12-布隆过滤器+布谷鸟过滤器+分布式锁
布隆过过滤器
用于解决 缓存穿透问题
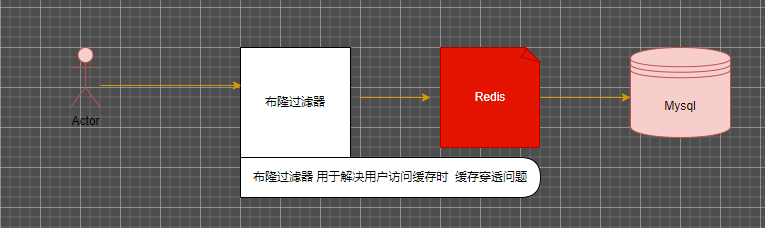
布隆过滤器 本质就是二进制 01组成的二进制数组,工作原理也很简单 就是判断用户访问的数据是否存在于缓存中,
布隆过滤器工作原理
前置知识 哈希函数:
通过同一个哈希函数 得到的哈希值不相同 那么两个哈希值原始输入的值肯定是不同的。
通过同一个哈希函数,得到的哈希值相同, 两个哈希值的原始值有可能相同 有可能不同。
总结下来也就是 哈希值不同 原来的值肯定不同 哈希值相同 原来的值有可能相同 有可能不同。
布隆过滤器为什么要哈希函数存储那?
哈希函数最后存入到布隆过滤器中就是 0和1 存在数组就是1 不存在就是0 这比存原始数据大大减少了内存的占用
- 数据插入过程
数据存入过程
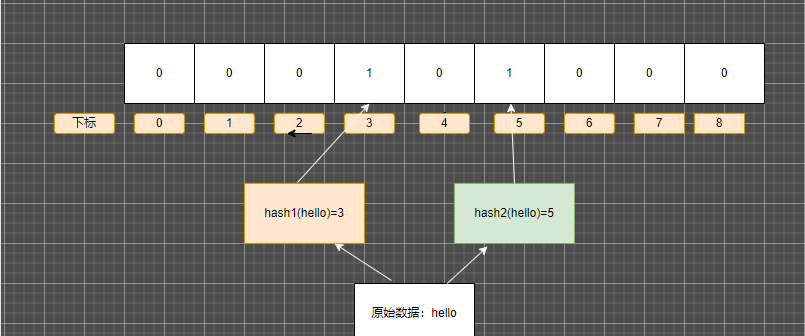
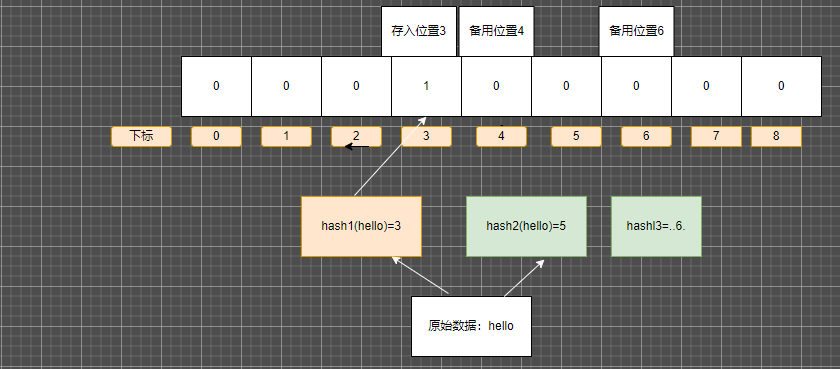
以上图为例
原始数据hello 经过两个hash函数 计算出两个位置 3 和5
在二进制数组中就把 3和5的位置改为1 其它为0
000101000 就是hello在布隆过滤器中的位置
读取过程与存入过程相似,通过hash计算读取值的hash函数 判断是否存在 存在就去缓存中读取数据
删除操作很难操作

一个下标存了两个数据 没法删除 哈希值相同
布隆过滤器的优缺
优点
-
插入查询速度非常快
-
查询快 只需要判断0 1
-
安全性好 过滤器中没有存在原始数据 即使泄露了 一堆0 1 也不代表任何内容
缺点
-
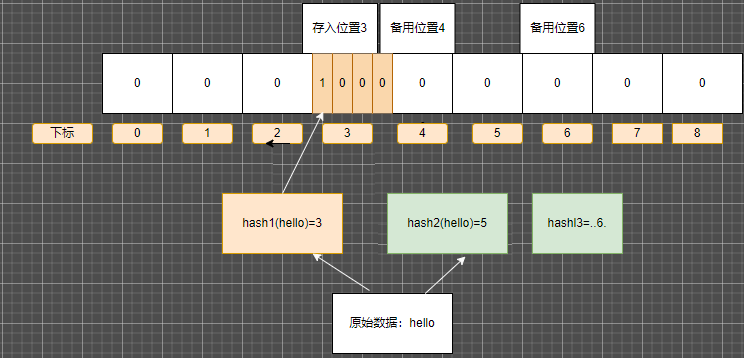
存在误判 这和使用了hash函数有关 请看下图
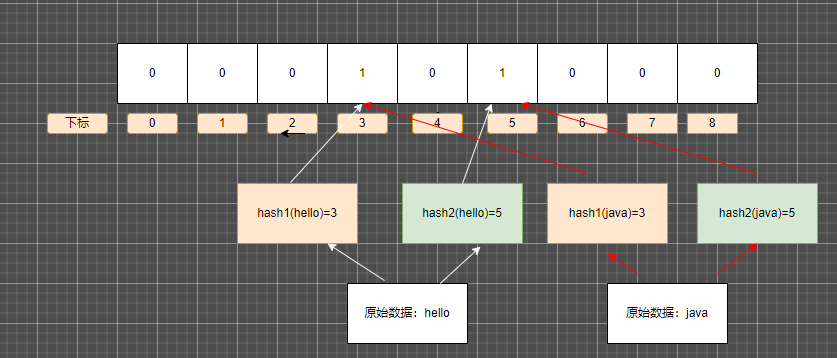
hash函数 如果两个hash的值相同 那么两个值可能相同 也可能不相同, 那么就存在上图的情况,两个完全不同的值hash函数相同 如果我们存入的是hello 用户查询java 而我们的缓存中没有java 但是布隆过滤器反馈的结果是java存在 这样过滤器就失效了
-
无法删除元素 也是由于上面hash函数的原因 同一个或多个hash函数的值 可以存多个原始的值 像上面 000101000 既存了hello的 也存了 java 那么就无法进行删除操作
如何解决布隆过滤器的缺点那?
