10-redis主从复制+哨兵模式
Redis主从复制原理
主从复制是只将堕胎redis服务器 一般是一主二从三台 作为一个集群
一台是master 主节点 另外的节点称为slave/follower 称为从节点
集群内 主节点有读写功能,以写为主 从节点只有只读功能,不能写入数据
从节点的数据是从主节点复制过来的
主从复制的优点
- 实现了数据冗余,主备复制上的数据是一样的 实现了热备功能
- 故障恢复 当主节点故障时,备节点可以提供恢复数据的功能
- 负载均衡,主备机群配合读写分离,可以大大提高服务器并发量,分担访问量负载
- 实现了服务的高可用,主从复制+哨兵模式 实现了redis集群的高可用
生产环境下的redis
- 一般不会使用单台 redis是内存数据库 内存数据断电即失,
- 从访问响应速度上来说 不论一个服务器真实物理内存有多大,当单台redis的使用内存量超过20G的时候,已经不适合单机使用了。
- 不论关系型数据库还是非关系型数库 往往都是“少写多读”的环境,一次写入 会不断读取数据,建议使用集群环境实现读写分离。
Redis主从复制
环境搭建
只配置从库 不配置主库
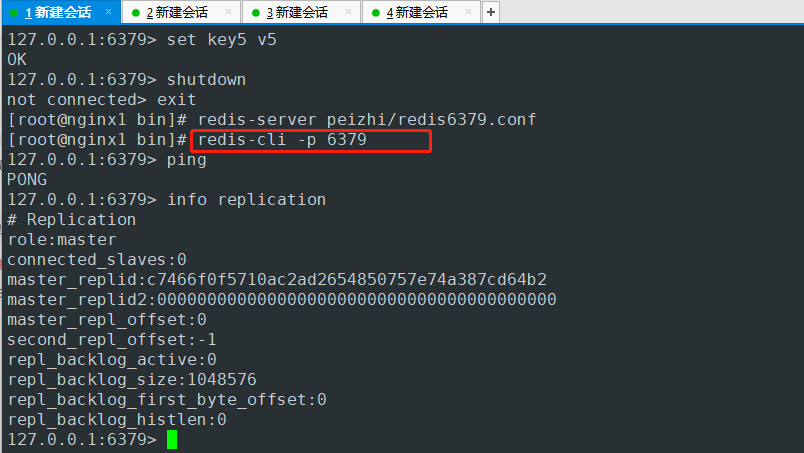
127.0.0.1:6379> info replication #查询当前库的信息
# Replication
role:master #角色 master
connected_slaves:0 #没有从机
master_replid:78bc4f2d4fb4f0985b99db4b5ad45bf32d35513b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
一台虚拟机上搭建redis主从复制
开启4个会话窗口

- 复制三份配置文件配置文件
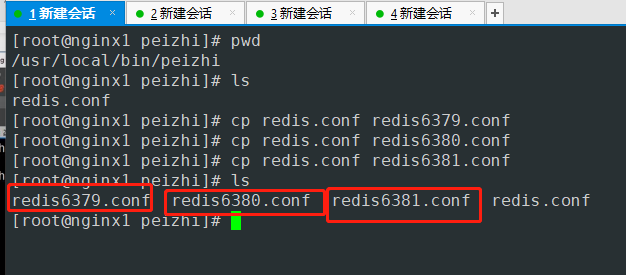
- 编辑redis6379.conf
port 6379
daemonize yes #后台启动打开
logfile "6379.log" #日志格式改一下 因为有多个服务
dbfilename dump6379.rdb #dump文件名字改成dump6379.rdb
- 编辑redis6380.conf
port 6380
daemonize yes
