
见了鬼,我JVM的Survivor区怎么只有20M了?
背景
某一天,有一位同学在群里发来一张 jmap -heap 内存使用情况图。
说 Survivor 区占比总是在 98% 以上。
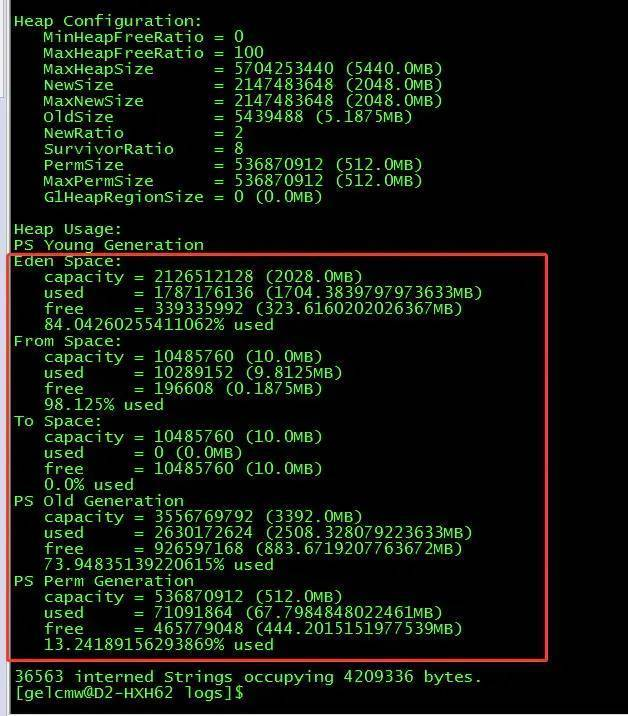
仔细观察这张图,其中包含几个重要信息:
- From 和 To 区都比较小,只有 10M。容量比较小,才显得占比高。
- Old 区的占比和使用量(两个多 G)都比较高。
此外,还可以看到 Eden、From、To 之间的比例不是默认的 8:1:1。
于是,立马就想到 AdaptiveSizePolicy。
经群友的确认,使用的是 JDK 1.8 的默认回收算法。
JVM 参数配置如下:

参数中没有对 GC 算法进行配置,即使用默认的 UseParallelGC。
用默认参数启动一个基于 JDK 1.8 的应用,然后使用 jinfo -flags pid 即可查看默认配置的 GC 算法。
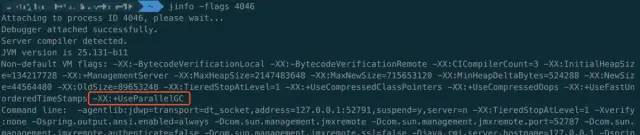
默认开启 AdaptiveSizePolicy
AdaptiveSizePolicy(自适应大小策略) 是 JVM GC Ergonomics(自适应调节策略) 的一部分。
如果开启 AdaptiveSizePolicy,则每次 GC 后会重新计算 Eden、From 和 To 区的大小,计算依据是 GC 过程中统计的 GC 时间、吞吐量、内存占用量。
JDK 1.8 默认使用 UseParallelGC 垃圾回收器,该垃圾回收器默认启动了 AdaptiveSizePolicy。
AdaptiveSizePolicy 有三个目标:
- Pause goal:应用达到预期的 GC 暂停时间。
- Throughput goal:应用达到预期的吞吐量,即应用正常运行时间 / (正常运行时间 + GC 耗时)。
- Minimum footprint:尽可能小的内存占用量。
AdaptiveSizePolicy 为了达到三个预期目标,涉及以下操作:
- 如果 GC 停顿时间超过了预期值,会减小内存大小。理论上,减小内存,可以减少垃圾标记等操作的耗时,以此达到预期停顿时间。
- 如果应用吞吐量小于预期,会增加内存大小。理论上,增大内存,可以降低 GC 的频率,以此达到预期吞吐量。
- 如果应用达到了前两个目标,则尝试减小内存,以减少内存消耗。
注:AdaptiveSizePolicy 涉及的内容比较广,本文主要关注 AdaptiveSizePolicy 对年轻代大小的影响,以及随之产生的问题。
AdaptiveSizePolicy 看上去很智能,但有时它也很调皮,会引发 GC 问题。
即使 SurvivorRatio 的默认值是 8,但年轻代三个区域之间的比例仍会变动。
这个问题,可以参考来自R大的回答:
hllvm.group.iteye.com/group/topic…
HotSpot VM里,ParallelScavenge系的GC(UseParallelGC / UseParallelOldGC)默认行为是SurvivorRatio如果不显式设置就没啥用。显式设置到跟默认值一样的值则会有效果。
因为ParallelScavenge系的GC最初设计就是默认打开AdaptiveSizePolicy的,它会自动、自适应的调整各种参数。
在群友的截图中,From 区只有 10M,Eden 区占用了却超过年轻代八成的空间。
其原因是 AdaptiveSizePolicy 为了达到期望的目标而进行了调整。
大概定位了 Survivor 区小的原因,还有一个问题:
为什么老年代的占比和使用量都比较高?
