
一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问
问题现象
7月25号,我们一服务的内存占用较高,约13G,容器总内存16G,占用约85%,触发了内存报警(阈值85%),而我们是按容器内存60%(9.6G)的比例配置的JVM堆内存。看了下其它服务,同样的堆内存配置,它们内存占用约70%~79%,此服务比其它服务内存占用稍大。

那为什么此服务内存占用稍大呢,它存在内存泄露吗?
排查步骤
1. 检查Java堆占用与gc情况
jcmd 1 GC.heap_info

image_2023-08-26_20230826175746
jstat -gcutil 1 1000

可见堆使用情况正常。
2. 检查非堆占用情况
查看监控仪表盘,如下:

arthas的memory命令查看,如下:
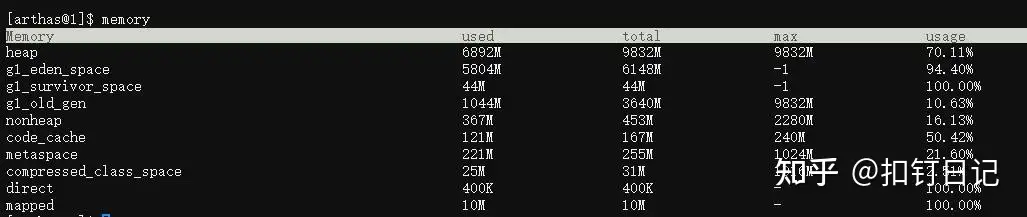
可见非堆内存占用也正常。
3. 检查native内存
Linux进程的内存布局,如下:
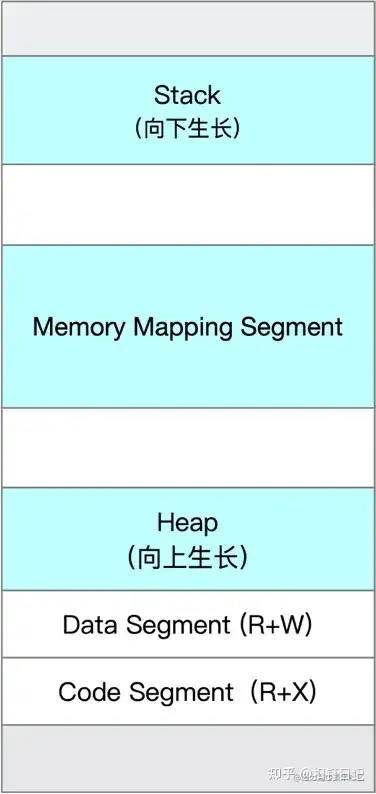
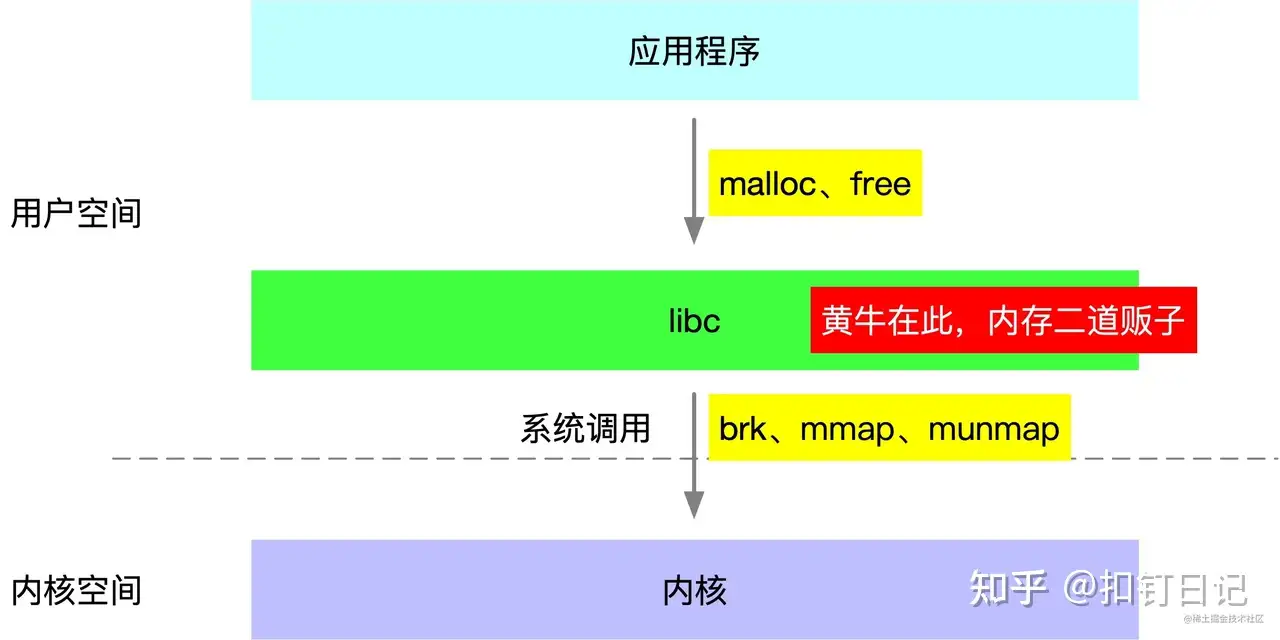
linux进程启动时,有代码段、数据段、堆(Heap)、栈(Stack)及内存映射段,在运行过程中,应用程序调用malloc、mmap等C库函数来使用内存,C库函数内部则会视情况通过brk系统调用扩展堆或使用mmap系统调用创建新的内存映射段。