pidfile /var/run/redis_6380.pid #后台运行pid改完6380
logfile "6380.log"
dbfilename dump6380.rdb
- 编辑redis6381.conf
port 6381
daemonize yes
pidfile /var/run/redis_6381.pid
logfile "6381.log"
dbfilename dump6381.rdb
- 修改端口信息
- 修改后台启动
- 修改pid名称
- 修改log文件名称
- 修改rdb文件名称
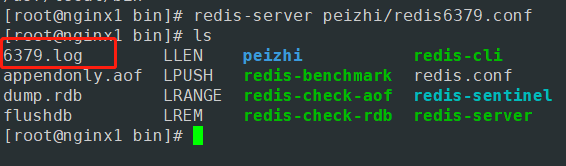
- 启动6379端口的redis服务
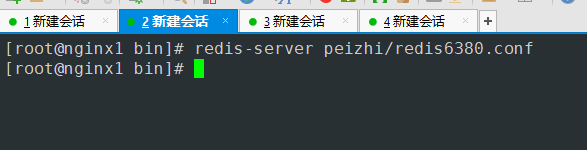
- 启动6380端口的redis服务
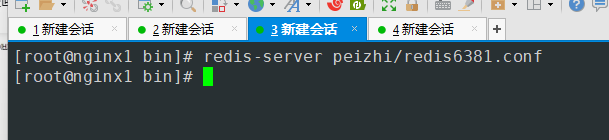
- 启动6381端口的redis服务
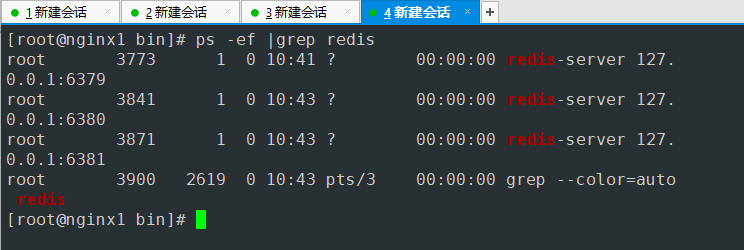
- 查询服务进程
3个端口都启动了
配置主从关系
上面配置完默认都是三台主节点 我们要配置一主二从
- 会话1 端口6379 主节点
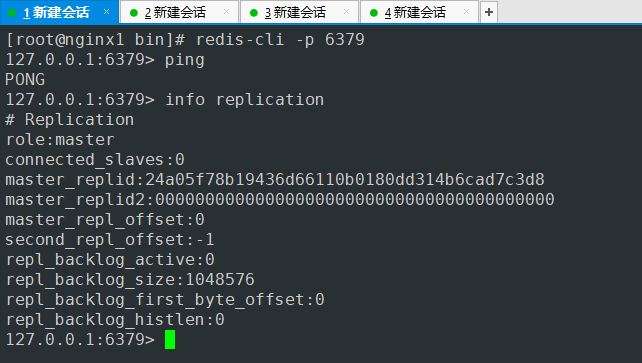
- 会话2 6380端口 主节点
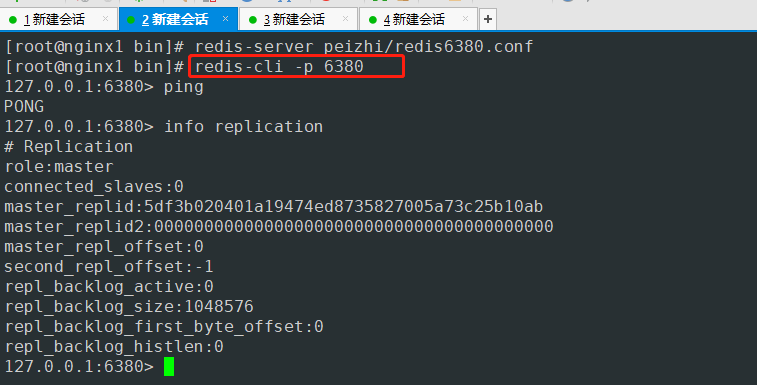
- 会话3 6381端口 主节点
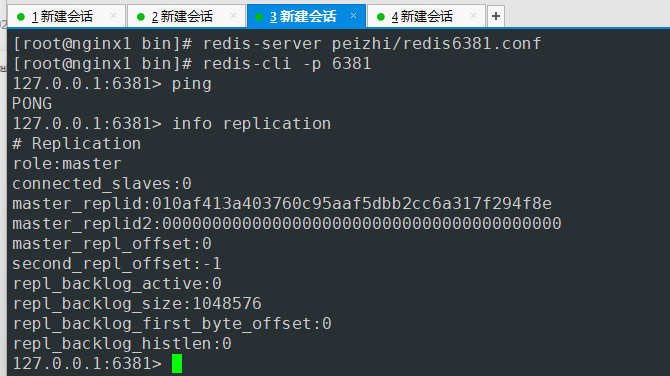
默认三台都是master
一般情况下只用配置从机就可以
一主(6379)二从(6380/6381)
- 会话2 6380端口
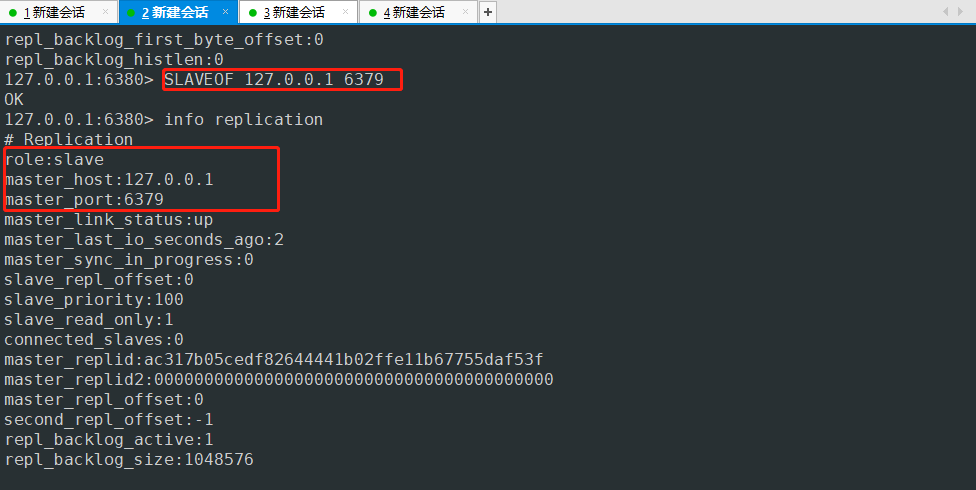
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 #配置主机的ip和端口
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 再次查询自己变成从机了
master_host:127.0.0.1 #主机的ip
master_port:6379 #主机的端口
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:0