于是群友使用 jmap -histo 查看堆中的实例。
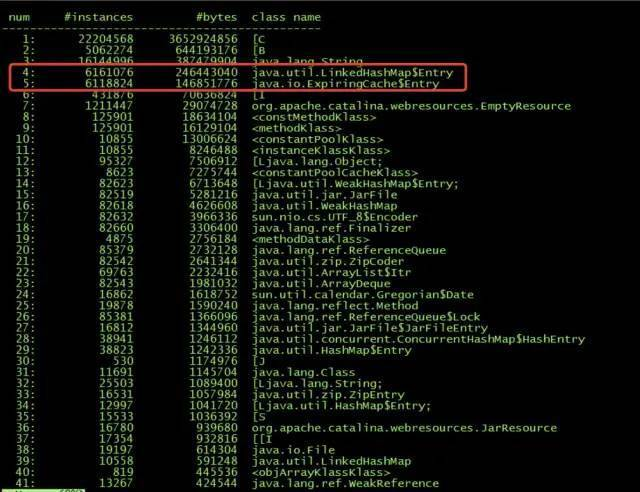
可以看出,其中有两个类的实例比较多,分别是:
- LinkedHashMap$Entry
- ExpiringCache$Entry
于是,搜索关键类 ExpiringCache。
可以看出在 ExpiringCache 的构造函数中,初始化了一个 LinkedHashMap。
怀疑 LinkedHashMapEntry 直接有关。
ExpiringCache(long millisUntilExpiration) { this.millisUntilExpiration = millisUntilExpiration; map = new LinkedHashMap<String,Entry>() { protected boolean removeEldestEntry(Map.Entry<String,Entry> eldest) { return size() > MAX_ENTRIES; } }; }
注:该 map 用于保存缓存数据,设置了淘汰机制。当 map 大小超过 MAX_ENTRIES = 200 时,会开始淘汰。
接着查看 ExpiringCache$Entry 类。
这个类的主要属性是「时间戳」和「值」,时间戳用于超时淘汰(缓存常用手法)。
static class Entry { private long timestamp; private String val; …… }
接着查看哪里使用到了这个缓存。
于是找到 get 方法,定位到只有一个类的一个方法使用到了这个缓存。

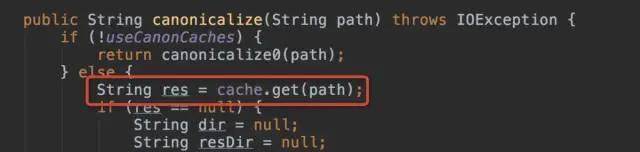
接着往上层找,看到了一个熟悉的类:File,它的 getCanonicalPath() 方法使用到了这个缓存。
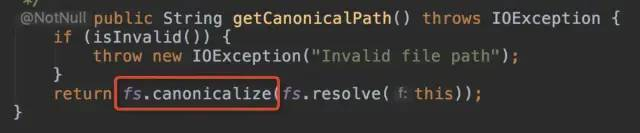
该方法用于获取文件路径。
于是,询问群友,是否在项目中使用了 getCanonicalPath() 方法。
得到的回答是肯定的。
当项目中使用 getCanonicalPath() 方法获取文件路径时,会发生以下的事情:
- 首先从缓存中读取,取不到则需要生成缓存。
- 生成缓存需要新建 ExpiringCache$Entry 对象用于保存缓存值,这些新建的对象都会被分配到 Eden 区。
- 当大量使用 getCanonicalPath() 方法时,缓存数量超过 MAX_ENTRIES = 200 开启淘汰策略。原来 map 中的 ExpiringCache$Entry 对象变成垃圾对象,真正存活的 Entry 只有 200 个。
- 当发生 YGC 时,理论上存活的 200 个 Entry 会去往 To 区,其他被淘汰的垃圾 Entry 对象会被回收。
- 但由于 AdaptiveSizePolicy 将 To 区调整到只有 10MB,装不下本该移动到 To 区的对象,只能直接移动到老年代。
- 于是,在每次 YGC 时,会有接近 200 个存活的 ExpiringCache$Entry 对象进入到老年代。随着缓存淘汰机制的运行,这些 Entry 对象立马又变成垃圾。
- 当对象进入老年代,即使变成了垃圾,也需要等到老年代 GC 或者 FGC 才能将其回收。由于老年代容量较大,可以承受多次 YGC 给予的 200 个 ExpiringCache$Entry 对象。
- 于是,老年代使用量逐渐变高。
老年代内存占用量高的问题也定位到了。
因为每次 YGC 只有 200 个实例进入到老年代,问题显得比较温和。
