充一个 IDeptService 的失败调用(服务降级)处理:
package cn.study.service.fallback;
import java.util.List;
import org.springframework.stereotype.Component;
import cn.study.service.IDeptClientService;
import cn.study.vo.Dept;
import feign.hystrix.FallbackFactory;
@Component
public class IDeptClientServiceFallbackFactory
implements
FallbackFactory<IDeptClientService> {
@Override
public IDeptClientService create(Throwable cause) {
return new IDeptClientService() {
@Override
public Dept get(long id) {
Dept vo = new Dept();
vo.setDeptno(888888L);
vo.setDname("【ERROR】Feign-Hystrix"); // 错误的提示
vo.setLoc("Consumer客户端提供");
return vo;
}
@Override
public List<Dept> list() {
return null;
}
@Override
public boolean add(Dept dept) {
return false;
}
};
}
}
2、 【microcloud-service】修改 IDeptClientService 接口,追加本地的 Fallback 配置。
package cn.study.service;
import java.util.List;
import org.springframework.cloud.netflix.feign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import cn.study.commons.config.FeignClientConfig;
import cn.study.service.fallback.IDeptClientServiceFallbackFactory;
import cn.study.vo.Dept;
@FeignClient(value = "MICROCLOUD-PROVIDER-DEPT", configuration = FeignClientConfig.class, fallbackFactory = IDeptClientServiceFallbackFactory.class)
public interface IDeptClientService {
@RequestMapping(method = RequestMethod.GET, value = "/dept/get/{id}")
public Dept get(@PathVariable("id") long id);
@RequestMapping(method = RequestMethod.GET, value = "/dept/list")
public List<Dept> list();
@RequestMapping(method = RequestMethod.POST, value = "/dept/add")
public boolean add(Dept dept);
}
此时当服务不可用的时候就会执行“IDeptClientServiceFallbackFactory”类中返回的 IDeptClientService 接口的匿名对象信息。
3、 【microcloud-consumer-hystrix】修改 application.yml 配置文件,追加 feign 配置启用。
feign:
hystrix:
enabled: true
4、 【microcloud-consumer-hystrix】修改程序启动主类:
package cn.study.microcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.netflix.feign.EnableFeignClients;
import org.springframework.context.annotation.ComponentScan;
@SpringBootApplication
@EnableEurekaClient
@ComponentScan("cn.study.service,cn.study.microcloud")
@EnableFeignClients(basePackages={"cn.study.service"})
public class Consumer_80_StartSpringCloudApplication {
public static void main(String[] args) {
SpringApplication.run(Consumer_80_StartSpringCloudApplication.class,
args);
}
}
当追加上了“@ComponentScan("cn.mldn.service")”注解之后才可以进行包的扫描配置。