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:ac317b05cedf82644441b02ffe11b67755daf53f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
- 会话1主机中去验证
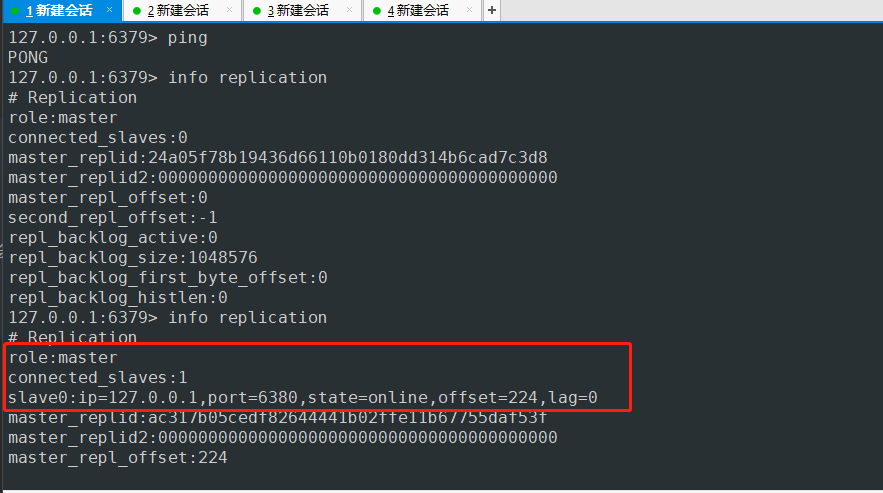
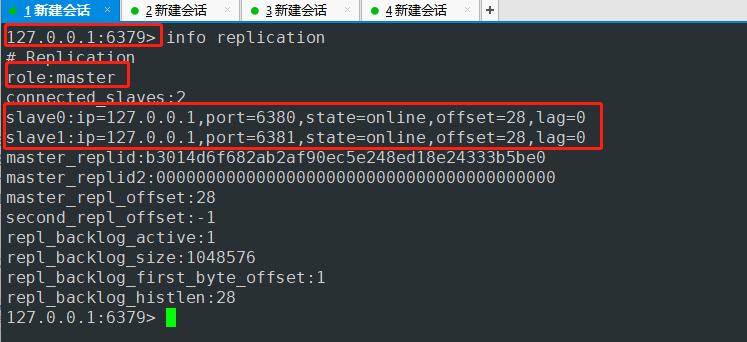
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=224,lag=0 #备机 ip端口 状态
master_replid:ac317b05cedf82644441b02ffe11b67755daf53f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
- 会话3 6381上设置自己为从节点
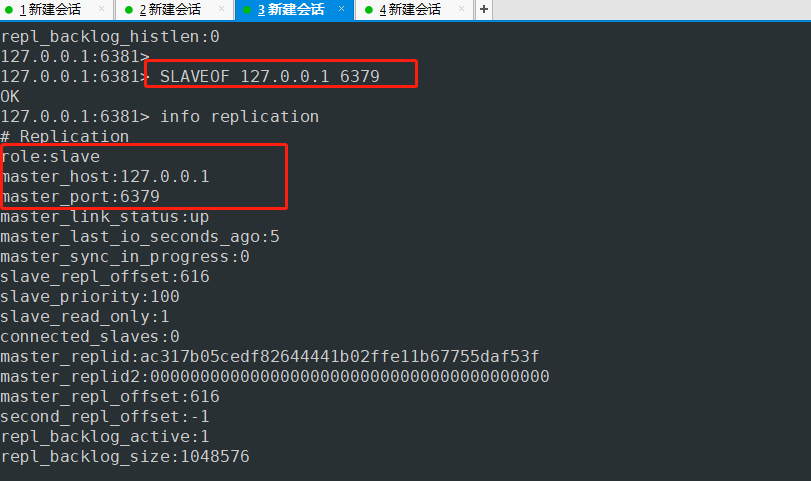
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 #设置主机为从节点 主节点的ip端口 127.0.0.1 6379
OK
127.0.0.1:6381> info replication
# Replication
role:slave #本机角色
master_host:127.0.0.1 #master ip
master_port:6379 #master port
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:616
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:ac317b05cedf82644441b02ffe11b67755daf53f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:616
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
- 去会话1 主机上去验证
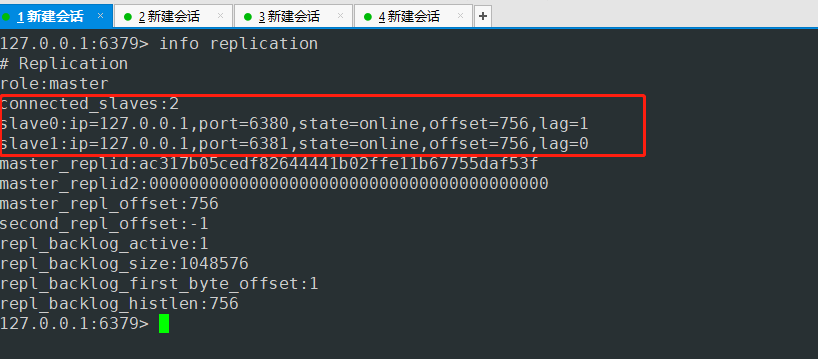
使用命令配置 是暂时的 永久配置需要在配置文件中配置!!!
