系统架构的演进
系统架构的演进
上古架构
90年代 单机时代 一台服务器甚至可以承载前端应用和数据库 稍微正式点的 两台服务器足以 一台前端 一台后端mysql
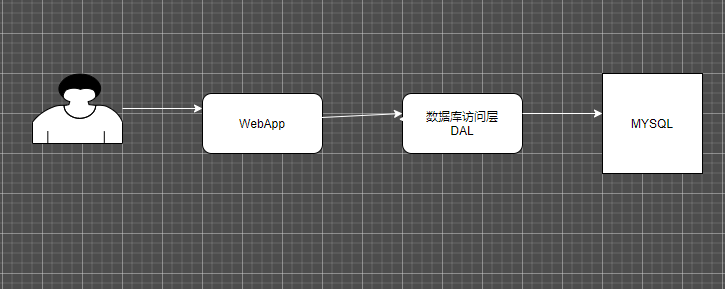
随着数据量的增加出现以下问题
-
数据量大 读写在一起 单台mysql访问量太大
-
数据量大 单台存储 数据索引很慢
-
单台数据库内存 磁盘都存在上限 到一定容量无法扩展
-
文件直接读取硬盘 硬盘的读写速度与内存的读写速度相差太大 大多数时间都是等待磁盘检索
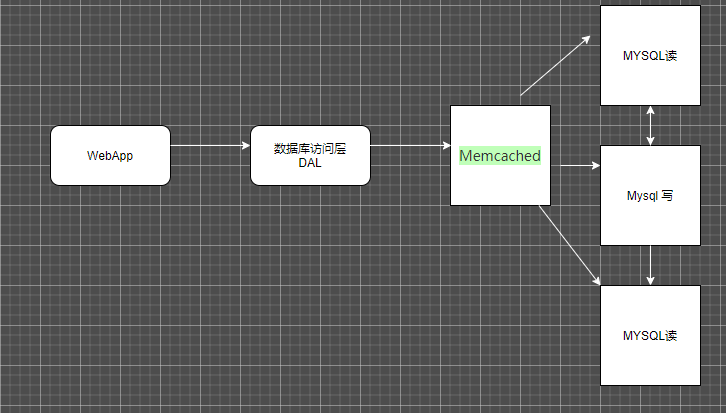
Memcached + Mysql +读写分离
通过内存缓存 memcached 用户读取的数据来源于内存 速度远快于磁盘
读写分离 ,相对于写入数据来说来说, 用户的数据访问 大多数是读取数据 ,
通过后端集群架构 多台读主机 相对少量的写主机 读写之间通过数据同步实现数据一致
这样就实现了读写分离
每当出现性能瓶颈的时候 历史总是分为多个分支去解决问题
IBM走向了一个分支 开发出小型机 ,内部磁盘冗余 内存扩展,多网卡等等的小型机,总之一台机器上 我想办法帮你解决你说的问题
但是价格也是很感人的
另外一个分支也是大家看到的分支 集群架构
打个比方 如果一台车太重了 一头牛拉不动 IBM相当于找一台更强壮的牛,这个牛更贵 坏了也更费钱
而我们的想法 既然一头牛拉不动 我找两头牛,一头牛坏了 我们可以更换 也不贵
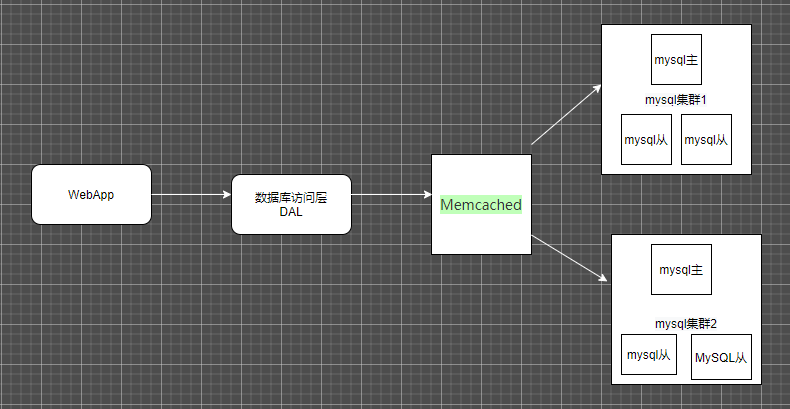
垂直拆分(数据库中的表放到不同数据库) + 水平拆分(一张表数据分别存储到不同数据库)
按照上面的架构继续演进 性能的瓶颈出现在了mysql上 技术用cache内存 后面的数据越来越大 数据库的技术也
不可能突然推进很多 ,既然数据访问到最后就是数据的表 那我们就把用户访问的表拆分开 不让一个表太大 有太多的热点数据,同时把不同的数据分成不同的库
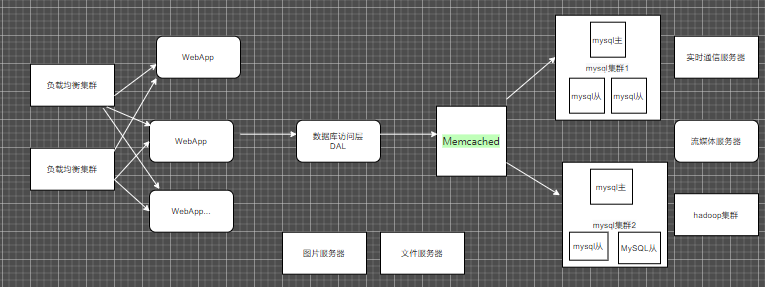
当今架构
当今年代 数量井喷式增长 数据的样式也各种各样,图片 视频 定位信息等层出不穷 大数据的年代 mysql终于力不从心 Nosql应运而生 解决了大数据时代的问题
关系型数据库:列+行,同一个表下数据的结构是一样的。
非关系型数据库:数据存储没有固定的格式,并且可以进行横向扩展。
NoSQL(not only sql )泛指非关系型数据库,随着超大规模的高并发的社区,暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的。
目前企业的常见架构
Nosql特点
-
方便扩展(数据之间没有关系 好扩展)
-
大数据量高性能(Redis基于内存的读写 一秒可以写8万次,读11万次,性能会比较高)
-
数据类型是多样型的(不用事先设计数据库,随取随用)
传统RDMS
-
- 结构化组织
-
- SQL
-
- 数据和关系都存在单独的表中 row col
-
- 操作,数据定义语言
-
- 严格的一致性
-
- 基础的事务
-
-...
Nosql
-
- 没有固定的查询语言
-
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
-
- 最终一致性
-
- CAP定理和BASE
-
- 高性能,高可用,高扩展
-
- ...
大数据时代的3V :主要是描述问题的
- 海量Velume
- 多样Variety
- 实时Velocity
大数据时代的3高 : 主要是对程序的要求
- 高并发
- 高可扩
- 高性能
-
当今公司 NoSQL + RDBMS
Nosql分类
- KV键值对
Redis
Memcache
-
文档型数据库(bson数据格式)
MongoDB(掌握)
基于分布式文件存储的数据库。C++编写,用于处理大量文档。
MongoDB是RDBMS和NoSQL的中间产品。MongoDB是非关系型数据库中功能最丰富的,NoSQL中最像关系型数据库的数据库。
ConthDB
-
列存储数据库
- HBase(大数据)
- 分布式文件系统
-
图关系数据库
用于广告推荐,社交网络
- Neo4j、InfoGrid

-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号