2-PageCachechan产生释放及优化
2-PageCache生产释放及优化
观察PageCache
page cache,又称pcache,其中文名称为页高速缓冲存储器 页缓存
Page Cache 有关的场景 故障场景
服务器的 load 飙高;
服务器的 I/O 吞吐飙高;
业务响应时延出现大的毛刺;
业务平均访问时延明显增加。
Page Cache 管理不当除了会增加系统 I/O 吞吐外,还会引起业务性能抖动 本文用数据剖析什么是 Page Cache,为什么需要 Page Cache,Page Cache 的产生和回收是什么样的
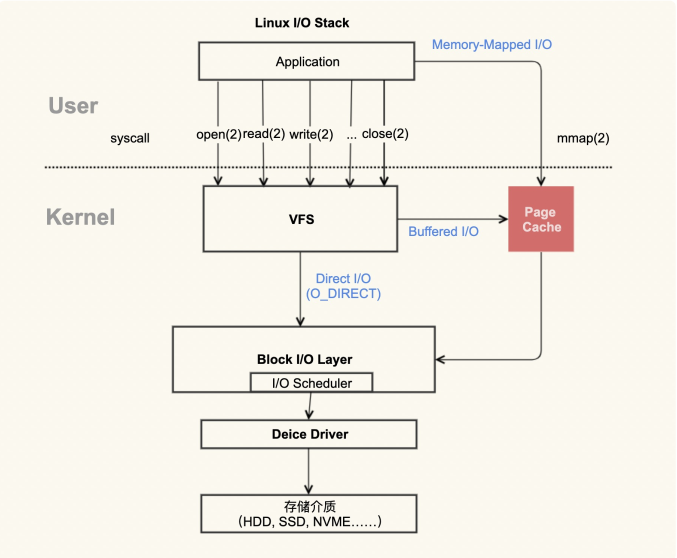
应用程序产生Page Cache的逻辑示意图
红色的地方就是 Page Cache,很明显,Page Cache是内核管理的内存,也就是说,它属于内核不属于用户
在 Linux 上直接查看 Page Cache 的方式有很多,包括 /proc/meminfo、free 、/proc/vmstat 命令等
/proc/meminfo 模式查看
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem +SwapCached
那么等式两边的内容就是我们平时说的 Page Cache 两边都是SwapCached
等式右边这些项把 Buffers 和 Cached 做了一下细分,分为了 Active(file),Inactive(file) 和 Shmem
Buffers 更加依赖于内核实现
等式右边和应用程序的关系更加直接
在 Page Cache 中,Active(file)+Inactive(file) 是 File-backed page(与文件对应的内存页),是你最需要关注的部分。因为你平时用的 mmap() 内存映射方式和 buffered I/O来消耗的内存就属于这部分,最重要的是,这部分在真实的生产环境上也最容易产生问题,我们在接下来的课程案例篇会重点分析它
SwapCached 是在打开了 Swap 分区后,把 Inactive(anon)+Active(anon) 这两项里的匿名页给交换到磁盘(swap out),然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的 Swap File 还在,所以 SwapCached 也可以认为是 File-backedpage,即属于 Page Cache。这样做的目的也是为了减少 I/O。
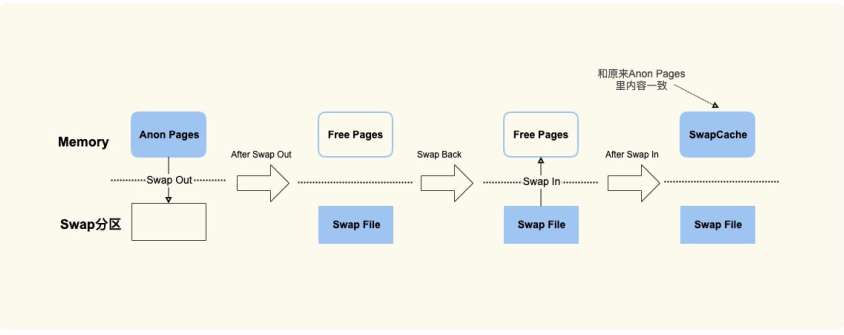
SwapCached 只在 Swap 分区打开的情况下才会有,而我建议你在生产环境中关闭Swap 分区,因为 Swap 过程产生的 I/O 会很容易引起性能抖动。
除了 SwapCached,Page Cache 中的 Shmem 是指匿名共享映射这种方式分配的内存(free 命令中 shared 这一项),比如 tmpfs(临时文件系统),这部分在真实的生产环境中**产生的问题比较少 ** 本专栏不做介绍
free 命令中的 buff/cache 究竟是指什么呢?我们在这里先简单地看一下:
$ free -k
total used free shared buff/cache availabl
Mem: 7926580 7277960 492392 10000 156228 43068
Swap: 8224764 380748 7844016
通过 procfs 源码里面的proc/sysinfo.c这个文件,你可以发现 buff/cache 包括下面这几项:
buff/cache = Buffers + Cached + SReclaimable
前面的数据我们也可以验证这个公式: 1224 + 111472 + 43532 的和是 156228
这些数据是动态变化的,而且执行命令本身也会带来内存开销,所以这个等式未必会严格相等