- 永久配置 在配置文件中写入主的ip端口即可
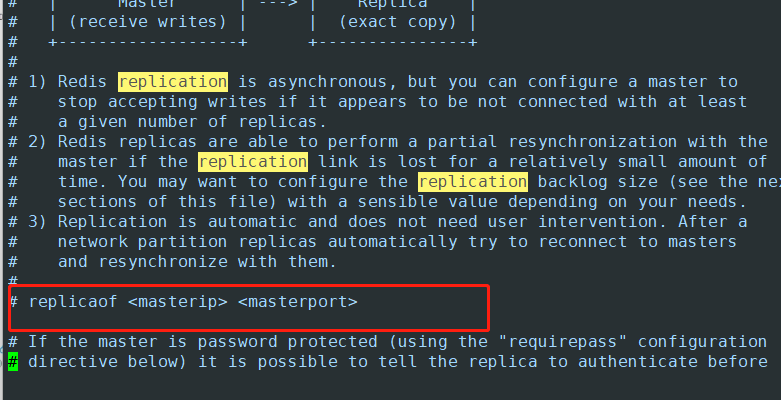
# 6380、6381都配置从属到6379
replicaof 127.0.0.1 6379
主机可以写 从机只能读
主机的数据从机都会自动保存


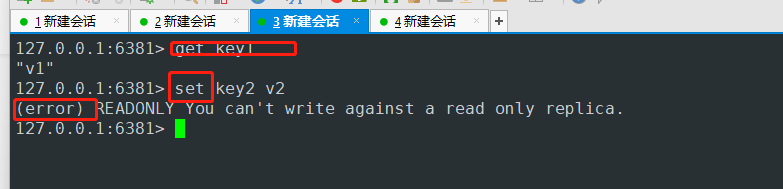
故障模拟
模拟主机down机后 从机可以用
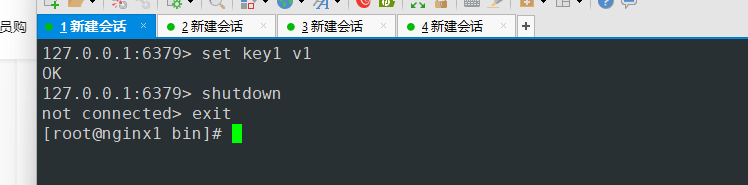
- 6379端口已经down机
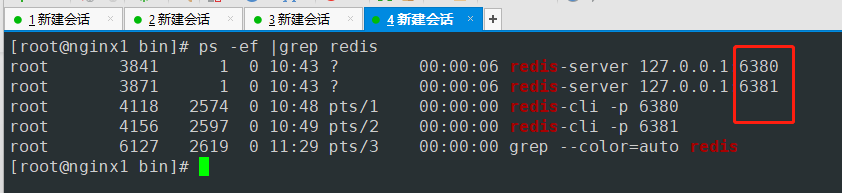
- 从机仍然可以获取信息

- 主节点启动后写入
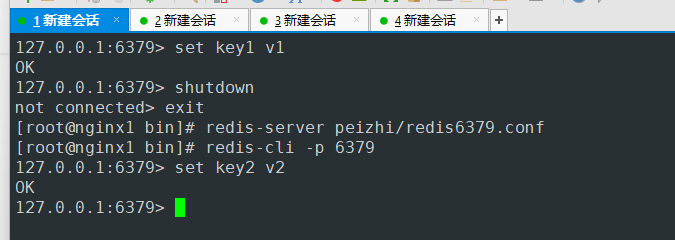
- 从节点可以查看到新写入的信息
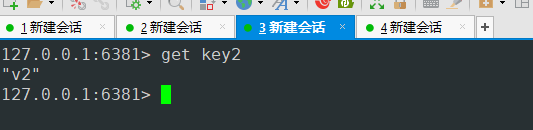
总结
主节点down机后 从节点依旧连接主节点 整个主从没有了写入操作 主节点恢复后写入的数据 会同步到从节点
模拟故障2
- 模拟6381从机down掉
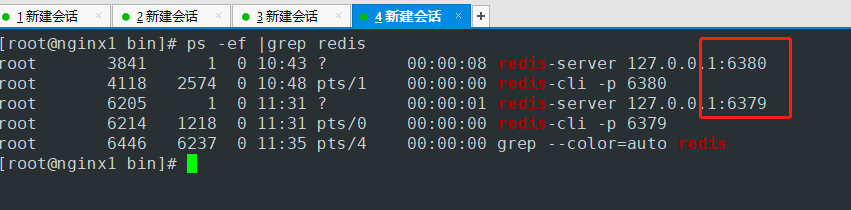
- 主节点写入值
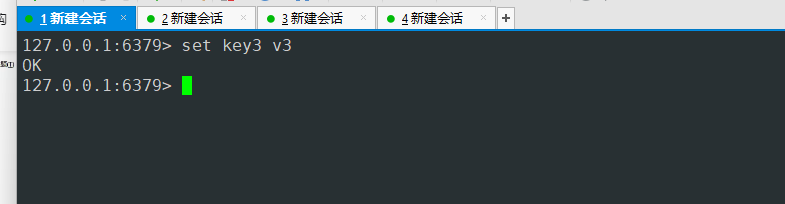
- 没有down掉的主机可以查到

- down掉的从机查不到信息
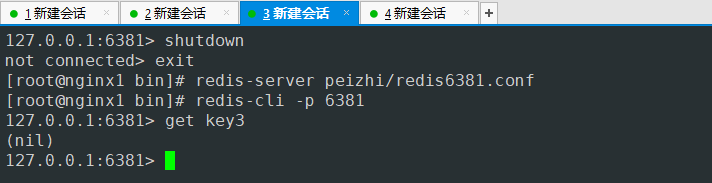
- 查询down掉从机的角色 启动服务后 变成了master 主节点
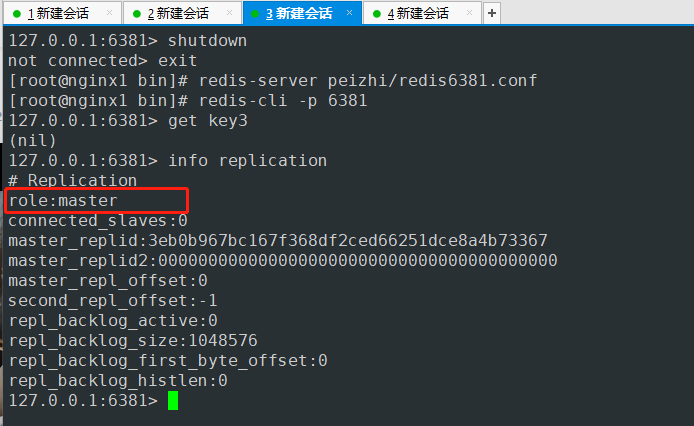
- 再次设置down掉的机器为从机 查询刚才set的key3的值 可以查到
127.0.0.1:6381> get key3
(nil)
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_replid:3eb0b967bc167f368df2ced66251dce8a4b73367
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 #再次设置为从机
OK
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:827
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:4f660b5694c705fb64403b08984b92602de96317
