图解 SQL 的执行顺序,优雅
SQL是一个声明式语言
一个完整的SQL语句会告诉MySql server 要从那些表中查数据【得到数据集】,
对得到的数据集按什么条件进行筛选【where】,
按什么规则进行分组、计算聚合函数的值【group by】,
对分组后的数据进行筛选【having】,
如果没有分组,check distinct操作,
对符合条件的数据进行order by
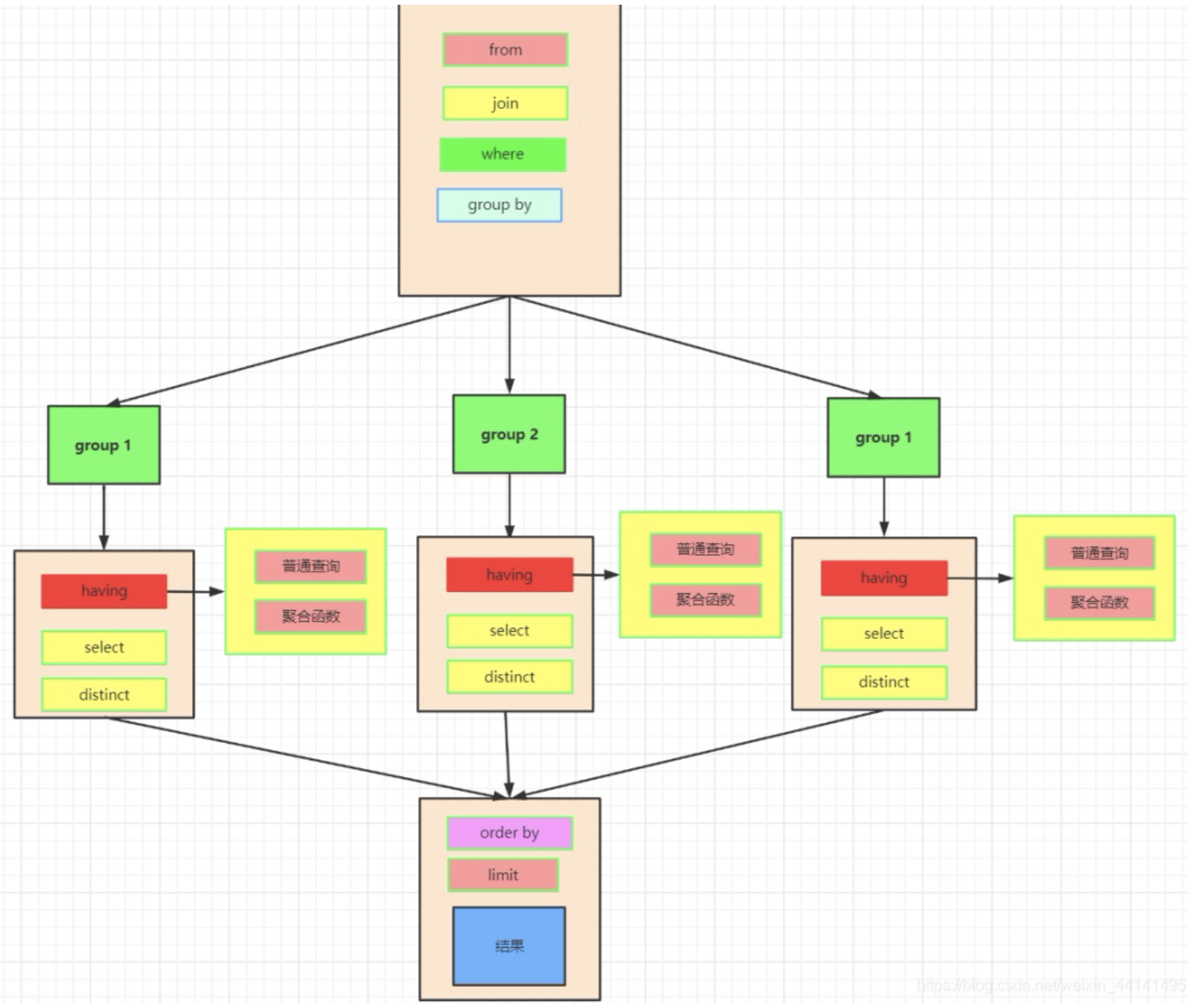
这是一条标准的查询语句:

这是我们实际上SQL执行顺序:
-
我们先执行from,join来确定表之间的连接关系,得到初步的数据
-
where对数据进行普通的初步的筛选
-
group by 分组
-
各组分别执行having中的普通筛选或者聚合函数筛选。
-
然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段
-
将查询结果去重distinct
- 最后合并各组的查询结果,按照order by的条件进行排序
数据的关联过程
数据库中的两张表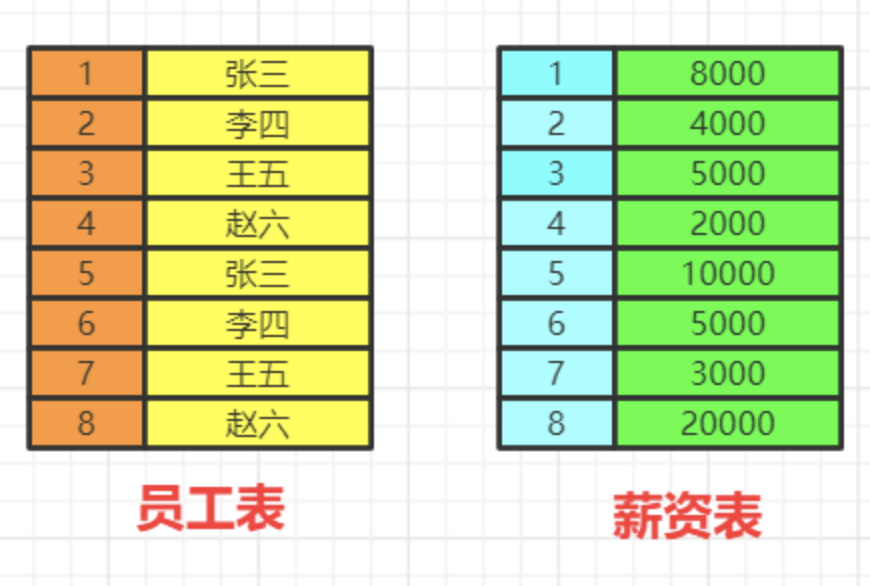
from&join&where
用于确定我们要查询的表的范围,涉及哪些表。
选择一张表,然后用join连接
from table1 join table2 on table1.id=table2.id
选择多张表,用where做关联条件
from table1,table2 where table1.id=table2.id
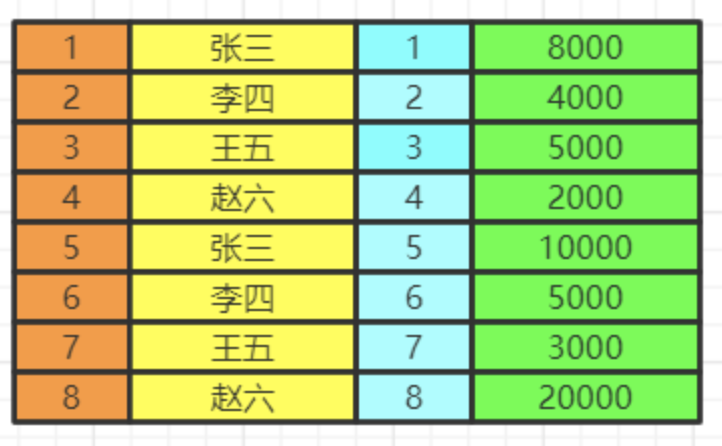
我们会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。
group by
按照我们的分组条件,将数据进行分组,但是不会筛选数据。
比如我们按照即id的奇偶分组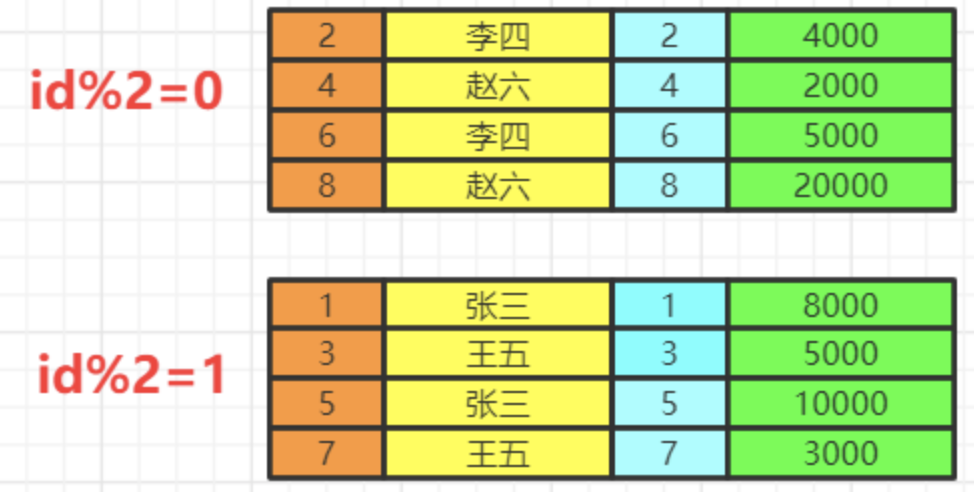