而通过pmap命令,就可以查看进程的内存布局,它的输出样例如下:
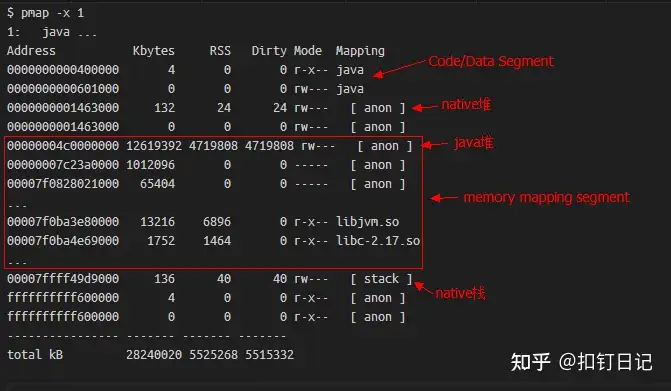
可以发现,进程申请的所有虚拟内存段,都在pmap中能够找到,相关字段解释如下:
- Address:表示此内存段的起始地址
- Kbytes:表示此内存段的大小(ps:这是虚拟内存)
- RSS:表示此内存段实际分配的物理内存,这是由于Linux是延迟分配内存的,进程调用malloc时Linux只是分配了一段虚拟内存块,直到进程实际读写此内存块中部分时,Linux会通过缺页中断真正分配物理内存。
- Dirty:此内存段中被修改过的内存大小,使用mmap系统调用申请虚拟内存时,可以关联到某个文件,也可不关联,当关联了文件的内存段被访问时,会自动读取此文件的数据到内存中,若此段某一页内存数据后被更改,即为Dirty,而对于非文件映射的匿名内存段(anon),此列与RSS相等。
- Mode:内存段是否可读(r)可写(w)可执行(x)
- Mapping:内存段映射的文件,匿名内存段显示为anon,非匿名内存段显示文件名(加-p可显示全路径)。
因此,我们可以找一些内存段,来看看这些内存段中都存储的什么数据,来确定是否有泄露。但jvm一般有非常多的内存段,重点检查哪些内存段呢?