只是隔一段时间触发 FGC,应用运行看似正常。
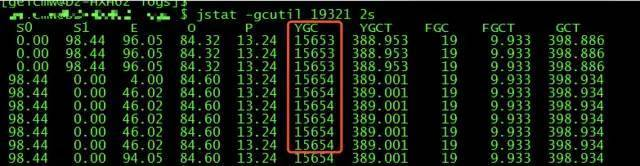
接着使用 jstat -gcutil 查看 GC 情况。
可以看到从应用启动,一共发生了 15654 次 YGC。
推算每次 YGC 有 200 个 ExpiringCache$Entry 对象进入老年代。
那么,老年代中大约存在 3130800 个 ExpiringCache$Entry 对象。
从之前的 jmap -histo 结果中看到,ExpiringCache$Entry 对象的数量是 6118824 个。
两个数目都为百万级。其余约 300W 个实例应该都在 Eden 区。
每一次 YGC 后,都会有大量的 ExpiringCache$Entry 对象被回收。
从群友截取的 GC log 中可以看出,YGC 的频率大概为 23 秒一次。

假设运行的 jmap -histo 命令是在即将触发 YGC 之前。
那么,应用大概在 20s 的事件内产生了 300W 个 ExpiringCache$Entry 实例,1s 内产生约 15W 个。
假设单机 QPS = 300,一次请求产生的 ExpiringCache$Entry 实例数约为 500 个。
猜测是在循环体中使用了 getCanonicalPath() 方法。
至此可以得出 Survior 区变小,老年代占比变高的原因:
- 在默认 SurvivorRatio = 8 的情况下,没有达到吞吐量的期望,AdaptiveSizePolicy 加大了 Eden 区的大小。From 和To 区被压缩到只有 10M。
- 在项目中大量使用 getCanonicalPath() 方法,产生大量ExpiringCache$Entry 实例。
- 当 YGC 发生时候,由于 To 区太小,存活的 Entry 对象直接进入到老年代。老年代占用量逐渐变大。
从群友的 jstat -gcutil 截图中还可以看出,应用从启动到使用该命令,触发了 19 次 FGC,一共耗时 9.933s,平均每次 FGC 耗时为 520ms。
这样的停顿时间,对于一个高 QPS 的应用是无法忍受的。
定位到了问题的原因,解决方案比较简单。
解决的思路有两个:
- 不使用缓存,就不会生成大量 ExpiringCache$Entry 实例。
- 阻止 AdaptiveSizePolicy 缩小 To 区。让 YGC 时存活的 ExpiringCache$Entry 对象都能顺利进入 To 区,保留在年轻代,而不是进入老年代。
解决方案一:
不使用缓存。
使用 -Dsun.io.useCanonCaches = false 参数即可关闭缓存。
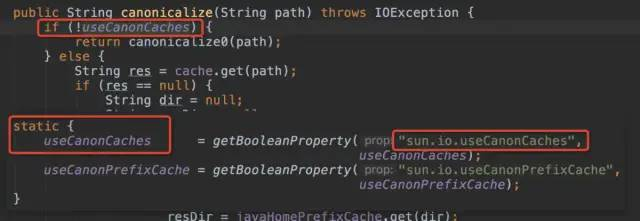
这种方案解决比较方便,但这个参数并非常规参数,慎用。
解决方案二:
保持使用 UseParallelGC,显式设置 -XX:SurvivorRatio=8。
配置参数进行测试:
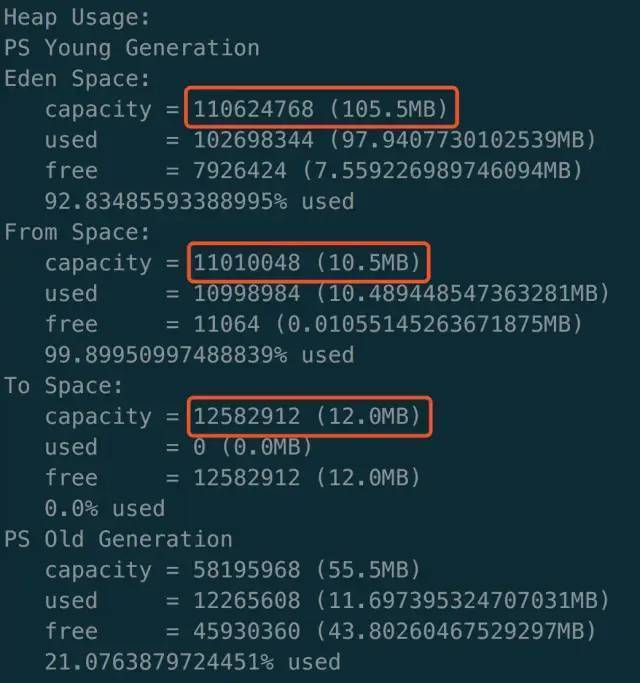
看到默认配置下,三者之间的比例不是 8:1:1。
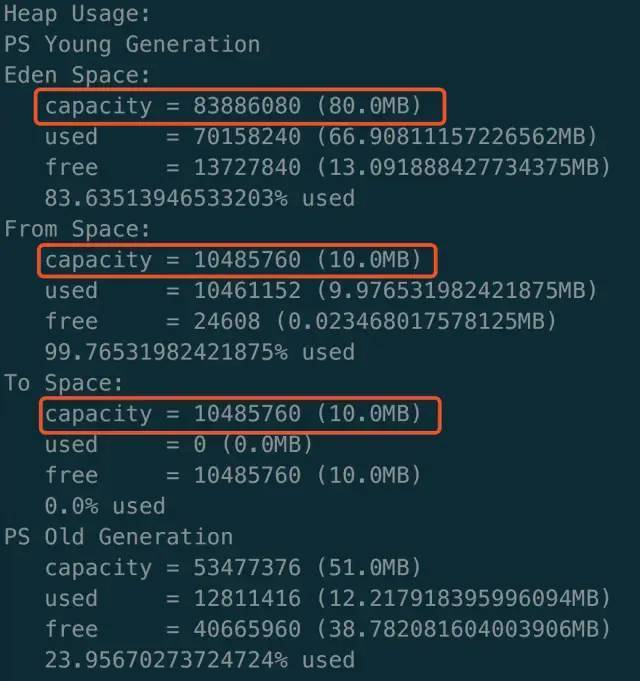
可以看到,加上参数 -Xmn100m -XX:SurvivorRatio=8 参数后,固定了 Eden 和 Survivor 之间的比例。
解决方案三:
使用 CMS 垃圾回收器。
CMS 默认关闭 AdaptiveSizePolicy。
配置参数 -XX:+UseConcMarkSweepGC,通过 jinfo 命令查看,可以看到 CMS 默认减去/不使用 AdaptiveSizePolicy。