having&where
having中可以是普通条件的筛选,也能是聚合函数。而where只能是普通函数,一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。
使用where再group by
先把不满足where条件的数据删除,再去分组
使用group by再having
先分组再删除不满足having条件的数据,这两种方法有区别吗,几乎没有!
微信搜索公众号:架构师指南,回复:架构师 领取资料 。
举个例子:
100/2=50,此时我们把100拆分(10+10+10+10+10…)/2=5+5+5+…+5=50,只要筛选条件没变,即便是分组了也得满足筛选条件,所以where后group by 和group by再having是不影响结果的!
不同的是,having语法支持聚合函数,其实having的意思就是针对每组的条件进行筛选。我们之前看到了普通的筛选条件是不影响的,但是having还支持聚合函数,这是where无法实现的。
当前数据分组情况
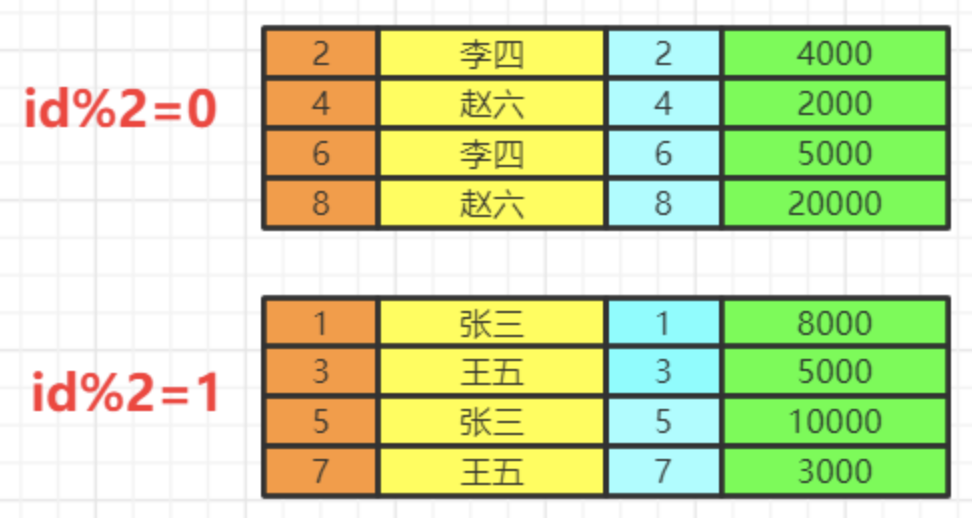
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的having salary<avg(salary)
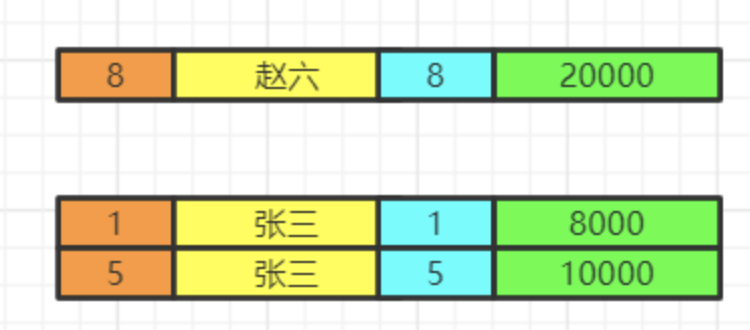
select
分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里用紫色表示,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。
select employee.id,distinct name,salary, avg(salary)
将各组having之后的数据再合并数据。

order by
最后我们执行order by 将数据按照一定顺序排序,比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。