有两种思路,如下:
- 检查那些占用内存较大的内存段,如下:
pmap -x 1 | sort -nrk3 | less

可以发现我们进程有非常多的64M的内存块,而我同时看了看其它java服务,发现64M内存块则少得多。
- 检查一段时间后新增了哪些内存段,或哪些变大了,如下:
在不同的时间点多次保存pmap命令的输出,然后通过文本对比工具查看两个时间点内存段分布的差异。
pmap -x 1 > pmap-`date +%F-%H-%M-%S`.log
image_2023-08-26_20230826180037
icdiff pmap-2023-07-27-09-46-36.log pmap-2023-07-28-09-29-55.log | less -SR
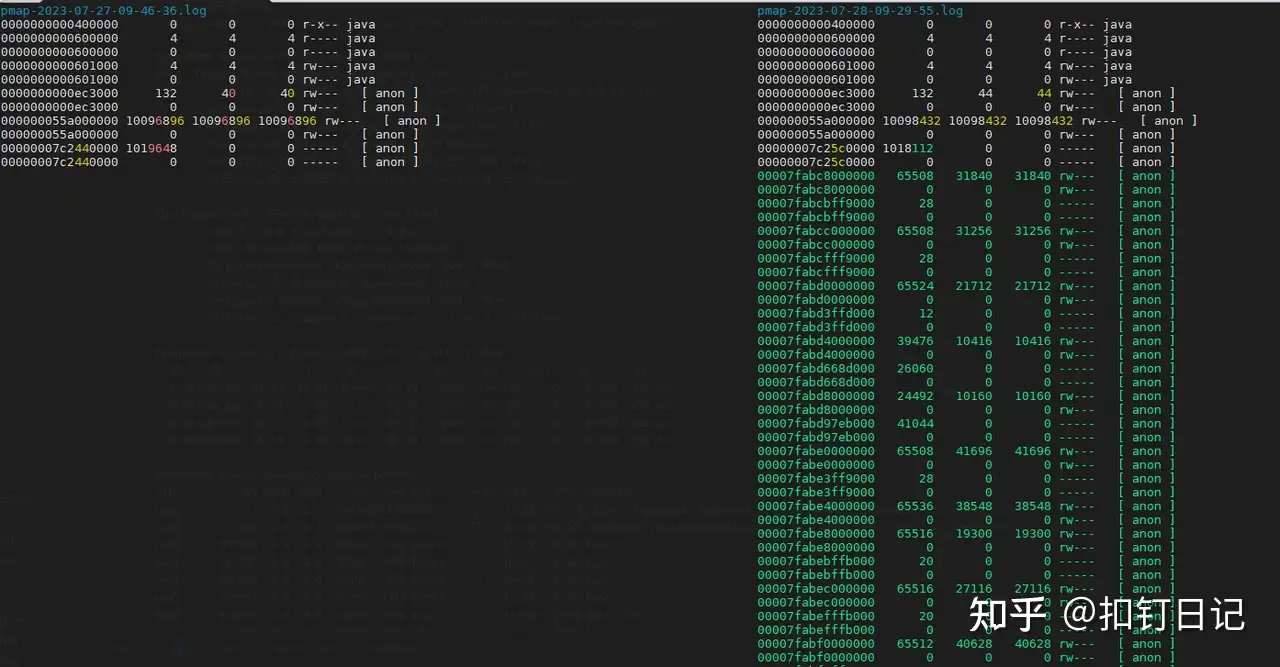
image_2023-08-26_20230826180057
可以看到,一段时间后,新分配了一些内存段,看看这些变化的内存段里存的是什么内容!
tail -c +$((0x00007face0000000+1)) /proc/1/mem|head -c $((11616*1024))|strings|less -S
说明:
- Linux将进程内存虚拟为伪文件/proc/$pid/mem,通过它即可查看进程内存中的数据。
- tail用于偏移到指定内存段的起始地址,即pmap的第一列,head用于读取指定大小,即pmap的第二列。
- strings用于找出内存中的字符串数据,less用于查看strings输出的字符串。
通过查看各个可疑内存段,发现有不少类似我们一自研消息队列的响应格式数据,通过与消息队列团队合作,找到了相关的消息topic,并最终与相关研发确认了此topic消息最近刚迁移到此服务中。
4. 检查发http请求代码
由于发送消息是走http接口,故我在工程中搜索调用http接口的相关代码,发现一处代码中创建的流对象没有关闭,而GZIPInputStream这个类刚好会直接分配到native内存。

其它方法
本次问题,通过检查内存中的数据找到了问题,还是有些碰运气的。这需要内存中刚好有一些非常有代表性的字符串,因为非字符串的二进制数据,基本无法分析。
如果查看内存数据无法找到关键线索,还可尝试以下几个方法:
5. 开启JVM的NMT原生内存追踪功能
添加JVM参数-XX:NativeMemoryTracking=detail开启,使用jcmd查看,如下:
jcmd 1 VM.native_memory
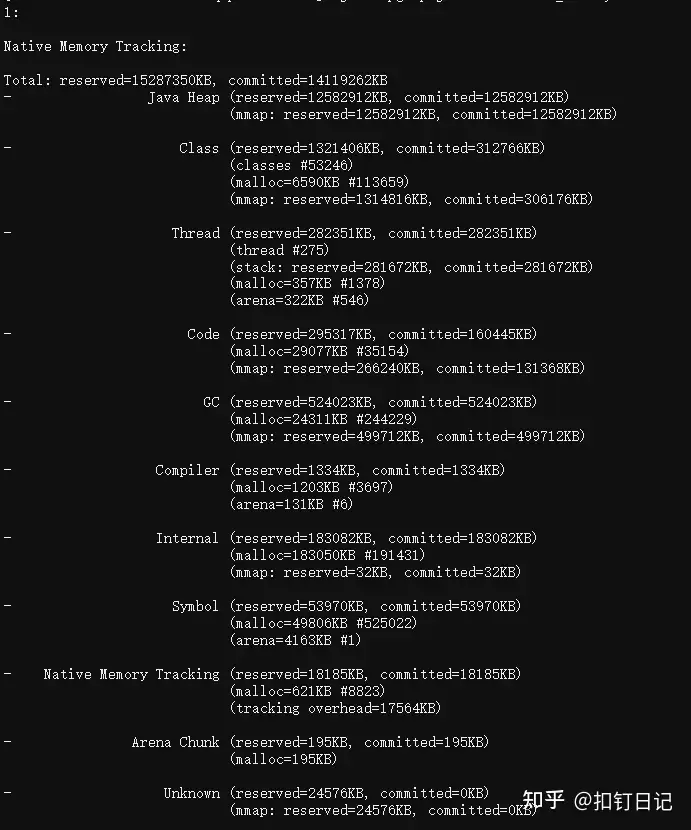
NMT只能观察到JVM管理的内存,像通过JNI机制直接调用malloc分配的内存,则感知不到。
6. 检查被glibc内存分配器缓存的内存