此时即使服务端无法继续提供服务了,由于存在有服务降级机制,也会保证服务不可用时可以得到一些固定的提示信息。
2.3、HystrixDashboard服务监控
在 Hystrix 里面提供有一种监控的功能,那么这个功能就是“Hystrix Dashboard”,可以利用它来进行整体微服务的监控操作。
1、 首先为了方便监控,将建立一个新的监控项目:microcloud-consumer-hystrix-dashboard;
2、 【microcloud-consumer-hystrix-dashboard】修改项目中的 pom.xml 配置文件:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
3、 【microcloud-provider-*】所有的服务提供者之中都一定要提供有监控服务依赖库:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
4、 【microcloud-consumer-hystrix-dashboard】修改 application.yml 配置文件,主要进行端口的配置:
server: port: 9001
5、 【microcloud-consumer-hystrix-dashboard】创建一个监控的主类:
package cn.study.microcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard;
@SpringBootApplication
@EnableHystrixDashboard
public class HystrixDashboardApplication_9001 {
public static void main(String[] args) {
SpringApplication.run(HystrixDashboardApplication_9001.class, args);
}
}
6、 修改 hosts 主机文件,增加主机列表:
127.0.0.1 dashboard.com
服务运行地址:http://dashboard.com:9001/hystrix;

7、 得到 microcloud-provider-dept 的监控信息:http://studyjava:hello@dept-8001.com:8001/hystrix.stream;
· 如果此时要想获取监控信息必须去运行微服务;
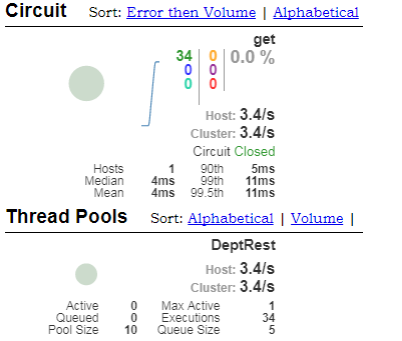
8、 将之前的监控的路径http://studyjava:hello@dept-8001.com:8001/hystrix.stream填写到之前启动好的 dashboard 程序页面之中;

监控效果如下图所示:
2.4、Turbine 聚合监控
HystrixDashboard 主要的功能是可以针对于某一项微服务进行监控,但是如果说现在有许多的微服务需要进行整体的监控,那 么这种情况下就可以利用 turbine 技术来实现。
1、 下面准备出一个新的微服务:Company,这个微服务不打算使用 SpringSecurity 安全处理以及 Mybatis 数据库连接,只是做一 个简单的数据信息。通过一个已有的 microcloud-provider-hystrix-8001 复制一个新的项目:microcloud-provider-company-8101;
2、 【microcloud-provider-company-8101】修改项目中的 pom.xml 配置文件,将与安全有关的依赖包删除掉以及与数据库连接池、MyBatis 的相关的程序类或接口全部删除掉,只保留有用的包;
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>cn.study</groupId>
<artifactId>microcloud-api</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>springloaded</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
</dependencies>
3、 【microcloud-api】追加一个新的 VO 类:Company。
package cn.study.vo;
import java.io.Serializable;
@SuppressWarnings("serial")
public class Company implements Serializable {
private String title ;
private String note ;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getNote() {
return note;
}
public void setNote(String note) {
this.note = note;
}
@Override
public String toString() {
return "Company [title=" + title + ", note=" + note + "]";
}
}
4、 【microcloud-provider-company-8101】建立一个新的微服务的程序类:CompanyRest