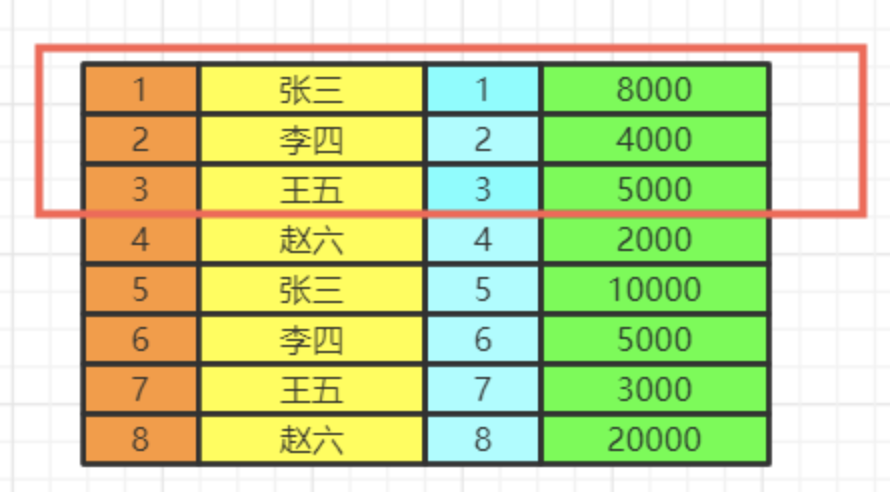
limit
记住limit是最后查询的,为什么呢?假如我们要查询年级最小的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最小的三个数据而是前三个数据了,记住这一点。
我们如果limit 0,3窃取前三个数据再排序,实际上最少工资的是2000,3000,4000。你这里只能是4000,5000,8000了。
原文:blog.csdn.net/weixin_44141495/article/details/108744720
如果没有指定Order by,查询结果会按什么顺序排序
如果在sql语句中不指定order by排序条件,那么得到的结果集的排序顺序是与查询列有关的。因为不同的查询列可能会用到不同的索引,从而导致顺序不同。根据上面的情况:查询所有列时是根据id排序的;只查询age列时是根据age列(age列是索引)排序的;而加上order by age后,因为待排序内容不能由所使用的索引直接完成排序,所以要进行文件排序,具体原因就不深究了。
看网上大神的说法是:没有条件的情况下,数据库默认排序顺序是不好确定的,也不应该决定于什么因素,不同的数据库实现不同.只能用order by 来限定。
反正,不要迷信mysql默认会按照你以为的顺序排序,想要排序就先给你想要排序的字段创建索引(提高效率),然后再order by这个字段进行排序。
https://blog.csdn.net/qq_35383263/article/details/81433693
影响查询结果排序的另一个配置MRR
首先我们需要搞清楚MySQL回表,回表是指在我们利用的索引树(比如上述语句用到的first_name字段索引)的数据不能满足我们select中选中的数据,因为first_name是二级索引(也可以说是非聚簇索引),该索引只能拿到emp_no,first_name字段值,索引select *查询的话就只能到主键索引所在的索引树上获取相应数据。