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:827
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:814
repl_backlog_histlen:14
127.0.0.1:6381> get key3 #可以查询到down机前master写入的信息
"v3"
127.0.0.1:6381>
***总结 ***
命令行设置的主从 从机down机后重启后会变为主机 无法查询到集群主机写入的信息 重新设置为从机后可以查询到down机后主机写入的信息
以上集群架构图
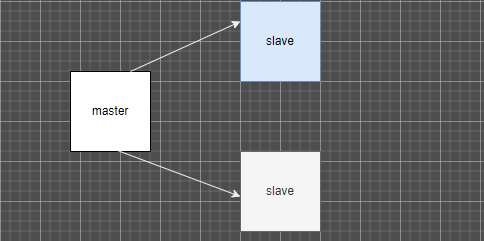
以上的架构是一主二从 当主节点挂掉之后 整个集群不具有写入功能,
另一种主从架构尝试
以上架构的问题是 当主节点挂掉后 整个集群只有读功能 不具备写入功能
我们也可以尝试配置成如下架构
6379端口的服务仍然作为主节点
6380端口的服务 把自己设置为salve 同时把主节点设置为 6379
6381端口的服务 把自己设置为slave 同时把主节点设置为6380
这样6380端口的服务 既作为 6379端口服务的salve 又是6381端口服务的master
接上面的环境进行改造
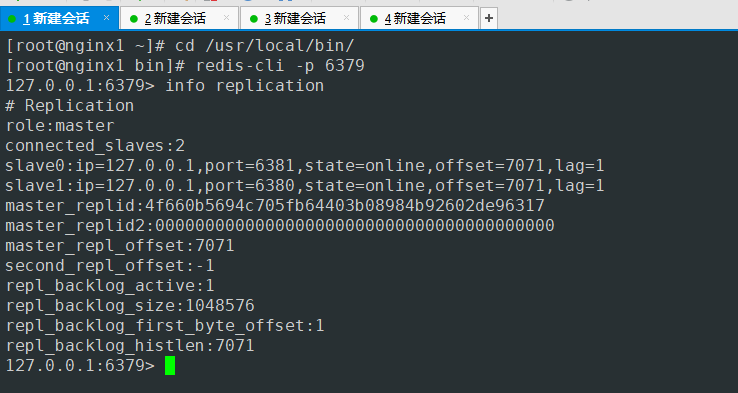
6379端口服务
改造前 主节点 同时有两个slave节点
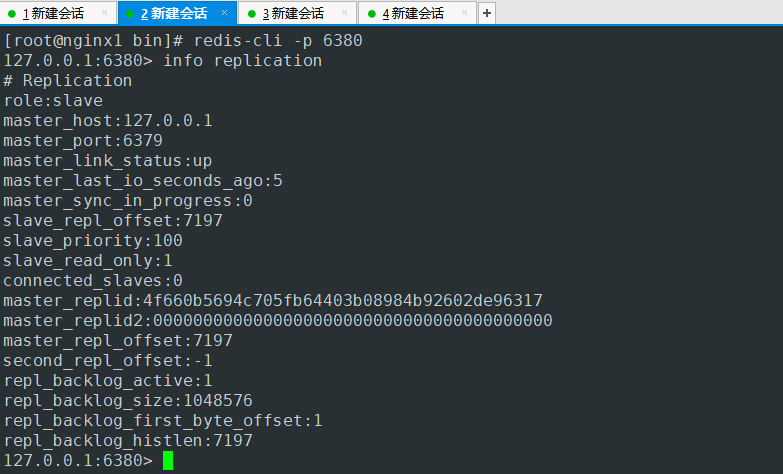
6380端口服务这个不需要修改
目前是从节点 同时主节点是6379端口
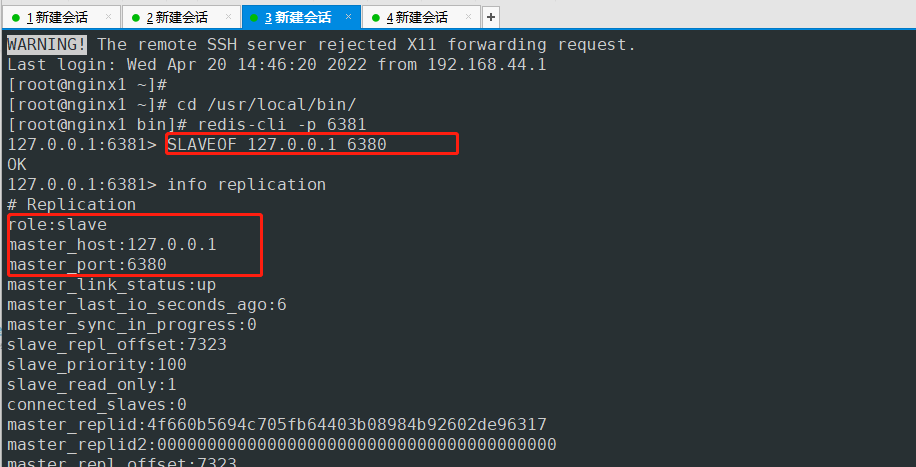
修改6381端口这台服务
6381这台的master修改为6380端口的服务
再次查询6379端口master这台服务
salve变成了一个
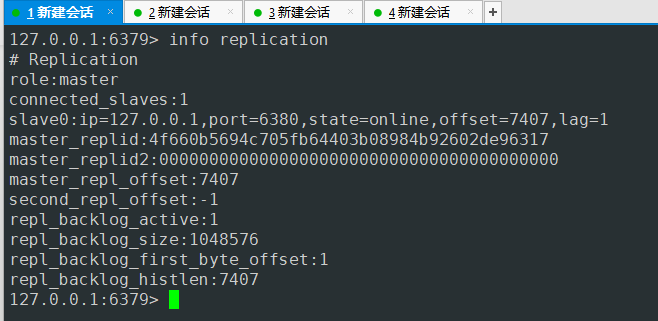
6380此时即使主节点也是从节点
我们查询的时候这台仍然是从节点
也就是目前是不能写入只能查询
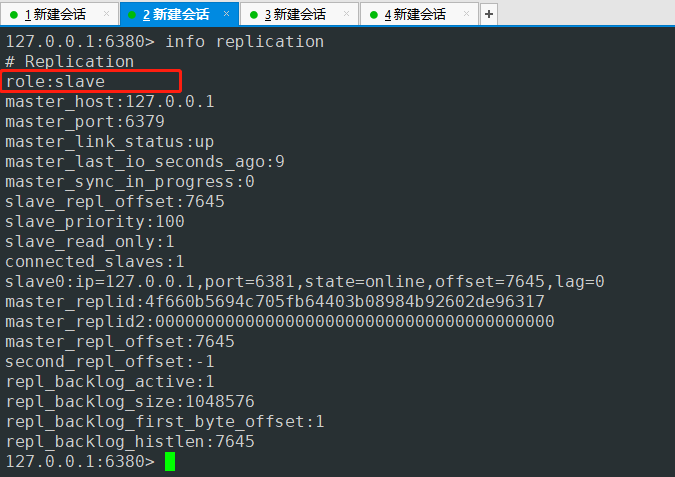
确认三台主机同步是否正常
6379端口写入

6380端口查询

6381端口查询

同步没有问题
模拟故障3
6379端口服务故障关机
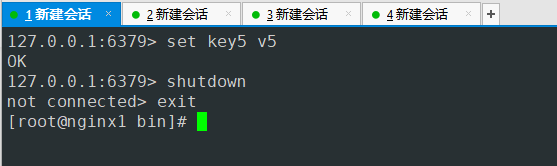
6380仍然是从节点
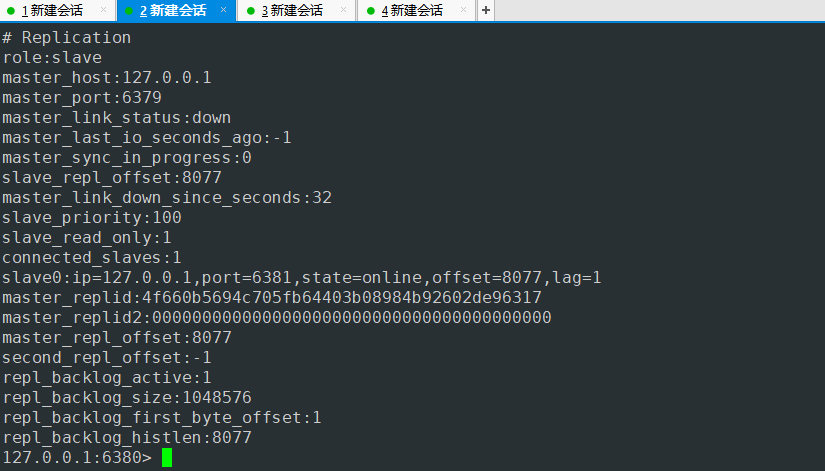
同时6381也是从节点 目前集群也是一种群龙无首的状态 哨兵模式之前 这个问题是无法解决的 只能通过手动配置6380端口服务为主节点