从这个公式中,你能看到 free 命令中的 buff/cache 是由 Buffers、Cached 和SReclaimable 这三项组成的,它强调的是内存的可回收性,也就是说,可以被回收的内存会统计在这一项。
其中 SReclaimable 是指可以被回收的内核内存,包括 dentry 和 inode 等。而这部分内容是内核非常细节性的东西, 本章不做介绍。
掌握了 Page Cache 具体由哪些部分构成之后,在它引发一些问题时,你就能够知道需要去观察什么。比如说,应用本身消耗内存(RSS)不多的情况下,整个系统的内存使用率还是很高,那不妨去排查下是不是 Shmem(共享内存) 消耗了太多内存导致的
如果不用内核管理的 Page Cache,那有两种思路来进行处理:
第一种,应用程序维护自己的 Cache 做更加细粒度的控制,比如 MySQL 就是这样做
的,你可以参考MySQL Buffer Pool 实现自己的 Cache 成本还是挺高的,不如内核的 Page Cache 来得简单高效
第二种,直接使用 Direct I/O(直接读写) 来绕过 Page Cache,不使用 Cache 了
下面举例为什么需要PageCache
标准 I/O 和内存映射会先把数据写入到 PageCache,这样做会通过减少 I/O 次数来提升读写效率。我们看一个具体的例子。首先,我们来生成一个 1G 大小的新文件,然后把 Page Cache 清空,确保文件内容不在内存中,
以此来比较第一次读文件和第二次读文件耗时的差异。具体的流程如下
先成一个 1G 的文件:
ddif = /dev/zeroof = /home/yafang/test/dd.outbs = 4096count =((1024*256))
其次,清空 Page Cache,需要先执行一下 sync 来将脏页(第二节课,我会解释一下什么是脏页)同步到磁盘再去 drop cache
$ sync && echo 3 > /proc/sys/vm/drop_caches
第一次读取文件的耗时如下:
$ time cat /home/yafang/test/dd.out &> /dev/null
real 0m5.733s
user 0m0.003s
sys 0m0.213s
再次读取文件的耗时如下:
$ time cat /home/yafang/test/dd.out &> /dev/null
real 0m0.132s
user 0m0.001s
sys 0m0.130s
通过这样详细的过程你可以看到,第二次读取文件的耗时远小于第一次的耗时,这是因为第一次是从磁盘来读取的内容,磁盘 I/O 是比较耗时的,而第二次读取的时候由于文件内 容已经在第一次读取时被读到内存了,所以是直接从内存读取的数据,内存相比磁盘速度是快很多的。这就是 Page Cache 存在的意义:减少 I/O,提升应用的 I/O 速度。
PageCahce 不足的地方是 它对应用程序太过于透明,以至于应用程序很难有好方法来控制它
PageCache的产生和释放
PageCache的产生
Page Cache 的产生有两种不同的方式:
Buffered I/O(标准 I/O);
Memory-Mapped I/O(存储映射 I/O):
这两种方式分别都是如何产生 Page Cache 的呢?来看下面这张图:
'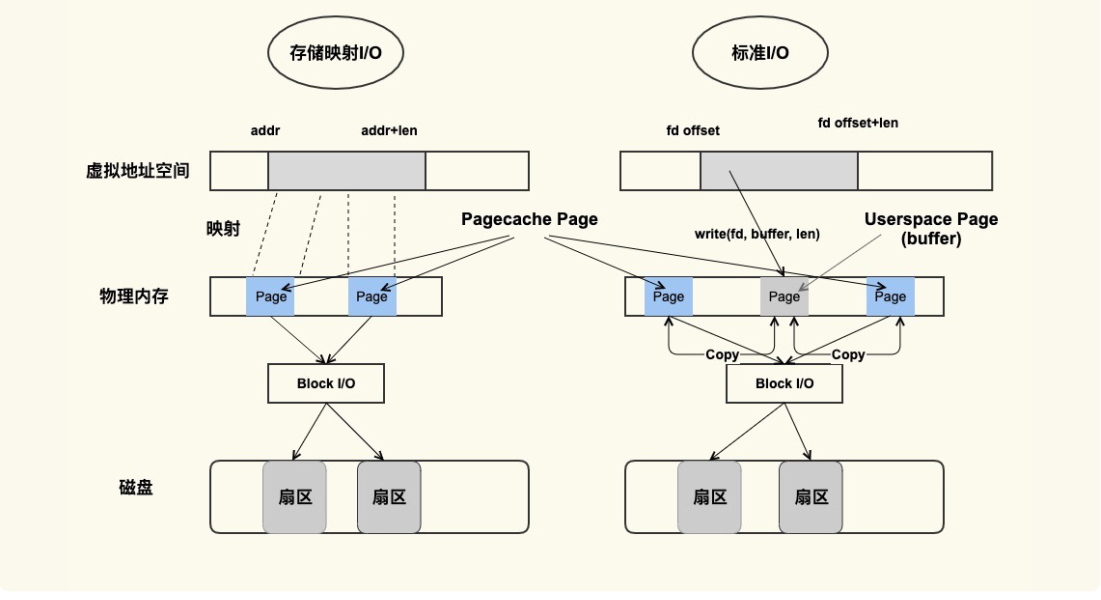
PageCache产生示意图
虽然二者都能产生 Page Cache,但是二者的还是有些差异的:
**标准 I/O **是写的 (write(2)) 用户缓冲区 (Userpace Page 对应的内存),然后再将用户缓冲区里的数据拷贝到内核缓冲区 (Pagecache Page 对应的内存);
如果是读的 (read(2)) 话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据,也就是 buffer 和文件内容
不存在任何映射关系。
对于**存储映射 I/O **而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容