群友也是采用了这个方法:
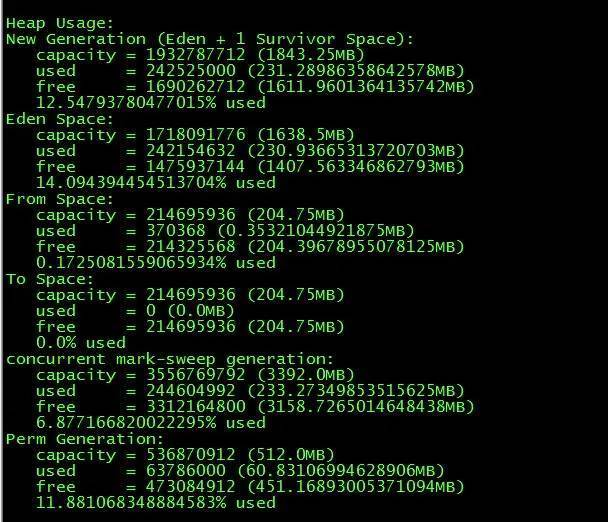
可以看出,Eden 和 Survivor 之间的比例被固定,To 区没有被缩小。老年代的使用量和使用率也都很正常。
三、源码层面了解 AdaptiveSizePolicy
注:以下源码均主要基于 openjdk 8,不同 jdk 版本之间会有区别。
对源码的理解程度有限,对源码的理解也一直在路上。
有任何错误,还请各位指正,谢谢。
首先解释,为什么在 UseParallelGC 回收器的前提下,显式配置 SurvivorRatio 即可固定年轻代三个区域之间的比例。
在 arguments.cpp 类中有一个 set_parallel_gc_flags() 方法。
从方法命名来看,是为了设置并行回收器的参数。
// If InitialSurvivorRatio or MinSurvivorRatio were not specified, but the // SurvivorRatio has been set, reset their default values to SurvivorRatio + // 2\. By doing this we make SurvivorRatio also work for Parallel Scavenger. // See CR 6362902 for details. if (!FLAG_IS_DEFAULT(SurvivorRatio)) { if (FLAG_IS_DEFAULT(InitialSurvivorRatio)) { FLAG_SET_DEFAULT(InitialSurvivorRatio, SurvivorRatio + 2); } if (FLAG_IS_DEFAULT(MinSurvivorRatio)) { FLAG_SET_DEFAULT(MinSurvivorRatio, SurvivorRatio + 2); } }
当显式设置 SurvivorRatio,即 !FLAG_IS_DEFAULT(SurvivorRatio),该方法会设置别的参数。
方法注释上写着:
make SurvivorRatio also work for Parallel Scavenger 通过显式设置 SurvivorRatio 参数,SurvivorRatio 就会在 Parallel Scavenge 回收器中生效。
至于为何会生效,还有待进一步学习。
而默认是会被 AdaptiveSizePolicy 调整的。
接着查看 AdaptiveSizePolicy 动态调整内存大小的代码。
JDK 1.8 默认的 UseParallelGC 回收器,其对应的年轻代回收算法是 Parallel Scavenge。
触发 GC 的原因有多种,最普通的一种是在年轻代分配内存失败。
UseParallelGC 分配内存失败引发 GC 的入口位于 vmPSOperations.cpp 类的 VM_ParallelGCFailedAllocation::doit() 方法。
之后依次调用了以下方法:
parallelScavengeHeap.cpp 类的 failed_mem_allocate(size_t size) 方法。
psScavenge.cpp 类的 invoke()、invoke_no_policy() 方法。
invoke_no_policy() 方法中有一段代码涉及 AdaptiveSizePolicy。