package cn.study.microcloud.rest;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import cn.study.vo.Company;
@RestController
public class CompanyRest {
@RequestMapping(value = "/company/get/{title}", method = RequestMethod.GET)
@HystrixCommand // 如果需要进行性能监控,那么必须要有此注解
public Object get(@PathVariable("title") String title) {
Company vo = new Company() ;
vo.setTitle(title);
vo.setNote("www.study.cn");
return vo ;
}
}
5、 【microcloud-provider-company-8101】修改程序的启动主类:
package cn.study.microcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
@EnableCircuitBreaker
@EnableDiscoveryClient
public class Company_8101_StartSpringCloudApplication {
public static void main(String[] args) {
SpringApplication.run(Company_8101_StartSpringCloudApplication.class, args);
}
}
6、 【microcloud-provider-company-8101】修改 application.yml 配置文件:
server:
port: 8101
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://edmin:studyjava@eureka-7001.com:7001/eureka,http://edmin:studyjava@eureka-7002.com:7002/eureka,http://edmin:studyjava@eureka-7003.com:7003/eureka
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: dept-8001.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址
info:
app.name: study-microcloud
company.name: www.study.cn
build.artifactId: $project.artifactId$
build.version: $project.verson$
spring:
application:
name: microcloud-provider-company
7、 【microcloud-provider-company-8101】启动微服务,随后取得监控信息:
· 在 hosts 配置文件之中追加有一个映射路径:
127.0.0.1 company-8101.com
· 访问地址:http://company-8101.com:8101/company/get/hello;
· hystrix 监控地址:http://company-8101.com:8101/hystrix.stream;
8、 如 果 要 想 实 现 trubine 的 配 置 , 则需要建立一个 turbine项目模块 , 这个项目可以直接通过之前的 microcloud-consumer-hystrix-dashboard 模块进行复制为“microcloud-consumer-turbine”模块;
9、 【microcloud-consumer-turbine】修改 pom.xml 配置文件,追加 turbine 的依赖程序包:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-turbine</artifactId>
</dependency>
10、 【microcloud-consumer-turbine】修改 application.yml 配置文件:
server:
port: 9101 # turbine的监听端口为9101
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://edmin:studyjava@eureka-7001.com:7001/eureka,http://edmin:studyjava@eureka-7002.com:7002/eureka,http://edmin:studyjava@eureka-7003.com:7003/eureka
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: dept-8001.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址
turbine:
app-config: MICROCLOUD-PROVIDER-COMPANY,MICROCLOUD-PROVIDER-DEPT # 定义所有要监控的微服务信息
cluster-name-expression: new String("default") # 设置监控的表达式,通过此表达式表示要获取监控信息名称
11、 【microcloud-consumer-turbine】建立一个 turbine 的使用主类信息
package cn.study.microcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard;
import org.springframework.cloud.netflix.turbine.EnableTurbine;
@SpringBootApplication
@EnableHystrixDashboard
@EnableTurbine
public class TurbineApplication_9101 {
public static void main(String[] args) {
SpringApplication.run(TurbineApplication_9101.class, args);
}
}
12、 【microcloud-consumer-hystrix-dashboard】运行 hystrix-dashboard 监控程序;
13、 【microcloud-consumer-turbine】运行 trubine 聚合监控程序;
· 但是在正常启动 trubine 的时候出现了以下的错误提示信息,这是因为没有对有安全认证的微服务MICROCLOUD-PROVIDER-DEPT进行安全认证

· 修改 hosts 配置文件,追加一个映射路径:
127.0.0.1 turbine.com
· trubine 访问路径:http://turbine.com:9101/turbine.stream
14、 运行 HystrixDashboard 监控程序:http://dashboard.com:9001/hystrix.stream;
· 在监控的位置上填写之前设置好的 turbine 的访问地址看到的效果如下:
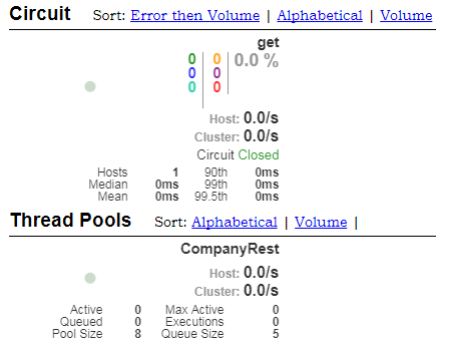
15、 【microcloud-security】如果现在需要 turbine 进行加密的微服务的访问操作,只能够采取一种折衷方案,就是要去修改整个项目中的安全策略,追加 WEB 安全策略配置:
package cn.study.microcloud.config;
import javax.annotation.Resource;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.builders.WebSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.config.http.SessionCreationPolicy;
@Configuration
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
public void configure(WebSecurity web) throws Exception {
web.ignoring().antMatchers("/hystrix.stream","/turbine.stream") ;
}
@Resource
public void configGlobal(AuthenticationManagerBuilder auth)
throws Exception {
auth.inMemoryAuthentication().withUser("studyjava").password("hello")
.roles("USER").and().withUser("admin").password("hello")
.roles("USER", "ADMIN");
}
@Override
protected void configure(HttpSecurity http) throws Exception {
// 表示所有的访问都必须进行认证处理后才可以正常进行
http.httpBasic().and().authorizeRequests().anyRequest()
.fullyAuthenticated();
// 所有的Rest服务一定要设置为无状态,以提升操作性能
http.sessionManagement()
.sessionCreationPolicy(SessionCreationPolicy.STATELESS);
}
}
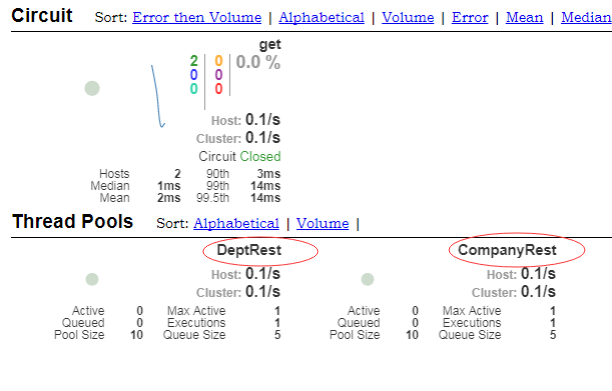
现在所有的安全策略会自动抛开以上的两个访问路径,这种是基于 Bean 配置,如果要是你现在基于的是 application.yml 文件的配置,则就必须修改 application.yml 配置文件,追加如下内容:
security: ignored: - /hystrix.stream - /turbine.stream
这个时候如果启动之后没有出现任何的错误提示,那么就表示现在已经可以绕过了 Security 的配置而直接进行服务的访问了。
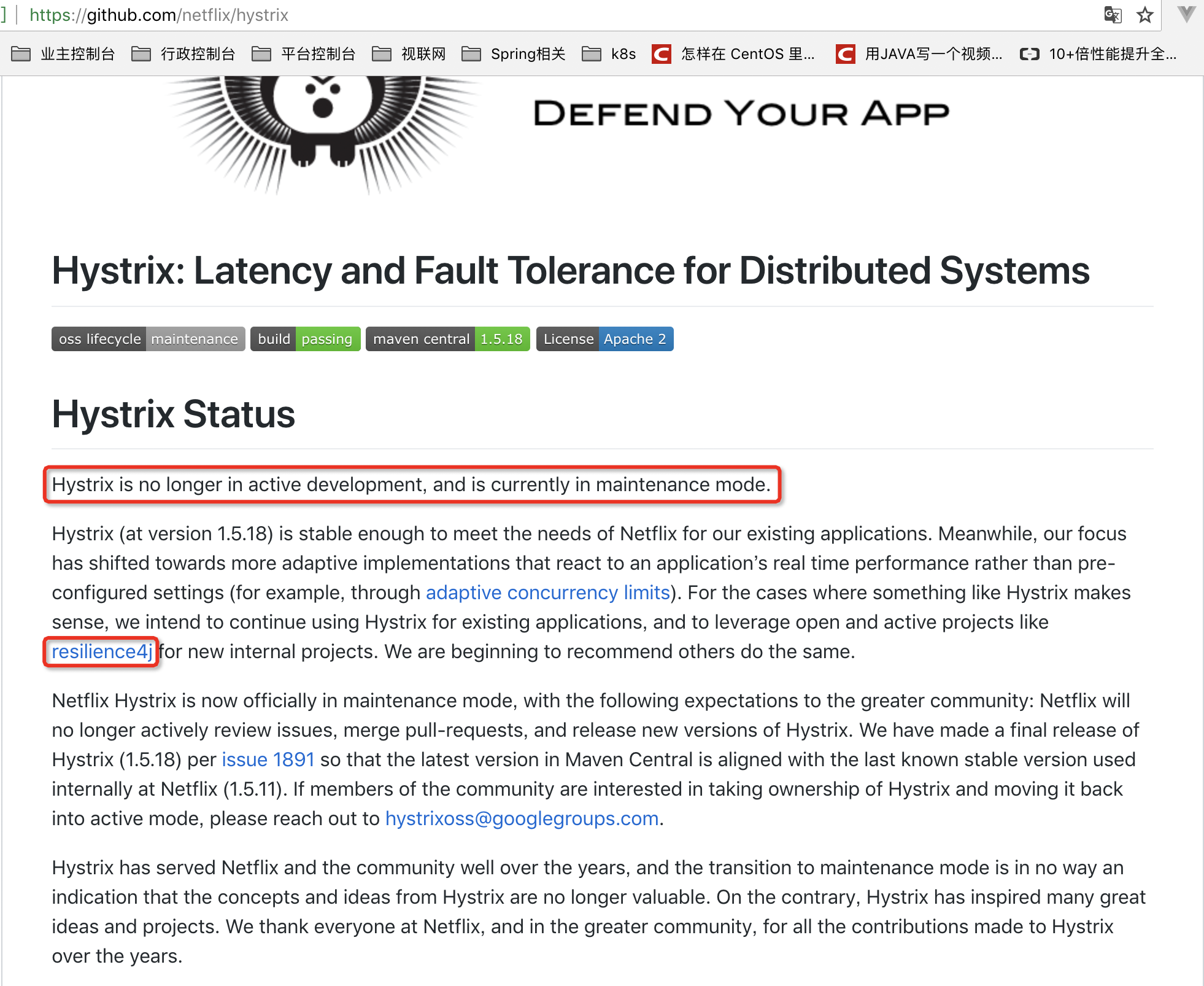
Hystrix停止开发,我们该何去何从?
