

Kafka消费者-从Kafka读取数据
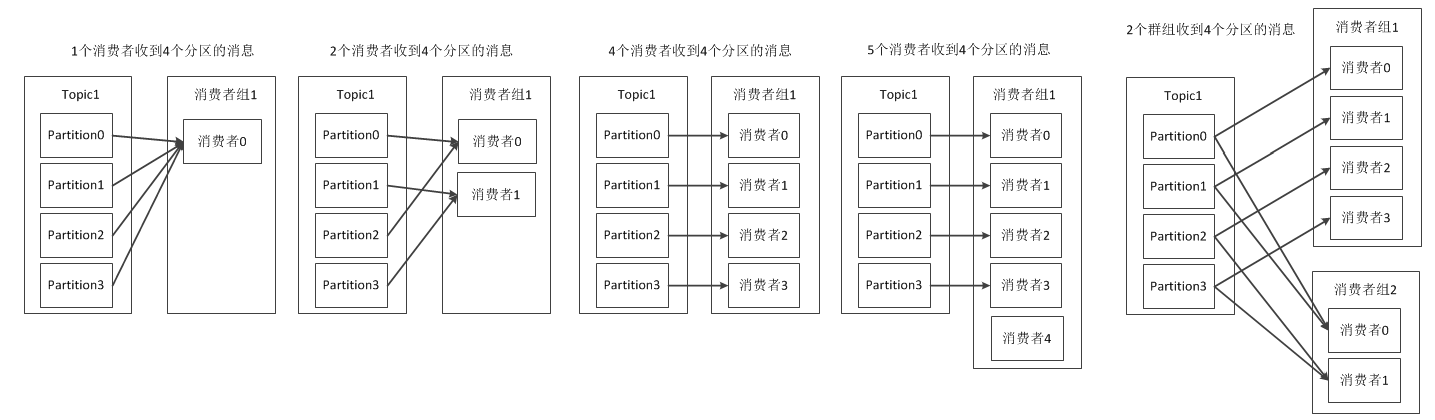
(1)Customer和Customer Group
(1)两种常用的消息模型
队列模型(queuing)和发布-订阅模型(publish-subscribe)。
队列的处理方式是一组消费者从服务器读取消息,一条消息只由其中的一个消费者来处理。
发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。
(2)Kafka的消费者和消费者组
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了队列模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 一个消费者组中消费者订阅同一个Topic,每个消费者接受Topic的一部分分区的消息,从而实现对消费者的横向扩展,对消息进行分流。
注意:当单个消费者无法跟上数据生成的速度,就可以增加更多的消费者分担负载,每个消费者只处理部分partition的消息,从而实现单个应用程序的横向伸缩。但是不要让消费者的数量多于partition的数量,此时多余的消费者会空闲。此外,Kafka还允许多个应用程序从同一个Topic读取所有的消息,此时只要保证每个应用程序有自己的消费者组即可。
消费者组的概念就是:当有多个应用程序都需要从Kafka获取消息时,让每个app对应一个消费者组,从而使每个应用程序都能获取一个或多个Topic的全部消息;在每个消费者组中,往消费者组中添加消费者来伸缩读取能力和处理能力,消费者组中的每个消费者只处理每个Topic的一部分的消息,每个消费者对应一个线程。
(3)线程安全
在同一个群组中,无法让一个线程运行多个消费者,也无法让多线线程安全地共享一个消费者。按照规则,一个消费者使用一个线程,如果要在同一个消费者组中运行多个消费者,需要让每个消费者运行在自己的线程中。最好把消费者的逻辑封装在自己的对象中,然后使用java的ExecutorService启动多个线程,使每个消费者运行在自己的线程上,可参考https://www.confluent.io/blog
(2)Partition Rebalance分区再均衡
(1)消费者组中新添加消费者读取到原本是其他消费者读取的消息
(2)消费者关闭或崩溃之后离开群组,原本由他读取的partition将由群组里其他消费者读取
(3)当向一个Topic添加新的partition,会发生partition在消费者中的重新分配
以上三种现象会使partition的所有权在消费者之间转移,这样的行为叫作再均衡。
再均衡的优点:
给消费者组带来了高可用性和伸缩性
再均衡的缺点:
(1)再均衡期间消费者无法读取消息,整个群组有一小段时间不可用
(2)partition被重新分配给一个消费者时,消费者当前的读取状态会丢失,有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。
因此需要进行安全的再均衡和避免不必要的再均衡。
(3)创建Kafka消费者、订阅主题、轮询
Properties props = new Properties(); props.put("bootstrap", "broker1:9092,broker2:9092"); props.put("group.id", "CountryCounter"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //1.创建消费者 KafkaConsuner<String, String> consumer = new KafkaConsumer<String, String>(props); //2.订阅Topic //创建一个只包含单个元素的列表,Topic的名字叫作customerCountries consumer.subscribe(Collections.singletonList("customerCountries")); //支持正则表达式,订阅所有与test相关的Topic //consumer.subscribe("test.*"); //3.轮询 //消息轮询是消费者的核心API,通过一个简单的轮询向服务器请求数据,一旦消费者订阅了Topic,轮询就会处理所欲的细节,包括群组协调、partition再均衡、发送心跳 //以及获取数据,开发者只要处理从partition返回的数据即可。 