6380端口服务操作
127.0.0.1:6380> SLAVEOF no one #设置没有主节点
OK
127.0.0.1:6380> info replication #再次查询自己就变成了主节点
# Replication
role:master #主节点
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=8077,lag=1 #设置的从节点6381信息还在正常
master_replid:9de587961909c012366d01ef97578ef118226747
master_replid2:4f660b5694c705fb64403b08984b92602de96317
master_repl_offset:8091
second_repl_offset:8078
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:8091
127.0.0.1:6380>
当6379端口服务重启服务再次回归的时候
已经不属于整个集群 是一个单独的master了
以上问题 自动选举master,master挂掉重新回归的问题 可以通过哨兵模式实现。
哨兵模式
哨兵模式介绍
主从切换 是当主服务down机之后 需要干预把服务切换到另外一台作为备机上作为主服务器,人工切换存在时间差,一段时间内服务不可用 ,redis从2.8开始提供sentinel哨兵模式,。
哨兵模式启动后 哨兵会生成一个独立的进程,作为进程它会独立存在,
哨兵通过发送命令 等待redis响应回复 从而监控多个redist服务,一段时间内没有回复哨兵 则判断为故障,通过一定算法在集群内选举另外一台slave为主节点,当旧的主节点恢复服务加入集群后,会被设置为集群的slave节点。
哨兵工作原理
-
Slave 启动成功连接到 master 后会发送一个sync同步命令
-
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行
完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:slave服务在接收到数据库文件数据后,将其存盘并全部加载到内存中。 相当于复制一份当前master状态的副本。
增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步 只修改master修改的部分,其它部分不动。增删改查。
- 只要是slave重新连接master 一定会进行一次全量复制!!