JVM等原生应用程序调用的malloc、free函数,实际是由基础C库libc提供的,而linux系统则提供了brk、mmap、munmap这几个系统调用来分配虚拟内存,所以libc的malloc、free函数实际是基于这些系统调用实现的。
由于系统调用有一定的开销,为减小开销,libc实现了一个类似内存池的机制,在free函数调用时将内存块缓存起来不归还给linux,直到缓存内存量到达一定条件才会实际执行归还内存的系统调用。
所以进程占用内存比理论上要大些,一定程度上是正常的。
malloc_stats函数
通过如下命令,可以确认glibc库缓存的内存量,如下:
# 查看glibc内存分配情况,会输出到进程标准错误中
gdb -q -batch -ex 'call malloc_stats()' -p 1

如上,Total (incl. mmap)表示glibc分配的总体情况(包含mmap分配的部分),其中system bytes表示glibc从操作系统中申请的虚拟内存总大小,in use bytes表示JVM正在使用的内存总大小(即调用glibc的malloc函数后且没有free的内存)。
可以发现,glibc缓存了快500m的内存。
注:当我对jvm进程中执行malloc_stats后,我发现它显示的in use bytes要少得多,经过检查JVM代码,发现JVM在为Java Heap、Metaspace分配内存时,是直接通过mmap函数分配的,而这个函数是直接封装的mmap系统调用,不走glibc内存分配器,故in use bytes会小很多。
malloc_trim函数
glibc实现了malloc_trim函数,通过brk或madvise系统调用,归还被glibc缓存的内存,如下:
# 回收glibc缓存的内存
gdb -q -batch -ex 'call malloc_trim(0)' -p 1
![]()

可以发现,执行malloc_trim后,RSS减少了约250m内存,可见内存占用高并不是因为glibc缓存了内存。
注:通过gdb调用C函数,会有一定概率造成jvm进程崩溃,需谨慎执行。
7. 使用tcmalloc或jemalloc的内存泄露检测工具
glibc的默认内存分配器为ptmalloc2,但Linux提供了LD_PRELOAD机制,使得我们可以更换为其它的内存分配器,如业内比较成熟的tcmalloc或jemalloc。
这两个内存分配器除了实现了内存分配功能外,还提供了内存泄露检测的能力,它们通过hook进程的malloc、free函数调用,然后找到那些调用了malloc后一直没有free的地方,那么这些地方就可能是内存泄露点。
HEAPPROFILE=./heap.log
HEAP_PROFILE_ALLOCATION_INTERVAL=104857600
LD_PRELOAD=./libtcmalloc_and_profiler.so
java -jar xxx ...