try { while (true) {//消费者是一个长期运行的程序,通过持续轮询向Kafka请求数据。在其他线程中调用consumer.wakeup()可以退出循环 //在100ms内等待Kafka的broker返回数据.超市参数指定poll在多久之后可以返回,不管有没有可用的数据都要返回 ConsumerRecord<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { log.debug(record.topic() + record.partition() + record.offset() + record.key() + record.value()); //统计各个地区的客户数量,即模拟对消息的处理 int updatedCount = 1; updatedCount += custCountryMap.getOrDefault(record.value(), 0) + 1; custCountryMap.put(record.value(), updatedCount); //真实场景中,结果一般会被保存到数据存储系统中 JSONObject json = new JSONObject(custCountryMap); System.out.println(json.toString(4)); } } } finally { //退出应用程序前使用close方法关闭消费者,网络连接和socket也会随之关闭,并立即触发一次再均衡 consumer.close(); }
(4)消费者的配置
1:fetch.min.bytes,指定消费者从broker获取消息的最小字节数,即等到有足够的数据时才把它返回给消费者
2:fetch.max.wait.ms,等待broker返回数据的最大时间,默认是500ms。fetch.min.bytes和fetch.max.wait.ms哪个条件先得到满足,就按照哪种方式返回数据
3:max.partition.fetch.bytes,指定broker从每个partition中返回给消费者的最大字节数,默认1MB
4:session.timeout.ms,指定消费者被认定死亡之前可以与服务器断开连接的时间,默认是3s
5:auto.offset.reset,消费者在读取一个没有偏移量或者偏移量无效的情况下(因为消费者长时间失效,包含偏移量的记录已经过时并被删除)该作何处理。默认是latest(消费者从最新的记录开始读取数据)。另一个值是 earliest(消费者从起始位置读取partition的记录)
6:enable.auto.commit,指定消费者是否自动提交偏移量,默认为true
7:partition.assignment.strategy,指定partition如何分配给消费者,默认是Range。Range:把Topic的若干个连续的partition分配给消费者。RoundRobin:把Topic的所有partition逐个分配给消费者
8:max.poll.records,单次调用poll方法能够返回的消息数量
(5)提交和偏移量
1、消费者为什么要提交偏移量
当消费者崩溃或者有新的消费者加入,那么就会触发再均衡(rebalance),完成再均衡后,每个消费者可能会分配到新的分区,而不是之前处理那个,为了能够继续之前的工作,消费者需要读取每个partition最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
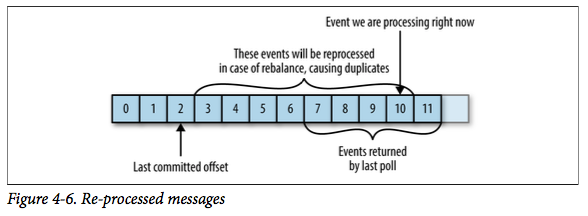
2、提交偏移量可能带来的问题
case1:如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
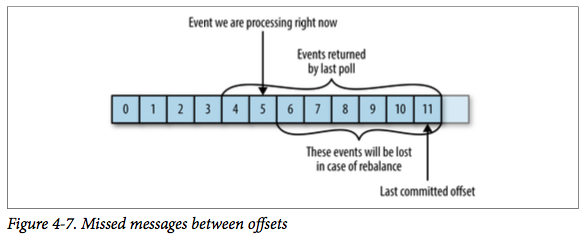
case2:如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
3、提交偏移量的方式
(1)自动提交 Automatic Commit
enable.auto.commit设置成true(默认为true),那么每过5s,消费者自动把从poll()方法接收到的最大的偏移量提交。提交的时间间隔由auto.commit.interval.ms控制,默认是5s
自动提交的优点是方便,但是可能会重复处理消息
(2)提交当前偏移量 Commit Current Offset