if (UseAdaptiveSizePolicy) { …… size_policy->compute_eden_space_size(young_live, eden_live, cur_eden, max_eden_size, false /* not full gc*/); …… }
在 GC 主过程完成后,如果开启 UseAdaptiveSizePolicy 则会重新计算 Eden 区的大小。
在 compute_eden_space_size 方法中,有几个判断。
对应 AdaptiveSizePolicy 的三个目标:
- 与预期 GC 停顿时间对比。
- 与预期吞吐量对比。
- 如果达到预期,则调整内存容量。
if ((_avg_minor_pause->padded_average() > gc_pause_goal_sec()) || (_avg_major_pause->padded_average() > gc_pause_goal_sec())) { adjust_eden_for_pause_time(is_full_gc, &desired_promo_size, &desired_eden_size); } else if (_avg_minor_pause->padded_average() > gc_minor_pause_goal_sec()) { adjust_eden_for_minor_pause_time(is_full_gc, &desired_eden_size); } else if(adjusted_mutator_cost() < _throughput_goal) { assert(major_cost >= 0.0, "major cost is < 0.0"); assert(minor_cost >= 0.0, "minor cost is < 0.0"); adjust_eden_for_throughput(is_full_gc, &desired_eden_size); } else { if (UseAdaptiveSizePolicyFootprintGoal && young_gen_policy_is_ready() && avg_major_gc_cost()->average() >= 0.0 && avg_minor_gc_cost()->average() >= 0.0) { size_t desired_sum = desired_eden_size + desired_promo_size; desired_eden_size = adjust_eden_for_footprint(desired_eden_size, desired_sum); } } 详细看其中一个判断。
if ((_avg_minor_pause->padded_average() > gc_pause_goal_sec()) || (_avg_major_pause->padded_average() > gc_pause_goal_sec())) 如果统计的 YGC 或者 Old GC 时间超过了目标停顿时间,则会调用 adjust_eden_for_pause_time 调整 Eden 区大小。
gc_pause_goal_sec() 方法获取预期停顿时间,在 ParallelScavengeHeap::initialize() 方法中,通过读取 JVM 参数 MaxGCPauseMillis 获取。

接下来,再看 CMS 回收器。
CMS 初始化分代位于 cmsCollectorPolicy.cpp 类的 initialize_generations() 方法。