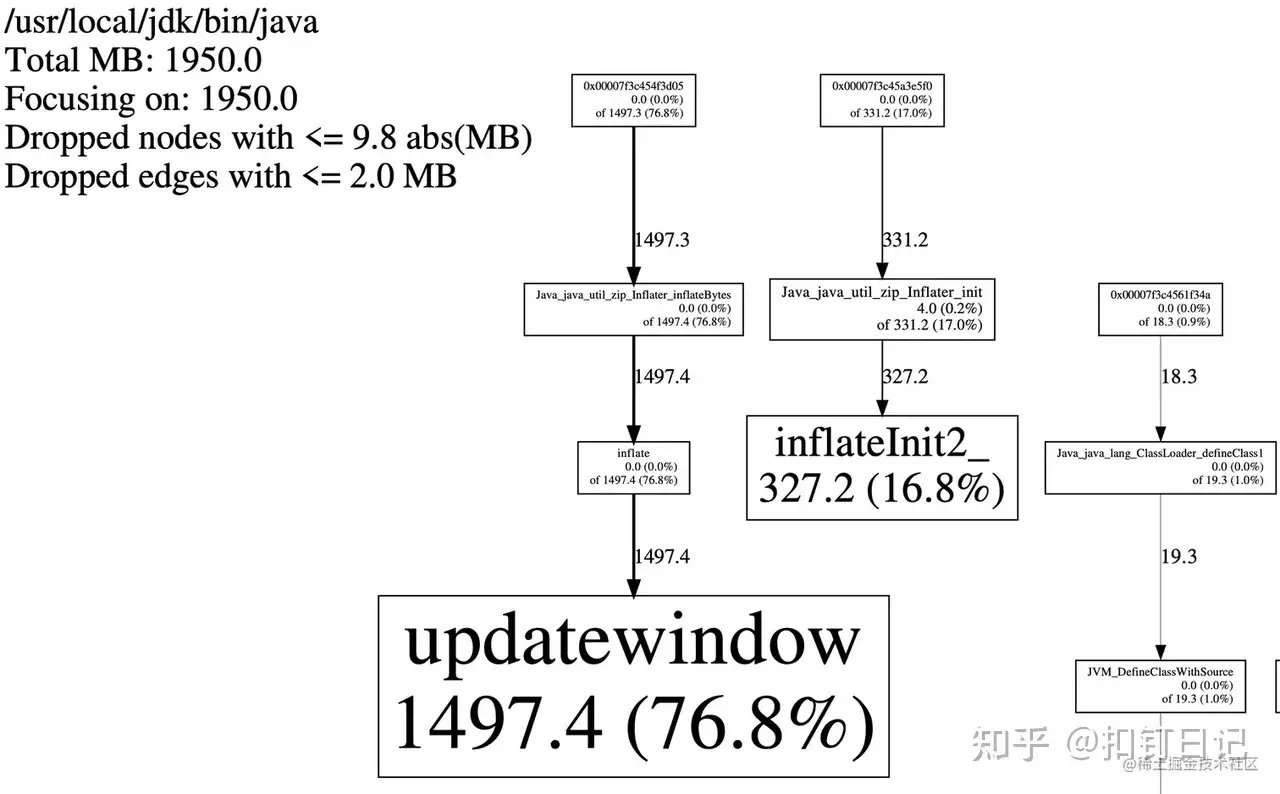
pprof --pdf /path/to/java heap.log.xx.heap > test.pdf
tcmalloc下载地址:https://github.com/gperftools/gperftools
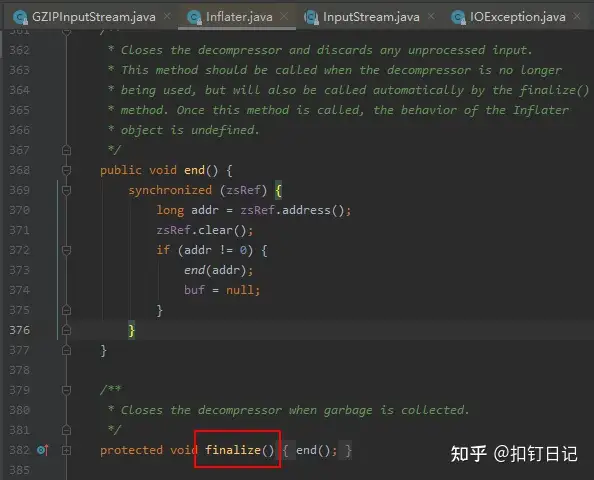
如上,可以发现内存泄露点来自Inflater对象的init和inflateBytes方法,而这些方法是通过JNI调用实现的,它会申请native内存,经过检查代码,发现GZIPInputStream确实会创建并使用Inflater对象,如下:

而它的close方法,会调用Inflater的end方法来归还native内存,由于我们没有调用close方法,故相关联的native内存无法归还。

可以发现,tcmalloc的泄露检测只能看到native栈,如想看到Java栈,可考虑配合使用arthas的profile命令,如下:
# 获取调用inflateBytes时的调用栈
profiler execute 'start,event=Java_java_util_zip_Inflater_inflateBytes,alluser'
# 获取调用malloc时的调用栈
profiler execute 'start,event=malloc,alluser'
如果代码不修复,内存会一直涨吗?
经过查看代码,发现Inflater实现了finalize方法,而finalize方法调用了end方法。
也就是说,若GC时Inflater对象被回收,相关联的原生内存是会被free的,所以内存会一直涨下去导致进程被oom kill吗?maybe,这取决于GC触发的阈值,即在GC触发前JVM中会保留的垃圾Inflater对象数量,保留得越多native内存占用越大。
但我发现一个有趣现象,我通过jcmd强行触发了一次Full GC,如下:
jcmd 1 GC.run