存储映射 I/O 要比标准 I/O 效率高一些,毕竟少了“用户空间到内核空间互相拷贝”的过程。这也是很多应用开发者发现,为什么使用内存映射 I/O 比标准 I/O 方式性能要好一些的主要原因。
脚本演示标准 I/O 产生PageCache的过程。
#!/bin/sh
#这是我们用来解析的文件
MEM_FILE="/proc/meminfo"
#这是在该脚本中将要生成的一个新文件
NEW_FILE="/home/yafang/dd.write.out"
#我们用来解析的Page Cache的具体项
active=0
inactive=0
pagecache=0
IFS=' '
#从/proc/meminfo中读取File Page Cache的大小
function get_filecache_size()
{
items=0
while read line
do
if [[ "$line" =~ "Active:" ]]; then
read -ra ADDR <<<"$line"
active=${ADDR[1]}
let "items=$items+1"
elif [[ "$line" =~ "Inactive:" ]]; then
read -ra ADDR <<<"$line"
inactive=${ADDR[1]}
let "items=$items+1"
fi
if [ $items -eq 2 ]; then
break;
fi
done < $MEM_FILE
} #
读取File Page Cache的初始大小
get_filecache_size
let filecache="$active + $inactive"
#写一个新文件,该文件的大小为1048576 KB
dd if=/dev/zero of=$NEW_FILE bs=1024 count=1048576 &> /dev/null
#文件写完后,再次读取File Page Cache的大小
get_filecache_size
#两次的差异可以近似为该新文件内容对应的File Page Cache
#之所以用近似是因为在运行的过程中也可能会有其他Page Cache产生
let size_increased="$active + $inactive - $filecache"
#输出结果
echo "File size 1048576KB, File Cache increased" $size inc
运行该脚本前你要确保系统中有足够多的 free 内存(避免内存紧张产生回收行为),最终的测试结果是这样的:
File size 1048576KB, File Cache increased 1048648KB
在创建一个文件的过程中,代码中 /proc/meminfo 里的Active(file)活动文件 和 Inactive(file) 非活动文件 这两项会随着文件内容的增加而增加,它们增加的大小跟文件大小是一致的 如果你观察得很仔细的话,你会发现增加的 Page Cache 是 Inactive(File) 这一项
用一张图简单描述下这个过程
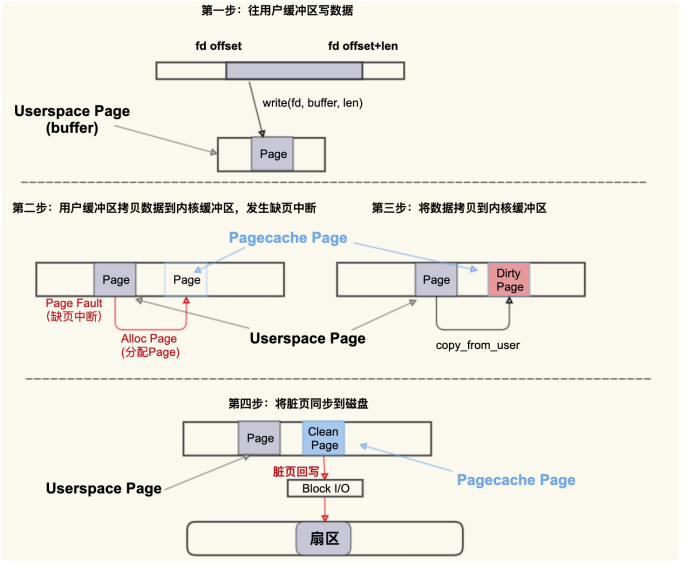
首先往用户缓冲区 buffer(这是 Userspace Page) 写入数据,然后 buffer 中的数据拷贝到内核缓冲区(这是 Pagecache Page),如果内核缓冲区中还没有这个 Page,就会发生 Page Fault(缺页异常) 会去分配一个 Page,拷贝结束后该 Pagecache Page 是一个 Dirty Page(脏页),然后该 Dirty Page 中的内容会同步到磁盘,同步到磁盘后,该 Pagecache Page 变为 Clean Page 并且继续存在系统中。
可以将Alloc Page 理解为 Page Cache 的“诞生”,
将 Dirty Page 理解为Page Cache 的婴幼儿时期(最容易生病的时期),