是的,Hystrix停止开发了。官方的新闻如下:
考虑到之前Netflix宣布Eureka 2.0孵化失败时,被业界过度消费(关于Eureka 2.x,别再人云亦云了!),为了防止再度出现类似现象,笔者编写了这篇文章。
我相信看到这篇文章,大家无非会思考几个问题:
- 如果Hystrix还能不能继续用于生产?
- Spring Cloud生态中是否有替代实现?
下面依次展开:
就笔者经验来看,Hystrix是比较稳定的,并且Hystrix只是停止开发新的版本,并不是完全停止维护,Bug什么的依然会维护的。因此短期内,Hystrix依然是继续使用的。
但从长远来看,Hystrix总会达到它的生命周期,那么Spring Cloud生态中是否有替代产品呢?
答案显然是有。
Alibaba Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,目前在Spring Cloud的孵化器项目Spring Cloud Alibaba中,预计Spring Cloud H系列中可以孵化完成。
尽管Sentinel尚未在Spring Cloud项目中孵化完成,但Sentinel本身在阿里内部已经被大规模采用,非常稳定。因此可以作为一个较好的替代品。
Resilience4J
Resilicence4J 在今年的7月进入笔者视野,小玩了一下,觉得非常轻量、简单,并且文档非常清晰、丰富。个人比较看好,这也是Hystrix官方推荐的替代产品。
不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也不像Hystrix一样弄Dashboard/Hystrix等一堆轮子,而是支持和Micrometer(Pivotal开源的监控门面,Spring Boot 2.x中的Actuator就是基于Micrometer的)、prometheus(开源监控系统,来自谷歌的论文)、以及Dropwizard metrics(Spring Boot曾经的模仿对象,类似于Spring Boot)进行整合。
笔者特别看重Resilience4J和micrometer整合的能力,这意味着:如果你用Spring Boot 2.x并在项目中引入Resilience4J,那么监控数据和Actuator天生就是打通的!你不再需要一个专属的、类似于Hystrix Dashboard的东西去监控断路器。
预报
考虑到目前国内Resilience4J的文档还比较少,笔者准备近期分享系列博客,敬请期待!
原文:http://www.itmuch.com/spring-cloud-sum/hystrix-no-longer/
一:QPS
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
PV(page view)即页面浏览量,通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量最常用的指标之一,简称为PV。
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
一般需要达到139QPS,因为是峰值。(200万pv才有100峰值qps)
二:TPS
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
三:RT(响应时长)
响应时间是指:系统对请求作出响应的时间(一次请求耗时)。
直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。
对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的
四:Load(系统负载)
Linux的Load(系统负载),是一个让新手不太容易了解的概念。load的就是一定时间内计算机有多少个active_tasks,也就是说是计算机的任务执行队列的长度,cpu计算的队列。
top/uptime等工具默认会显示1分钟、5分钟、15分钟的平均Load。
具体来说,平均Load是指,在特定的一段时间内统计的正在CPU中运行的(R状态)、正在等待CPU运行的、处于不可中断睡眠的(D状态)的任务数量的平均值。
最后,说一下CPU使用率和Load的关系吧。如果主要是CPU密集型的程序在运行(If CPU utilization is near 100 percent (user + nice + system), the workload sampled is CPU-bound.),
那么CPU利用率高,Load一般也会比较高。而I/O密集型的程序在运行,
可能看到CPU的%user, %system都不高,%iowait可能会有点高,这时的Load通常比较高。
同理,程序读写慢速I/O设备(如磁盘、NFS)比较多时,Load可能会比较高,而CPU利用率不一定高。这种情况,还经常发生在系统内存不足并开始使用swap的时候,Load一般会比较高,而CPU使用率并不高。
五:PV
页面访问次数:Page View
六:UV
访客数(去重复):Unique Visitor
————————————————
版权声明:本文为CSDN博主「南无南有」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39416311/article/details/84892625
QPS和RT的关系:
单线程场景:
假设我们的服务端只有一个线程,那么所有的请求都是串行执行,我们可以很简单的算出系统的QPS,也就是:QPS = 1000ms/RT。假设一个RT过程中CPU计算的时间为49ms,CPU Wait Time 为200ms,那么QPS就为1000/49+200 = 4.01。
多线程场景
我们接下来把服务端的线程数提升到2,那么整个系统的QPS则为:2 *(1000/49+200)=8.02。可见QPS随着线程的增加而线性增长,那QPS上不去就加线程呗,听起来很有道理,公式也说得通,但是往往现实并非如此,后面会聊这个问题。
最佳线程数?