理论上native内存应该会free,但我通过top观察进程rss,发现基本没有变化,但我检查malloc_stats的输出,发现in use bytes确实少了许多,这说明Full GC后,JVM确实归还了Inflater对象关联的原生内存,但它们都被glibc缓存起来了,并没有归还给操作系统。
于是我再执行了一次malloc_trim,强制glibc归还缓存的内存,发现进程的rss降了下来。
编码最佳实践
这个问题是由于InputStream流对象未关闭导致的,在Java中流对象(FileInputStream)、网络连接对象(Socket)一般都关联了原生资源,记得在finally中调用close方法归还原生资源。
而GZIPInputstream、Inflater是JVM堆外内存泄露的常见问题点,review代码发现有使用这些类时,需要保持警惕。
JVM内存常见疑问
为什么我设置了-Xmx为10G,top中看到的rss却大于10G?
根据上面的介绍,JVM内存占用分布大概如下:

可以发现,JVM内存占用主要包含如下部分:
- Java堆,-Xmx选项限制的就是Java堆的大小,可通过jcmd命令观测。
- Java非堆,包含Metaspace、Code Cache、直接内存(DirectByteBuffer、MappedByteBuffer)、Thread、GC,它可通过arthas memory命令或NMT原生内存追踪观测。
- native分配内存,即直接调用malloc分配的,如JNI调用、磁盘与网络io操作等,可通过pmap命令、malloc_stats函数观测,或使用tcmalloc检测泄露点。
- glibc缓存的内存,即JVM调用free后,glibc库缓存下来未归还给操作系统的部分,可通过pmap命令、malloc_stats函数观测。
所以-Xmx的值,一定要小于容器/物理机的内存限制,根据经验,一般设置为容器/物理机内存的65%左右较为安全,可考虑使用比例的方式代替-Xms与-Xmx,如下:
-XX:MaxRAMPercentage=65.0 -XX:InitialRAMPercentage=65.0 -XX:MinRAMPercentage=65.0
top中VIRT与RES是什么区别?