将 Clean Page 理解为 Page Cache的成年时期(在这个时期就很少会生病了)。
但是请注意,并不是所有人都有童年的, 如果是读文件产生的 Page Cache,它的内容跟磁盘内容是一致的,所以它一开
始是 Clean Page 成年时期 除非改写了里面的内容才会变成 Dirty Page(返老还童)
为了提前发现或者预防婴幼儿
时期的 Page Cache 发病,我们也需要一些手段来观测它:
$ cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 40
nr_writeback 2
如上所示,nr_dirty 表示当前系统中积压了多少脏页,
nr_writeback 则表示有多少脏页正 在回写到磁盘中,他们两个的单位都是 Page(4KB)
通常情况下,小朋友们(Dirty Pages)聚集在一起(脏页积压)不会有什么问题 特殊情况下Dirty
Pages 如果积压得过多,在某些情况下也会容易引发问题 后面章节介绍
PageCache的释放
你可以把 Page Cache 的回收行为 (Page Reclaim) 理解为 Page Cache 的“自然死
亡”。
我们知道,服务器运行久了后,系统中 free 的内存会越来越少,用 free 命令来查看,**大部分都会是 used 内存或者 buff/cache 内存 **
$ free -g
total used free shared buff/cache available
Mem: 125 41 6 0 79 82
Swap: 0 0 0
free 命令中的 buff/cache 中的这些就是“活着”的 Page Cache, 那它们什么时候会“死
亡”(被回收)呢?我们来看一张图:
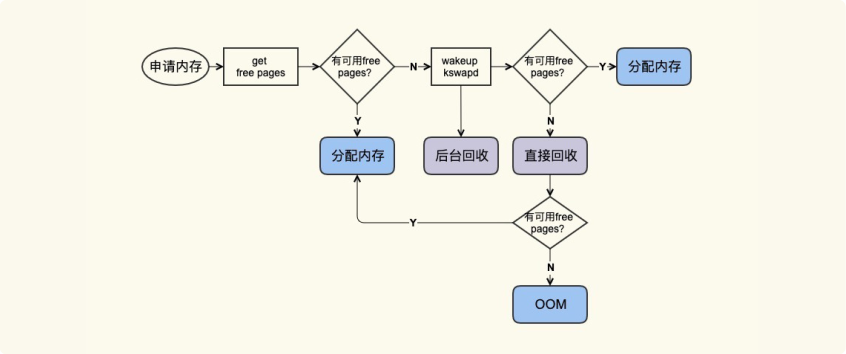
应用在申请内存的时候,即使没有 free 内存,只要还有足够可回收的 PageCache,就可以通过回收 Page Cache 的方式来申请到内存,回收的方式主要是两种:直接回收和后台回收。
观察 Page Cache 直接回收
和后台回收最简单方便的方式是使用 sar:
$ sar -B 1
02:14:01 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscan
02:14:01 PM 0.14 841.53 106745.40 0.00 41936.13 0.00 0
02:15:01 PM 5.84 840.97 86713.56 0.00 43612.15 717.81 0
02:16:01 PM 95.02 816.53 100707.84 0.13 46525.81 3557.90 0
02:17:01 PM 10.56 901.38 122726.31 0.27 54936.13 8791.40 0
02:18:01 PM 108.14 306.69 96519.75 1.15 67410.50 14315.98 31
02:19:01 PM 5.97 489.67 88026.03 0.18 48526.07 1061.53 0
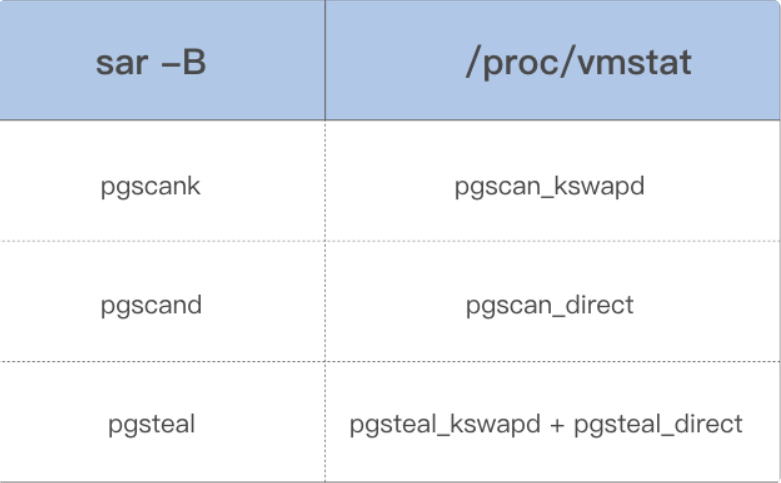
借助上面这些指标,你可以更加明确地观察内存回收行为,下面是这些指标的具体含义:
pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
pgscand/s: Application 在内存申请过程中每秒直接扫描的 page 个数。
pgsteal/s: 扫描的 page 中每秒被回收的个数。
%vmeff: pgsteal/(pgscank+pgscand), 回收效率,越接近 100 说明系统越安全,越接近 0 说明系统内存压力越大
这几个指标也是通过解析 /proc/vmstat 里面的数据来得出的,对应关系如下:
Linus 对 Linux Kernel 设计的第一原则是“never break the user space”。