有一个办法 一个是增加 hash函数的个数
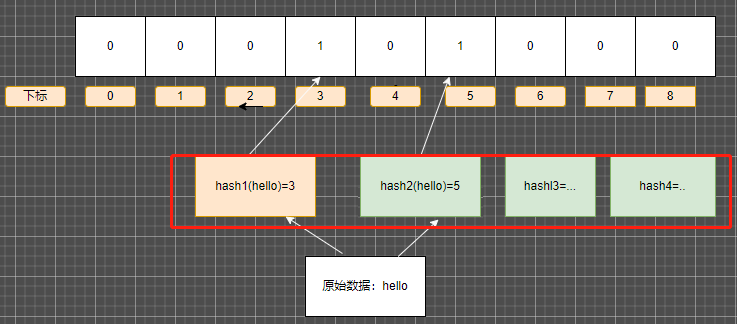
每个原始数据 在数组中由多个hash函数值表示 ,值越多 和其它值撞车的概率越小
布隆过滤器在使用的时候 有一个设置的值是误判率
误判率设置的越小 需要判断的哈希函数越多 占用的空间越大 执行的越慢,效率越差
当我们通过程序调用布隆过滤器的时候 可以设置误判率 误判率越高 则需要更大的空间和更多的哈希函数
所以误判率的要求 根据现实业务的需要 需要在性能和准确率上做一个均衡的选择
布谷鸟过滤器
布谷鸟过滤器的原理
布谷鸟过滤器的原则就是鸠占鹊巢
鸠 就是布谷鸟 自己从来不搭窝,下蛋产子的时候占用其它鸟的窝,其他鸟类帮它一起孵化 布谷鸟体型比较大 把其它小鸟挤走
布谷鸟哈希
布谷鸟哈希 会把个原始数据经过哈希计算出两个位置,如果两个位置是空的 就直接放到一个位置 ,有一个位置被占用了就去另外一个位置,如果两个位置都占满了,就把原来的数据踢走, 自己霸占位置 同时为踢走的数据再选一个位置,因为每一个数据都有两个位置
经过布谷鸟哈希计算的值叫指纹数据 ,代表原始数据
布谷鸟过滤器的问题
挤兑循环问题 当数据太大太拥挤的时候 新的数据进来 就要把原来的数据踢走,而被踢走的数据寻找位置又要提走其它数据的位置,这样一直循环就形成了挤兑循环的问题
解决循环挤兑问题有两种方法
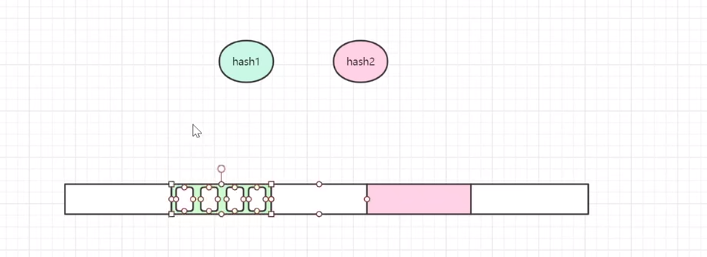
第一增加hash函数个数 一个值有3个hash值 也就有3个位置 存入值只占用1个位置 空余三个位置 。
第二种 一个位置 把这个位置做成数组 分成四小份 每一份放一个数据 相当于二维数组,数组内嵌套数组
同时四小分都是连续的 查询性能高 数组套娃 二维数组
布谷鸟过滤器的删除的问题
通常布谷鸟过滤器在资料里会显示 它实现了布隆过滤器不可以删除数据的功能,那在生产环境是否可以使用那
布谷鸟过滤器官方建议存入的数据不能超过kb+1 不能大于9
k=hash个数 b=座位个数,如果一个原始数据 有两个哈希函数 一个位置分为4个座位 2*4+1=9 存入相同的数据不能大于9

我们以两个哈希函数 1个哈希函数4个位置计算
举例如果连续存储相同的数据8次 八个位置都会占满 存入第九个数的时候 插入不进去了,因为存入第九个数据 前面八个算一个大的索引 后面你存到哪里 都会和这个索引冲突
同时会出现八个数据 指纹相同 位置相同 会造成误查询 和误删除。
如果需要删除一个数据 一个指纹数据是 1个字节 =256中可能,我们还需要单独计算每个数据的插入次数 ,所以布谷鸟实现的数据删除很鸡肋 不可能实现,删除之前的筛查就很费劲。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号