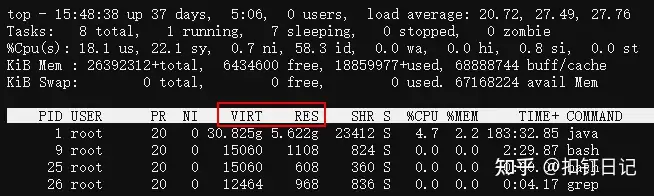
image_2023-08-26_20230826181236
- VIRT:进程申请的虚拟内存总大小。
- RES:进程在读写它申请的虚拟内存页面后,会触发Linux的内存缺页中断,进而导致Linux为该页分配实际内存,即RSS,在top中叫RES。
- SHR:进程间共享的内存,如libc.so这个C动态库,几乎会被所有进程加载到各自的虚拟内存空间并使用,但Linux实际只分配了一份内存,各个进程只是通过内存页表关联到此内存而已,注意,RSS指标一般也包含SHR。
通过top、ps或pidstat可查询进程的缺页中断次数,如下:
top中可以通过f交互指令,将mMin、mMaj列显示出来。



minflt表示轻微缺页,即Linux分配了一个内存页给进程,而majflt表示主要缺页,即Linux除了要分配内存页外,还需要从磁盘中读取数据到内存页,一般是内存swap到了磁盘后再访问,或使用了内存映射技术读取文件。
为什么top中JVM进程的VIRT列(虚拟内存)那么大?
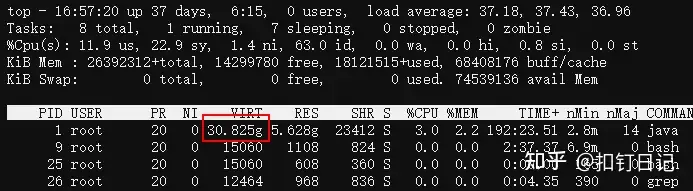
可以看到,我们一Java服务,申请了约30G的虚拟内存,比RES实际内存5.6G大很多。
这是因为glibc为了解决多线程内存申请时的锁竞争问题,创建了多个内存分配区Arena,然后每个Arena都有一把锁,特定的线程会hash到特定的Arena中去竞争锁并申请内存,从而减少锁开销。
但在64位系统里,每个Arena去系统申请虚拟内存的单位是64M,然后按需拆分为小块分配给申请方,所以哪怕线程在此Arena中只申请了1K内存,glibc也会为此Arena申请64M。
64位系统里glibc创建Arena数量的默认值为CPU核心数的8倍,而我们容器运行在32核的机器,故glibc会创建32*8=256个Arena,如果每个Arena最少申请64M虚拟内存的话,总共申请的虚拟内存为256*64M=16G。
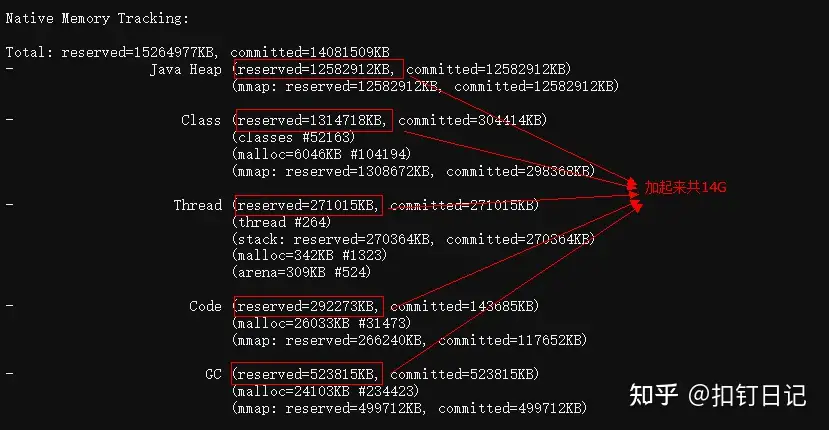
然后JVM是直接通过mmap申请的堆、MetaSpace等内存区域,不走glibc的内存分配器,这些加起来大约14G,与走glibc申请的16G虚拟内存加起来,总共申请虚拟内存30G!
当然,不必惊慌,这些只是虚拟内存而已,它们多一些并没有什么影响,毕竟64位进程的虚拟内存空间有2^48字节那么大!
为什么jvm启动后一段时间内内存占用越来越多,存在内存泄露吗?