Page Cache 是在应用程序读写文件的过程中产生的,所以在读写文件之前你需要留意
是否还有足够的内存来分配 Page Cache;
Page Cache 中的脏页很容易引起问题,你要重点注意这一块;
在系统可用内存不足的时候就会回收 Page Cache 来释放出来内存,
我建议你可以通过sar 或者 /proc/vmstat 来观察这个行为从而更好的判断问题是否跟回收有关
Page Cache难以回收产生的load(负载)飙高
系统很卡顿,敲命令响应非常慢;应用程序的 RT 变得很高,或者抖动得很厉害。在发生这些问题时,很有可能也伴随着
系统 load 飙得很高。
导致飙高的原因一般是下面三种:
直接内存回收引起的 load 飙高;
系统中脏页积压过多引起的 load 飙高;
系统 NUMA 策略(内存配置策略)配置不当引起的 load 飙高。
直接内存回收引起 load 飙高或者业务时延抖动
直接内存回收是指在进程上下文同步进行内存回收 因为直接内存回收是在进程申请内存的过程中同步进行的回收,而这个回收过程可能会消耗很多时间,进而导致进程的后续行为都被迫等待,这样就会造成很长时间的延迟,以及
系统的 CPU 利用率会升高,最终引起 load 飙高。
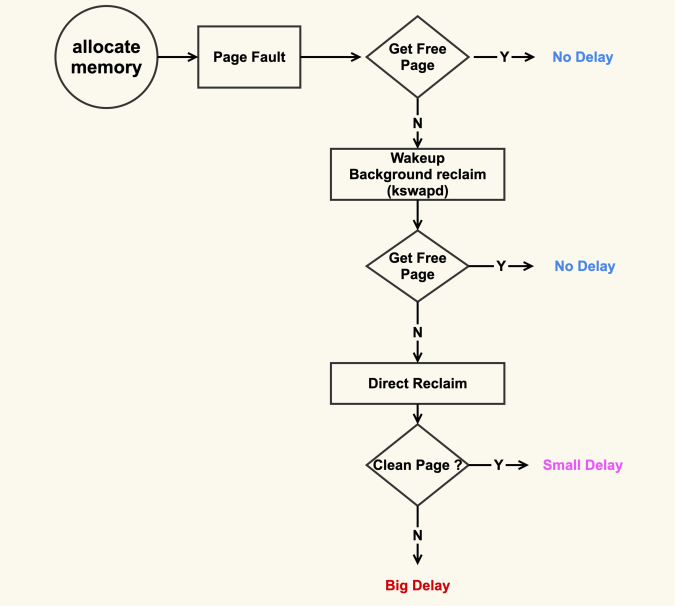
内存回收过程图
在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进行内存申请的速度,就会开始同步阻塞回收,导致延迟(上图中红色和粉色标记的地方,这就是引起 load 高的地址)
针对直接内存回收引起 load 飙高或者业务 RT 抖动的问题,一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收
原理图
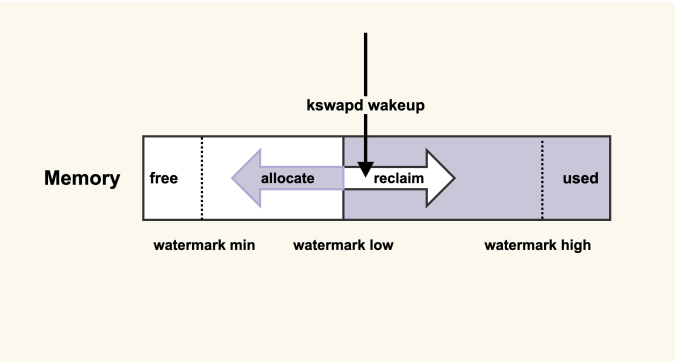
当内存水位低于 watermark low 时,就会唤醒 kswapd 进行后台回收,然后 kswapd 会一直回收到 watermark high
我们可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,该选项最终控制的是内存回收水位,不过,内存回收水位是内核里面非常细节性的知识点我们可以先不去讨论。
vim /etc/sysctl.conf
vm.min_free_kbytes = 4194304
vm.min_free_kbytes = 4194304
对于大于等于 128G 的系统而言,将 min_free_kbytes 设置为 4G 比较合理,这是我们在处理很多这种问题时总结出来的一个经验值,既不造成较多的内存浪费,又能避免掉绝大多数的直接内存回收。
该值的设置和总的物理内存并没有一个严格对应的关系
你可以渐进式地增大该值,比如先调整为 1G,观察 sar -B 中 pgscand 是否还有不为 0 的情况;如果存在不为 0 的情
况,继续增加到 2G,再次观察是否还有不为 0 的情况来决定是否增大,以此类推
在这里你需要注意的是,即使将该值增加得很大,还是可能存在 pgscand 不为 0 的情况 那么这个时候你要考虑的是,业务是否可以容忍,如果可以容忍那就没有 必要继续增加了,也就是说,**增大该值并不是完全避免直接内存回收,而是尽量将直接内存回收行为控制在业务可以容忍的范围内 **
这个方法可以用在 3.10.0 以后的内核上
然了,这样做也有一些缺陷:提高了内存水位后,应用程序可以直接使用的内存量就会
减少,这在一定程度上浪费了内存。
**应用程序更加关注什么,如果关注延迟那就适当地增大该值,如果关注内存的使用量那就适当地调小该值。 **
通过调整内存水位,在一定程度上保障了应用的内存申请,但是同时也带来了一定的内存浪费,因为系统始终要保障有这么多的 free 内存,这就压缩了 Page Cache 的空间。调整的效果你可以通过 /proc/zoneinfo 来观察:
$ egrep "min|low|high" /proc/zoneinfo
...