if (UseParNewGC) { if (UseAdaptiveSizePolicy) { _generations[0] = new GenerationSpec(Generation::ASParNew, _initial_gen0_size, _max_gen0_size); } else { _generations[0] = new GenerationSpec(Generation::ParNew, _initial_gen0_size, _max_gen0_size); } } else { _generations[0] = new GenerationSpec(Generation::DefNew, _initial_gen0_size, _max_gen0_size); } if (UseAdaptiveSizePolicy) { _generations[1] = new GenerationSpec(Generation::ASConcurrentMarkSweep, _initial_gen1_size, _max_gen1_size); } else { _generations[1] = new GenerationSpec(Generation::ConcurrentMarkSweep, _initial_gen1_size, _max_gen1_size); }
其中 _generations[0] 代表年轻代特征,_generations[1] 代表老年代特征。
如果设置不同的 UseParNewGC 、UseAdaptiveSizePolicy 参数,会对年轻代和老年代使用不同的策略。
CMS 垃圾回收入口位于 genCollectedHeap.cpp 类的 do_collection 方法。
在 do_collection 方法中,GC 主过程完成后,会对每个分代进行大小调整。
for (int j = max_level_collected; j >= 0; j -= 1) { // Adjust generation sizes. _gens[j]->compute_new_size(); }
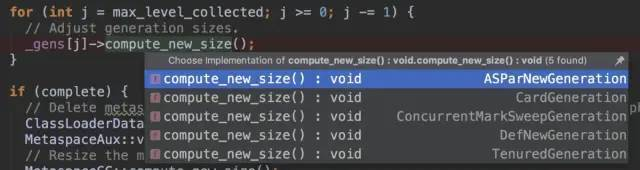
本文主要讨论 AdaptiveSizePolicy 对年轻代的影响,主要看 ASParNewGeneration 类,其中的 AS 前缀就是 AdaptiveSizePolicy 的意思。
如果设置 -XX:+UseAdaptiveSizePolicy 则年轻代对应 ASParNewGeneration 类,否则对应 ParNewGeneration 类。
在 ASParNewGeneration 类中 compute_new_size() 方法中,调用了另一个方法调整 Eden 区大小。
size_policy->compute_eden_space_size(eden()->capacity(), max_gen_size());
该方法与 Parallel Scavenge 的 compute_eden_space_size 方法类似,也从三个方面对内存大小进行调整,分别是:
- adjust_eden_for_pause_time
- adjust_eden_for_throughput
- adjust_eden_for_footprint
接着进行测试,设置参数 -XX:+UseAdaptiveSizePolicy、 -XX:+UseConcMarkSweepGC。
期望 CMS 会启用 AdaptiveSizePolicy,但根据 jmap -heap 结果查看,并没有启动,年轻代三个区域之间的比例为 8:1:1。