如下,是我们一服务重启后运行快2天的内存占用情况,可以发现内存一直从45%涨到了62%,8G的容器,上涨内存大小为1.36G!
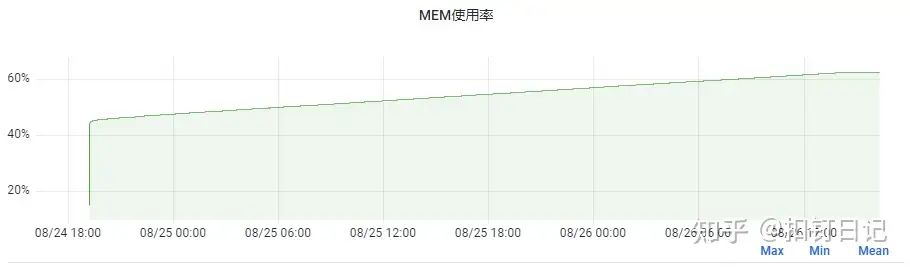
但我们这个服务其实没有内存泄露问题,因为JVM为堆申请的内存是虚拟内存,如4.8G,但在启动后JVM一开始可能实际只使用了3G内存,导致Linux实际只分配了3G。
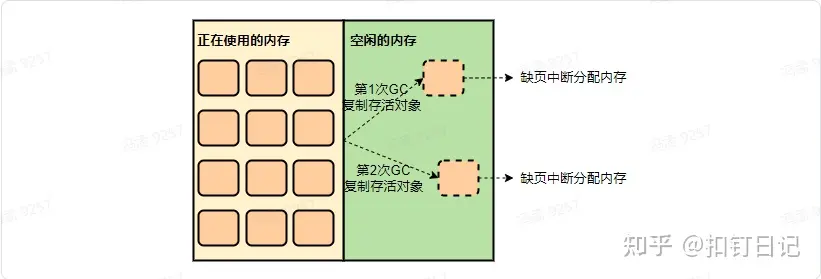
然后在gc时,由于会复制存活对象到堆的空闲部分,如果正好复制到了以前未使用过的区域,就又会触发Linux进行内存分配,故一段时间内内存占用会越来越多,直到堆的所有区域都被touch到。
而通过添加JVM参数-XX:+AlwaysPreTouch,可以让JVM为堆申请虚拟内存后,立即把堆全部touch一遍,使得堆区域全都被分配物理内存,而由于Java进程主要活动在堆内,故后续内存就不会有很大变化了,我们另一服务添加了此参数,内存表现如下:
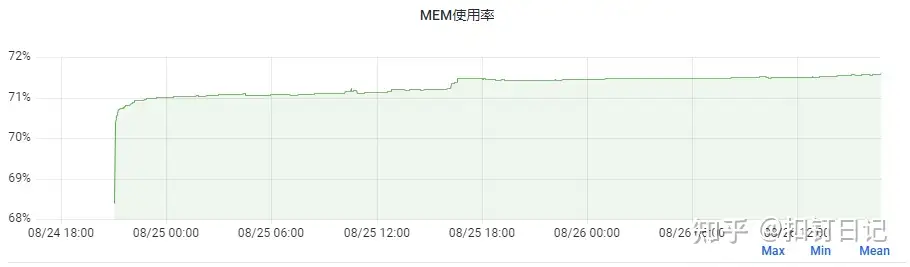
可以看到,内存上涨幅度不到2%,无此参数可以提高内存利用度,加此参数则会使应用运行得更稳定。
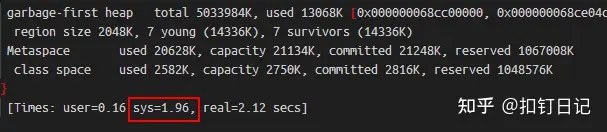
如我们之前一服务一周内会有1到2次GC耗时超过2s,当我添加此参数后,再未出现过此情况。这是因为当无此参数时,若GC访问到了未读写区域,会触发Linux分配内存,大多数情况下此过程很快,但有极少数情况下会较慢,在GC日志中则表现为sys耗时较高。
参考文章
https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
https://juejin.cn/post/7078624931826794503
https://juejin.cn/post/69033638
https://zhuanlan.zhihu.com/p/652545321

 浙公网安备 33010602011771号
浙公网安备 33010602011771号