LLaMA
近期Meta的羊驼模型(LLaMA)持续刷屏,杨立昆疯狂转发,在GPT4秀肌肉之前着实吸引了不少科研人员的眼球,开源的真香。
然而LLaMA模型并没有进行指令微调,这不斯坦福马上公布了
Alpaca模型,该模型是由Meta的LLaMA 7B利用52k的指令微调出来的,据说性能约等于GPT-3.5。
该模型目前没有开源,原因似乎是因为huggingface还没有正式支持LLaMA模型。有条件的可以自己复现一下他们的工作。
看了下他们的blog,原理大概如下:
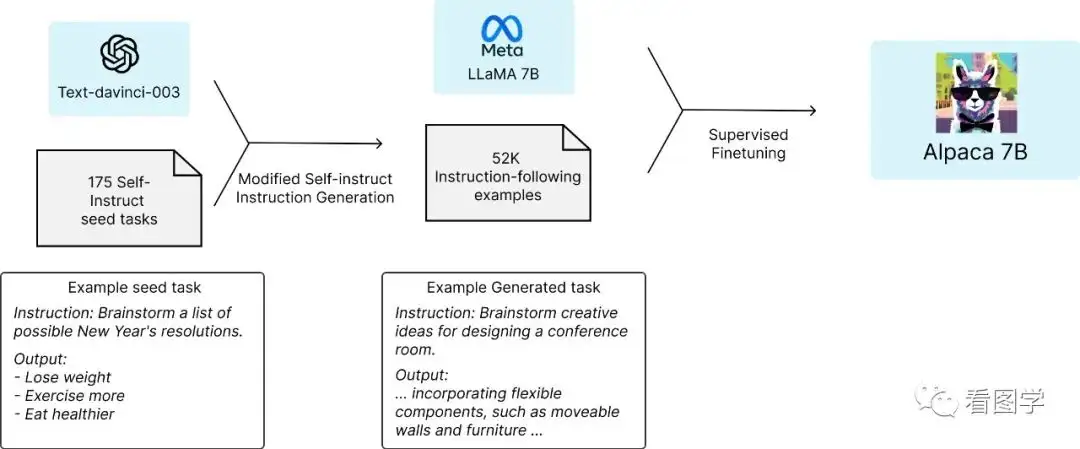
- 修改了self-instruct的框架,通过175个人工种子指令,最终生成了5.2万个,成本比原始的self-instruct要低,大概是500美元。
- 通过这5.2万个样本的指令数据集在LLaMA上进行微调。
原始的Self-instruct框架如下:
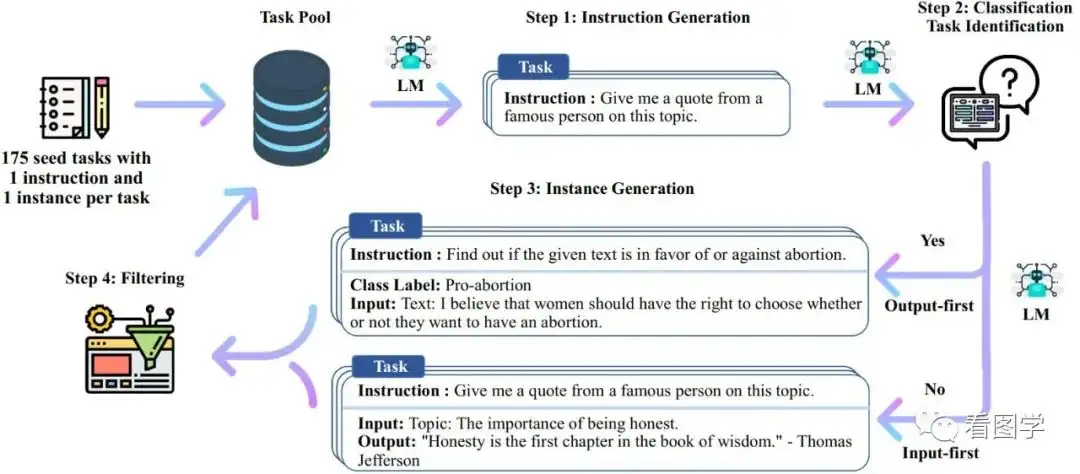
虽然说LLaMA最小的模型有7B,但是目前有很多方法可以减少其资源使用,比如llama.cpp(https://github.com/ggerganov/llama.cpp),号称可以树莓派上进行推理。还有pyllama(https://github.com/juncongmoo/pyllama),只用4G的GPU就可以推理。注意只是推理,训练肯定使用的资源更多,但是7B的模型号称有GPT-3.5的效果,不免让人想试一下。
下载LLaMA模型
想要训练,首先得把LLaMA-7B的模型给下载下来,总结了几种方案如下:
1. 伸手党
关注同名公众号,然后回复“llama”,即可得到百度网盘的下载链接。
2. 通过pyllama下载
- 安装pyllama,
pip install pyllama -U - 下载7B的模型,
python -m llama.download --model_size 7B - 当然你也可以下载更大的模型,有7B,13B,30B,65B共计4种。
3. 通过ipfs下载
这个应该是最早泄漏的LLaMA模型,地址为 https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
- 首先安装ipfs客户端,最好用带界面的。https://docs.ipfs.tech/install/ipfs-desktop/
- 然后7B模型的index为:QmbvdJ7KgvZiyaqHw5QtQxRtUd7pCAdkWWbzuvyKusLGTw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号