按照上述查询去first_name索引上匹配的话,我们匹配到的数据肯定是没法保证按照emp_no排序了,但是为啥最终我们看到的数据是按照emp_no排序了呢?其实这是mysql的mrr机制。
mrr想要达到的目的就是从磁盘的随机读变成顺序读,因为如果我们直接拿emp_no乱序的数据回表查询,那么就是一个随机读,这个性能是很差的,所以MySQL会在回表之前提前将emp_no数据排序好,这样回表就变成了顺序读,极大提高性能。

https://www.cnblogs.com/minjay/p/15598848.html
五、Multi-Range Read(MRR)优化
MySQL 5.6版本开始支持Multi-Range Read(MRR)优化。MRR优化的目的就是为了减少磁盘的随机访问,并且将随机访问转换为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升
MRR优化的好处:
MRR使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果按照主键进行排序,并按照主键排序的顺序进行书签查找
减少缓冲池中页被替换的次数
批量处理对键值的查询操作
对于InnoDB和MyISAM存储引擎的范围查询和JOIN查询操作,MRR工作方式如下:
将查询得到的辅助索引键值存放在一个缓存中,这是缓存中的数据是根据辅助索引键值排序的
将缓存中的键值根据RowID进行排序
根据RowID的排序顺序来访问实际的数据文件
此外,若InnoDB存储引擎或者MyISAM存储引擎的缓冲池不足够大,即不能存放下一张表中的所有数据,此时频繁的离散读操作还会导致缓存中的页被替换出缓冲池,然后有不断地被读入缓冲池。若按照主键顺序访问,则可以将重复行为降为最低
————————————————