从 jinfo 命令结果也可以看出,即使设置了 -XX:+UseAdaptiveSizePolicy,仍然关闭了 AdaptiveSizePolicy。

因为在 JDK 1.8 中,如果使用 CMS,无论 UseAdaptiveSizePolicy 如何设置,都会将 UseAdaptiveSizePolicy 设置为 false。
查看 arguments.cpp 类中的 set_cms_and_parnew_gc_flags 方法,其调用了 disable_adaptive_size_policy 方法将 UseAdaptiveSizePolicy 设置成 false。
static void disable_adaptive_size_policy(const char* collector_name) { if (UseAdaptiveSizePolicy) { if (FLAG_IS_CMDLINE(UseAdaptiveSizePolicy)) { warning("disabling UseAdaptiveSizePolicy; it is incompatible with %s.", collector_name); } FLAG_SET_DEFAULT(UseAdaptiveSizePolicy, false); } }
如果是在启动参数中设置了,则会打出提醒。

但在 JDK 1.6 和 1.7 中,set_cms_and_parnew_gc_flags 方法的逻辑和 1.8 中的不同。
如果 UseAdaptiveSizePolicy 参数是默认的,则强制设置成 false。
如果显式设置(complete),则不做改变。
// Turn off AdaptiveSizePolicy by default for cms until it is // complete. if (FLAG_IS_DEFAULT(UseAdaptiveSizePolicy)) { FLAG_SET_DEFAULT(UseAdaptiveSizePolicy, false); }
于是尝试使用 JDK 1.6 搭建 web 应用,加上 -XX:+UseAdaptiveSizePolicy、-XX:+UseConcMarkSweepGC 两个参数。
再用 jinfo -flag 查看,看到两个参数都被置为 true。

接着,使用 jmap -heap 查看堆内存使用情况,发现展示不了信息。
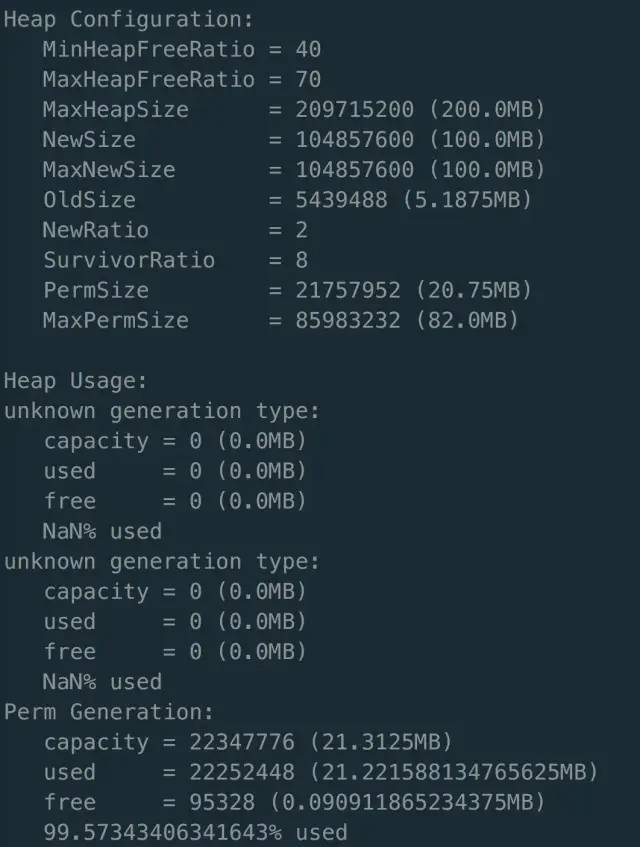
这其实是 JDK 低版本的一个 Bug。
1.6.30以上到1.7的全部版本已经确认有该问题,jdk8修复。
四、问题小结
- 现阶段大多数应用使用 JDK 1.8,其默认回收器是 Parallel Scavenge,并且默认开启了 AdaptiveSizePolicy。
- AdaptiveSizePolicy 动态调整 Eden、Survivor 区的大小,存在将 Survivor 区调小的可能。当 Survivor 区被调小后,部分 YGC 后存活的对象直接进入老年代。老年代占用量逐渐上升从而触发 FGC,导致较长时间的 STW。
- 建议使用 CMS 垃圾回收器,默认关闭 AdaptiveSizePolicy。
- 建议在 JVM 参数中加上 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution,让 GC log 更加详细,方便定位问题。
链接:https://juejin.cn/post/6844904192537018381
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号