min 7019
low 8773
high 10527
其中 min、low、high 分别对应上图中的三个内存水位。你可以观察一下调整前后 min、low、high 的变化。需要提醒你的是,内存水位是针对每个内存 zone 进行设置的,所以/proc/zoneinfo 里面会有很多 zone 以及它们的内存水位,你可以不用去关注这些细节。
系统中脏页过多引起 load 飙高
直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于D 状态的进程数增多,最终的表现就是系统的 load 值很高
(D: 不接受任何异步信号的休眠状态。通常是在处理一些不可中断的任务)
脏页引起系统 load 值飙高的问题场景图
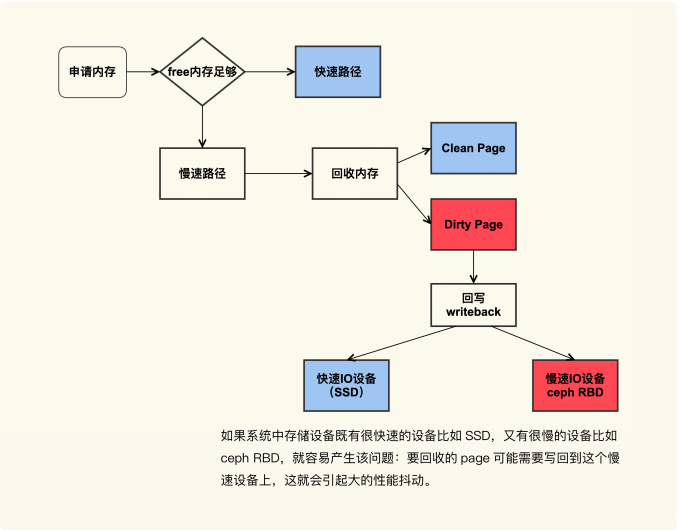
系统中既有快速 I/O 设备,又有慢速 I/O 设备(比如图中的 ceph RBD 设备,或者其他慢速存储设备比如 HDD),直接内存回收过程中遇到了正在往慢速 I/O 设备回写的 page,就可能导致非常大的延迟
解决方案是控制好系统中积压的脏页数据。很多人知道需要控制脏页,但是往往并不清楚如何来控制好这个度,脏页控制的少了可能会影响系统整体的效率,脏页控制的多了还是会触发问题,所以我们接下来看下如何来衡量好
这个“度”
脏页注解:
不能直接修改硬盘上的数据,而是先将数据从硬盘读入到内存的data cache,然后在内存中修改(被修改过的页称为脏数据页),最后再从内存回写到硬盘。下述进程都可能将脏页回写到硬盘
首先你可以通过 sar -r 来观察系统中的脏页个数:
$ sar -r 1
07:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %com
09:20:01 PM 5681588 2137312 27.34 0 1807432 193016 2
09:30:01 PM 5677564 2141336 27.39 0 1807500 204084 2
09:40:01 PM 5679516 2139384 27.36 0 1807508 196696 2
09:50:01 PM 5679548 2139352 27.36 0 1807516 196624 2
kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以
通过调小如下设置来将系统脏页个数控制在一个合理范围:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
调整这些配置项有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了 I/O 的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了I/O 的次数,降低了 I/O 的效率
至于这些值调整大多少比较合适,也是因系统和业务的不同而异,我的建议也是一边调整一边观察,将这些值调整到业务可以容忍的程度就可以了,即在调整后需要观察业务的服务质量 (SLA),要确保 SLA 在可接受范围内。调整的效果你可以通过 /proc/vmstat 来查看:
$ grep "nr_dirty_" /proc/vmstat
nr_dirty_threshold 366998
nr_dirty_background_threshold 183275
系统 NUMA 策略配置不当引起的 load 飙高
系统中还有一半左右的 free 内存,但还是频频触发 direct reclaim,导致业务抖动得比较厉害。后来经过排查发现是由于设置了zone_reclaim_mode,这是 NUMA 策略的一种
置 zone_reclaim_mode 的目的是为了增加业务的 NUMA 亲和性,但是在实际生产环境中很少会有对 NUMA 特别敏感的业务,这也是为什么内核将该配置从默认配置 1 修改为了默认配置 0
配置为 0 之后,就避免了在其他 node 有空闲内存时,不去使用这些空闲内存而是去回收当前 node 的 Page
Cache
我们可以通过 numactl 来查看服务器的 NUMA 信息,如下是两个 node 的服务器:
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 130950 MB
node 0 free: 108256 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45
node 1 size: 131072 MB
node 1 free: 122995 MB
node distances:
node 0 1
0: 10 21
1: 21 10
其中 CPU0~11,24~35 的 local node 为 node 0;而 CPU12~23,36~47 的 local node 为 node 1
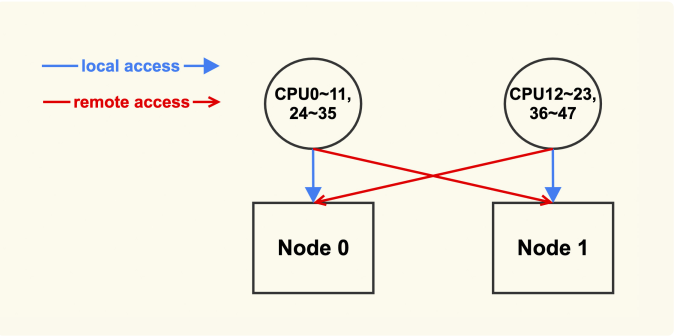
推荐将 zone_reclaim_mode 配置为 0。