从上面单线程场景来看,CPU Wait time为200ms,你可以理解为CPU这段时间什么都没做,是空闲的,显然我们没把CPU利用起来,这时候我们需要启多个线程去响应请求,把这部分利用起来,那么启动多少个线程呢?我们可以估算一下 空闲时间200ms,我们要把这部分时间转换为CPU Time,那么就是200+49/49 = 5.08个,不考虑上下文切换的话,约等于5个线程。同时还要考虑CPU的核心数和利用率问题,那么我们得到了最佳线程数计算的公式:RT/CPU Time * coreSize * cupRatio
最大QPS?
得到了最大的线程数和QPS的计算方式:
QPS = Thread num * 单线程QPS = (CPU Time + CPU Wait Time)/CPU Time * coreSize * CupRatio * (1000ms/(CPU Time + CPU Wait Time)) = 1000ms/(CPU Time) * coreSize * cpuRatio
所以决定一个系统最大的QPS的因素是CPU Time、CoreSize和CPU利用率。看似增加CPU核数(或者说线程数)可以成倍的增加系统QPS,但实际上增加线程数的同时也增加了很大的系统负荷,更多的上下文切换,QPS和最大的QPS是有偏差的。
CPU Time & CPU Wait Time & CPU 利用率
CPU Time就是一次请求中,实际用到计算资源。CPU Time的消耗是全流程的,涉及到请求到应用服务器,再从应用服务器返回的全过程。实际上这取决于你的计算的复杂度。
CPU Wait Time是一次请求过程中对于IO的操作,CPU这段时间可以理解为空闲的,那么此时要尽量利用这些空闲时间,也就是增加线程数。
CPU 利用率是业务系统利用到CPU的比率,因为往往一个系统上会有一些其他的线程,这些线程会和CPU竞争计算资源,那么此时留给业务的计算资源比例就会下降,典型的像,GC线程的GC过程、锁的竞争过程都是消耗CPU的过程。甚至一些IO的瓶颈,也会导致CPU利用率下降(CPU都在Wait IO,利用率当然不高)。
一:QPS
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
PV(page view)即页面浏览量,通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量最常用的指标之一,简称为PV。
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
一般需要达到139QPS,因为是峰值。(200万pv才有100峰值qps)
二:TPS
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
三:RT(响应时长)
响应时间是指:系统对请求作出响应的时间(一次请求耗时)。
直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。
对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的
四:Load(系统负载)
Linux的Load(系统负载),是一个让新手不太容易了解的概念。load的就是一定时间内计算机有多少个active_tasks,也就是说是计算机的任务执行队列的长度,cpu计算的队列。
top/uptime等工具默认会显示1分钟、5分钟、15分钟的平均Load。
具体来说,平均Load是指,在特定的一段时间内统计的正在CPU中运行的(R状态)、正在等待CPU运行的、处于不可中断睡眠的(D状态)的任务数量的平均值。
最后,说一下CPU使用率和Load的关系吧。如果主要是CPU密集型的程序在运行(If CPU utilization is near 100 percent (user + nice + system), the workload sampled is CPU-bound.),
那么CPU利用率高,Load一般也会比较高。而I/O密集型的程序在运行,
可能看到CPU的%user, %system都不高,%iowait可能会有点高,这时的Load通常比较高。
同理,程序读写慢速I/O设备(如磁盘、NFS)比较多时,Load可能会比较高,而CPU利用率不一定高。这种情况,还经常发生在系统内存不足并开始使用swap的时候,Load一般会比较高,而CPU使用率并不高。
五:PV
页面访问次数:Page View
六:UV
访客数(去重复):Unique Visitor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号