版权声明:本文为CSDN博主「董哥的黑板报」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41453285/article/details/104231518
MySQL MRR
简介
MRR,全称「Multi-Range Read Optimization」。
简单说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
命令
mysql > set optimizer_switch='mrr=on';
另外还有一个参数mrr_cost_based: on/off
则是用来告诉优化器,要不要基于使用 MRR 的成本,考虑使用 MRR 是否值得(cost-based choice),来决定具体的 sql 语句里要不要使用 MRR。
很明显,对于只返回一行数据的查询,是没有必要 MRR 的,而如果你把 mrr_cost_based 设为 off,那优化器就会通通使用 MRR,这在有些情况下是很 stupid 的,所以建议这个配置还是设为 on,毕竟优化器在绝大多数情况下都是正确的。
开启前磁盘运动轨迹
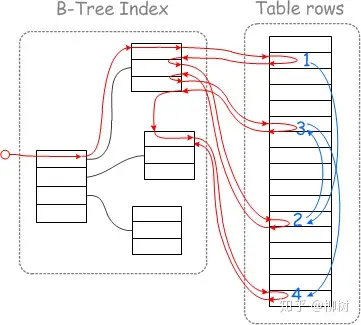
先到左边的二级索引找,找到第一条符合条件的记录(实际上每个节点是一个页,一个页可以有很多条记录,这里我们假设每个页只有一条),接着到右边去读取这条数据的完整记录。
读取完后,回到左边,继续找下一条符合条件的记录,找到后,再到右边读取
开启后磁盘运动轨迹
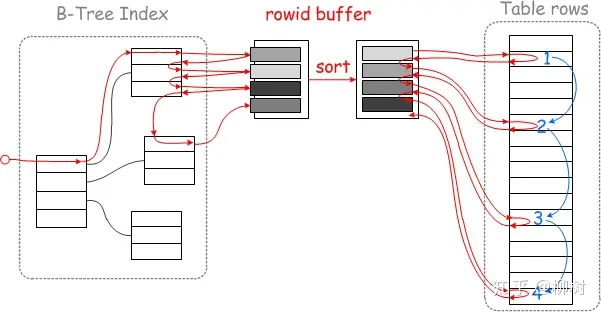
对于 Innodb,则会按照聚簇索引键值排好序,再顺序的读取聚簇索引。
优势
1、磁盘和磁头不再需要来回做机械运动;
2、可以充分利用磁盘预读
3、在一次查询中,每一页的数据只会从磁盘读取一次
https://www.jianshu.com/p/56bcf4f68600

 浙公网安备 33010602011771号
浙公网安备 33010602011771号