$ echo 0 > /proc/sys/vm/zone_reclaim_mode
vm.zone_reclaim_mode = 0
相比内存回收的危害而言,NUMA 带来的性能提升几乎可以忽略,所以配置为 0,利远大于弊。
**直接内存回收引起 load飙高时,就去调整内存水位设置;脏页积压引起 load 飙高时,就需要去调整脏页的水位;
NUMA 策略配置不当引起 load 飙高时,就去检查是否需要关闭该策略。同时我们在做这
些调整的时候,一定要边调整边观察业务的服务质量,确保 SLA 是可以接受的。 **
Page Cache 太容易回收而引起的问题
这类问题做个总结,大致可以分为两方面:
误操作而导致 Page Cache 被回收掉,进而导致业务性能下降明显;
内核的一些机制导致业务 Page Cache 被回收,从而引起性能下降。
对 Page Cache 操作不当产生的业务性能下降
对于 Page Cache 而言,是可以通过 drop_cache 来清掉的(echo 3 > /proc/sys/vm/drop_caches) 但是这样做是会有一些负面影响的,比如说这些 Page Cache 被清理掉后可能会引起系统性能下降
其实这和 inode 有关,inode 是内存中对磁盘文件的索引,进程在查找或者读取文件时就是通过 inode 来进行操作的
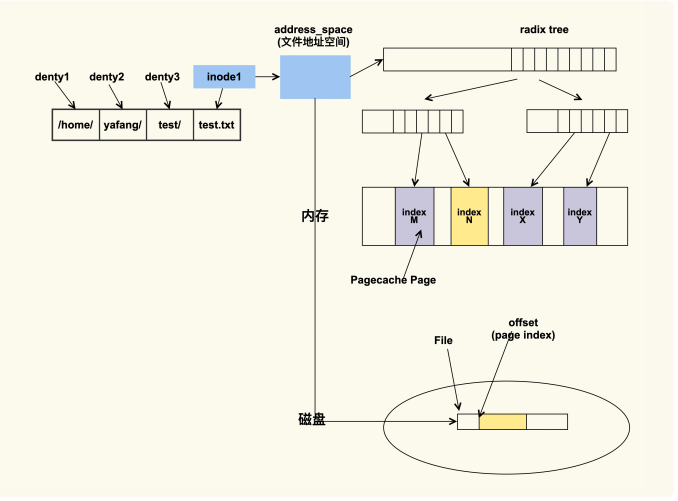
进程会通过 inode 来找到文件的地址空间(address_space),然后结合文件偏移(会转换成 page index)来找具体的 Page。如果该 Page 存在,那就说明文件内容已经被读取到了内存;如果该 Page 不存在那就说明不在内存中,需要到磁盘中去读取。
drop_cache 来释放 inode 的话,应该会清楚它有几个控制选项,我们可以通过写入不同的数值来释放不同类型的 cache(用户数据 Page Cache,内核数据 Slab,或者二者都释放
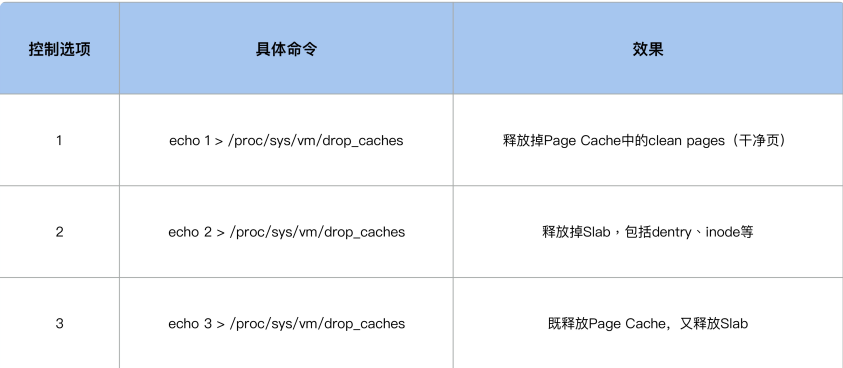
当我们执行 echo 2 来 drop slab 的时候,它也会把 Page Cache 给 drop 掉
由于 drop_caches 是一种内存事件,内核会在 /proc/vmstat 中来记录这一事件,所以我
们可以通过 /proc/vmstat 来判断是否有执行过 drop_caches
$ grep drop /proc/vmstat
drop_pagecache 3
drop_slab 2
如上所示,它们分别意味着 pagecache 被 drop 了 3 次(通过 echo 1 或者 echo 3),slab 被 drop 了 2 次(通过 echo 2 或者 echo 3)。如果这两个值在问题发生前后没有变化,那就可以排除是有人执行了 drop_caches;否则可以认为是因为 drop_caches 引起的Page Cache 被回收。
内核机制引起 Page Cache 被回收而产生的业务性能下降
在内存紧张的时候会触发内存回收,内存回收会尝试去回收reclaimable(可以被回收的)内存,这部分内存既包含 Page Cache 又包含 reclaimable kernel memory(比如 slab)。我们可以用下图来简单描述这个过程:
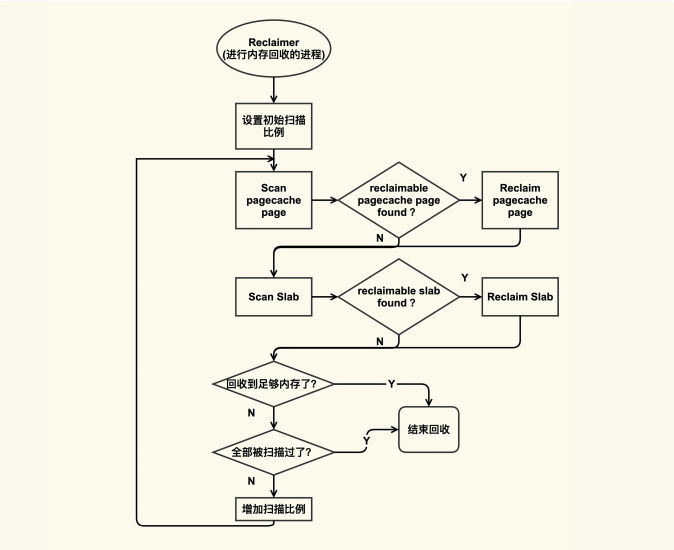
Reclaimer 是指回收者,它可以是内核线程(包括 kswapd)也可以是用户线程。回收的时候,它会依次来扫描 pagecache page 和 slab page 中有哪些可以被回收的,如果有的话就会尝试去回收,如果没有的话就跳过。
inode 被回收的话,那么它对应的 Page Cache 也都会被回收掉,所以如果业务进程读取的文件对应的 inode 被回收了,那么该文件所有的 Page Cache 都会被释放掉,这也是容易引起性能问题的地方
可以通过 /proc/vmstat 来观察
$ grep inodesteal /proc/vmstat
pginodesteal 114341
kswapd_inodesteal 1291853
这个行为对应的事件是 inodesteal,就是上面这两个事件,
其中 kswapd_inodesteal 是指在 kswapd 回收的过程中,因为回收 inode 而释放的 pagecache page 个数;
pginodesteal 是指 kswapd 之外其他线程在回收过程中,因为回收 inode 而释放的pagecache page 个数。
所以在你发现业务的 Page Cache 被释放掉后,你可以通过观察来发现是否因为该事件导致的
如何避免 Page Cache 被回收而引起的性能问题
从应用代码层面来优化;
从系统层面来调整
代码层优化
从应用程序代码层面来解决是相对比较彻底的方案,因为应用更清楚哪些 Page Cache 是重要的,哪些是不重要的,所以就可以明确地来对读写文件过程中产生的 Page Cache 区别对待。
比如说,对于重要的数据,可以通过 mlock(2) 来保护它,防止被回收以及被drop;对于不重要的数据(比如日志),那可以**通过 madvise(2) **告诉内核来立即释放这些 Page Cache。