哨兵模式主要作用
通过发送命令 返回并监控redis服务运行状态 包含master和slave的状态
当检测到主机master服务down掉 会自动选举一台slave为master 通过发布订阅的方式通知到其它slave主机,修改配置文件 让它们切换master主机
配置哨兵模式
环境恢复至 127.0.0.1 6379 主/6380/6381作为从节点
与 redis.conf 同目录下 配置文件sentinel.conf
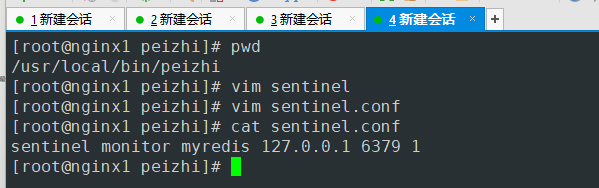
sentinel monitor myredis 127.0.0.1 6379 1 #sentinel monitor 哨兵监控 myredis这个随便起名 后面是监控的主机 ip port 1表示这个主服务挂掉后 哨兵选举谁作为新的master
启动哨兵

redis-sentinel peizhi/sentinel.conf
启动后可以看到当前的master和slave
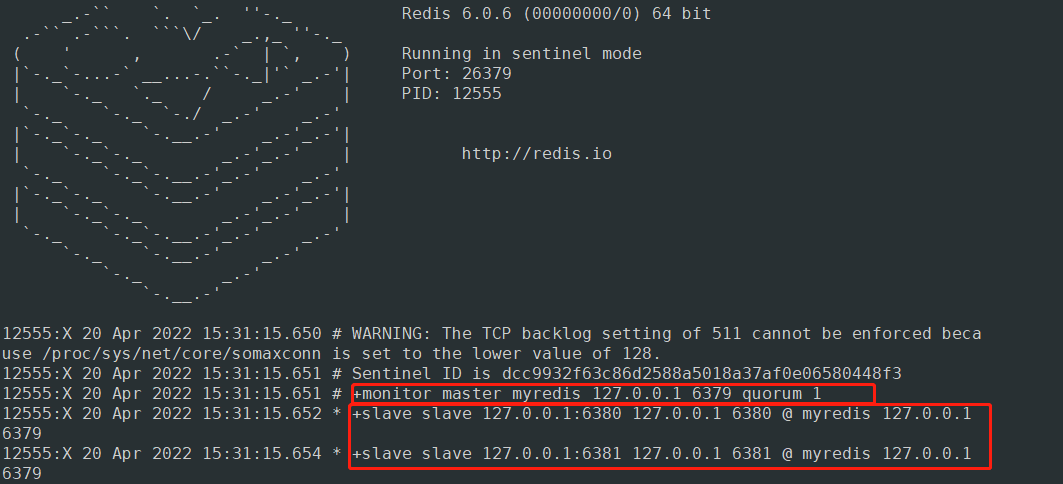
模拟故障 主节点挂掉
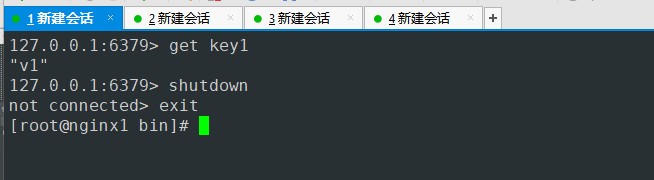
6380端口服务变成了主节点
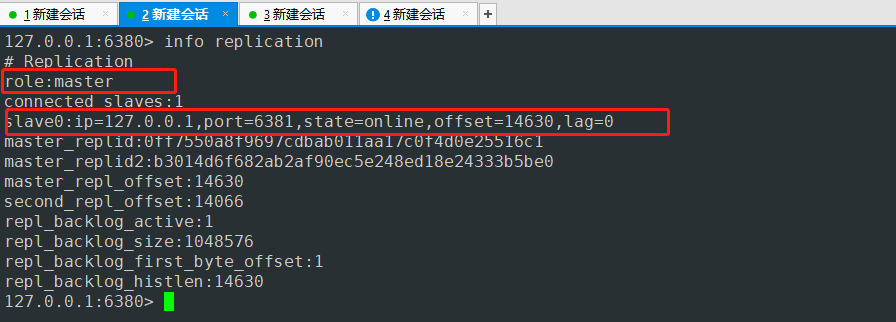
6381端口服务上验证 6380成为了主节点
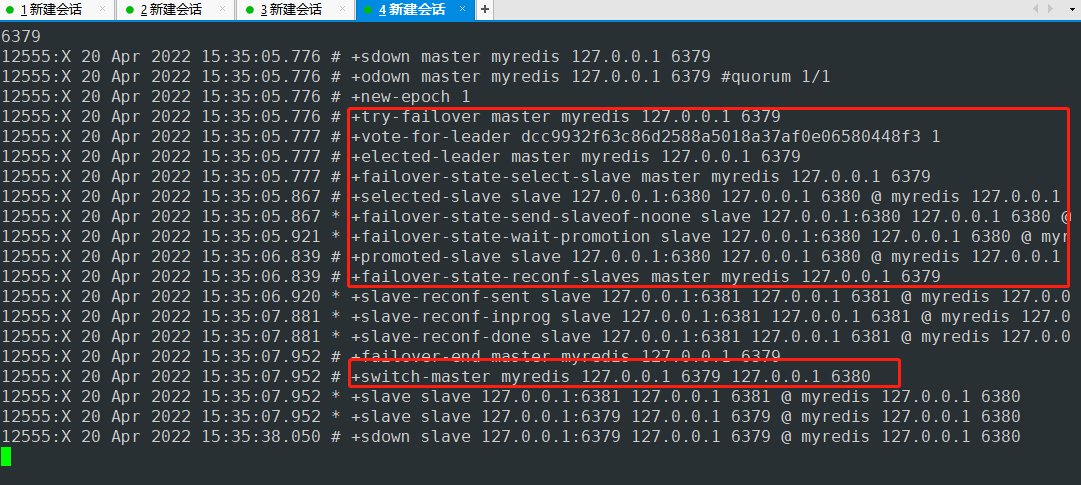
哨兵日志输出
主节点故障通过算法选举6380端口服务为主节点
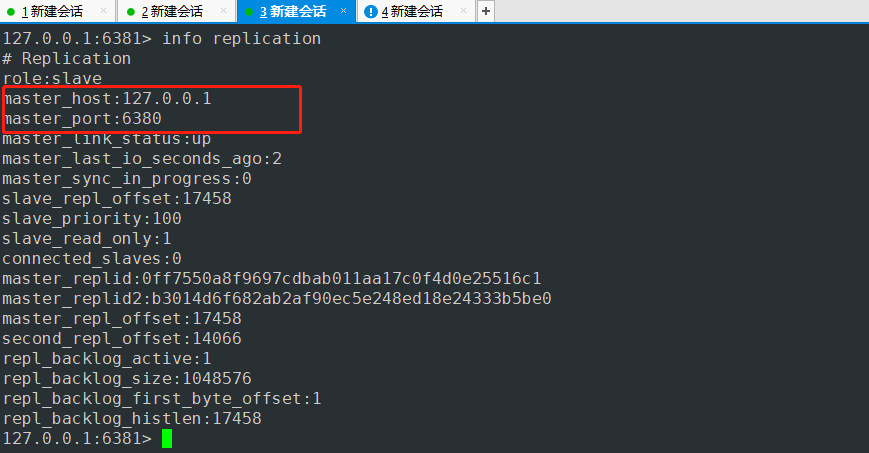
重新启动6379端口服务查询自己是独立的master
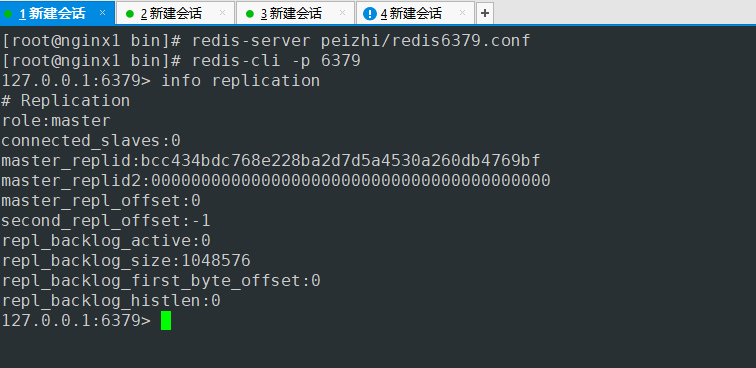
追踪哨兵日志 发现哨兵自动把 127.0.0.1 6379设置为7380主节点的从节点
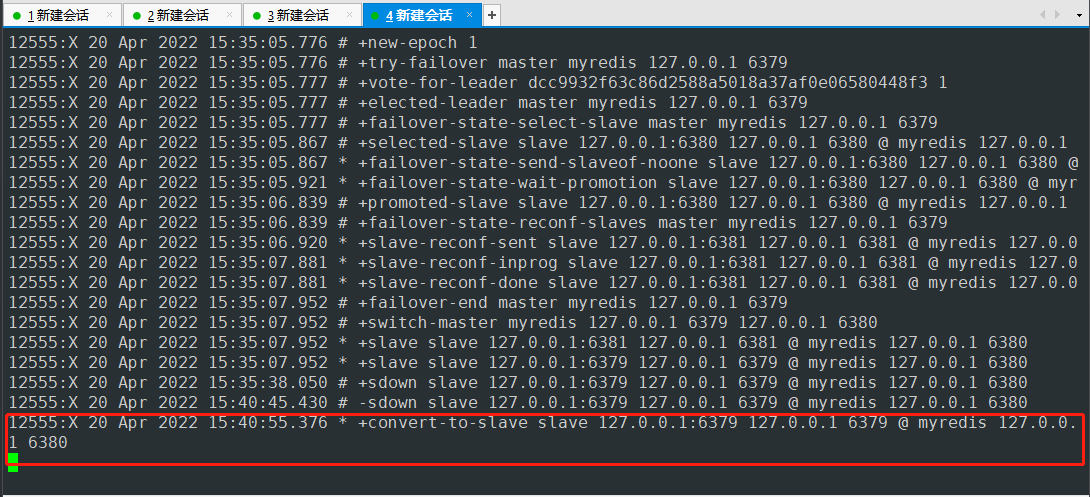
再次查询6379端口服务的信息
发现变成了salve节点 同时master主机是6380端口服务 与哨兵日志输出的信息一致。
哨兵模式配置文件解析
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379 #像redis.cong 如果有哨兵集群 需要配置多个端口