mlock(2) 来保护重要数据防止被回收或者被 drop 的例子
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#define FILE_NAME "/home/yafang/test/mmap/data"
#define SIZE (1024*1000*1000)
int main()
{
int fd;
char *p;
int ret;
fd = open(FILE_NAME, O_CREAT|O_RDWR, S_IRUSR|S_IWUSR);
if (fd < 0)
return -1;
/* Set size of this file */
ret = ftruncate(fd, SIZE);
if (ret < 0)
return -1;
/* The current offset is 0, so we don't need to reset the offset. */
/* lseek(fd, 0, SEEK_CUR); */
/* Mmap virtual memory */
p = mmap(0, SIZE, PROT_READ|PROT_WRITE, MAP_FILE|MAP_SHARED, fd, 0);
if (!p)
return -1;
/* Alloc physical memory */
memset(p, 1, SIZE);
/* Lock these memory to prevent from being reclaimed */
mlock(p, SIZE);
/* Wait until we kill it specifically */
while (1) {
sleep(10);
} /
**
Unmap the memory.
* Actually the kernel will unmap it automatically after the
* process exits, whatever we call munamp() specifically or not.
*/
munmap(p, SIZE);
return 0;
}
通过 mlock(2) 来锁住了读 FILE_NAME 这个文件内容对应的 PageCache。在运行上述程序之后,我们来看下该如何来观察这种行为:确认这些 Page Cache是否被保护住了,被保护了多大。这同样可以通过 /proc/meminfo 来观察:
$ egrep "Unevictable|Mlocked" /proc/meminfo
Unevictable: 1000000 kB
Mlocked: 1000000 kB
系统层优化
修改源码是件比较麻烦的事,如果可以不修改源码来达到目的那就最好不过了。Linux 内核同样实现了这种不改应用程序的源码而从系统层面调整来保护重要数据的机制,这个机制就是 memory cgroup protection
它大致的思路是,将需要保护的应用程序使用 memory cgroup 来保护起来,这样该应用程序读写文件过程中所产生的 Page Cache 就会被保护起来不被回收或者最后被回收。memory cgroup protection 大致的原理如下图所示:
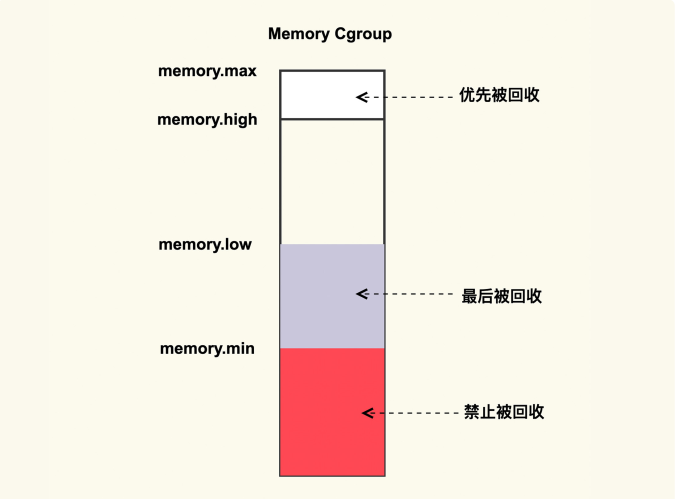
memory cgroup 提供了几个内存水位控制线 memory.{min, low, high,max} 。
memory.max
这是指 memory cgroup 内的进程最多能够分配的内存,如果不设置的话,就默认不做内存大小的限制
memory.high
如果设置了这一项,当 memory cgroup 内进程的内存使用量超过了该值后就会立即被
回收掉,所以这一项的目的是为了尽快的回收掉不活跃的 Page Cache
memory.low
这一项是用来保护重要数据的,当 memory cgroup 内进程的内存使用量低于了该值后,在内存紧张触发回收后就会先去回收不属于该 memory cgroup 的 Page Cache,等到其他的 Page Cache 都被回收掉后再来回收这些 Page Cache。
memory.min
这一项同样是用来保护重要数据的,只不过与 memoy.low 有所不同的是,当 memorycgroup 内进程的内存使用量低于该值后,即使其他不在该 memory cgroup 内的Page Cache 都被回收完了也不会去回收这些 Page Cache,可以理解为这是用来保护最高优先级的数据的。
如果你想要保护你的 Page Cache 不被回收,你就可以考虑将你的业务进程放在一个 memory cgroup 中,然后设置 memory.{min,low} 来进行保护;与之相反,如果你想要尽快释放你的 Page Cache,那你可以考虑设置 memory.high 来及时的释放掉不活跃的 Page Cache。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号