# 哨兵sentinel的工作目录
dir /tmp #定义自己的工作目录 生成自己的文件
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel 哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供
密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着 越多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那
里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,
slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知
相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),
将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信
息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配
置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无
法正常启动成功。
#通知脚本
# shell编程
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已
经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通
信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # 一般都是由运维来配
置!
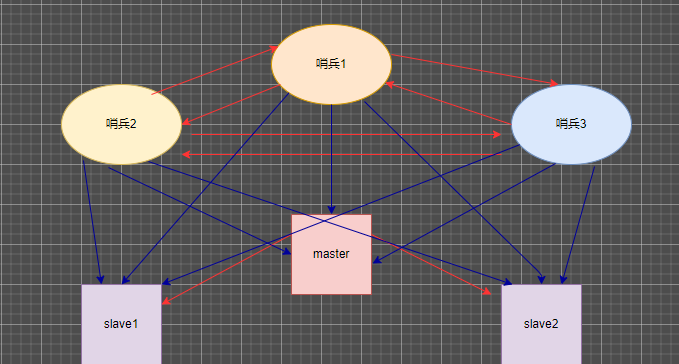
多哨兵模式介绍
一个哨兵对redis监控可能会出现问题,可以使用多哨兵模式进行监控,各个哨兵之间会进行监控 这样就形成了多哨兵模式
哨兵模式优缺点
优点
主从复制的优点他都有
自动切换master 实现集群高可用,实现故障转移
缺点
Redis集群不容易在线扩容
哨兵模式的配置项很多,哨兵模式配置比较麻烦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号