将enable.auto.commit设置成false,让应用程序决定何时提交偏移量。commitSync()提交由poll()方法返回的最新偏移量,所以在处理完所有消息后要确保调用commitSync,否则会有消息丢失的风险。commitSync在提交成功或碰到无法恢复的错误之前,会一直重试。如果发生了再均衡,从最近一批消息到发生再均衡之间的所有消息都会被重复处理。
不足:broker在对提交请求作出回应之前,应用程序会一直阻塞,会限制应用程序的吞吐量
while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } try { consumer.commitSync();//处理完当前批次的消息,在轮询更多的消息之前,调用commitSync方法提交当前批次最新的消息 } catch (CommitFailedException e) { log.error("commit failed", e);//只要没有发生不可恢复的错误,commitSync方法会一直尝试直至提交成功。如果提交失败,我们也只能把异常记录到错误日志里 } }
(3)异步提交
异步提交的commitAsync,只管发送提交请求,无需等待broker响应。commitAsync提交之后不进行重试,假设要提交偏移量2000,这时候发生短暂的通信问题,服务器接收不到提交请求,因此也就不会作出响应。与此同时,我们处理了另外一批消息,并成功提交了偏移量3000,。如果commitAsync重新尝试提交2000,那么它有可能在3000之后提交成功,这个时候如果发生再均衡,就会出现重复消息。
while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } consumer.commitAsync(new OffsetCommitCallback() {//在broker作出响应后执行回调函数,回调经常被用于记录提交错误或生成度量指标 public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) { if (e != null) { log.error("Commit Failed for offsets {}", offsets, e); } }}); }
(4)同步和异步组合提交
一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大的问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。但是如果在关闭消费者或再均衡前的最后一次提交,就要确保提交成功。
因此,在消费者关闭之前一般会组合使用commitAsync和commitSync提交偏移量。
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } consumer.commitAsync();//如果一切正常,我们使用commitAsync来提交,这样速度更快,而且即使这次提交失败,下次提交很可能会成功 } catch (CommitFailedException e) { log.error("commit failed", e); } finally { try { consumer.commitSync();//关闭消费者前,使用commitSync,直到提交成成功或者发生无法恢复的错误 } finally { consumer.close(); } }
(5)提交特定的偏移量
消费者API允许调用commitSync()和commitAsync()方法时传入希望提交的partition和offset的map,即提交特定的偏移量。
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();//用于跟踪偏移量的map int count = 0; while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());//模拟对消息的处理
//在读取每条消息后,使用期望处理的下一个消息的偏移量更新map里的偏移量。下一次就从这里开始读取消息 currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, “no matadata”)); if (count++ % 1000 == 0) {//每处理1000条消息就提交一次偏移量,在实际应用中,可以根据时间或者消息的内容进行提交 consumer.commitAsync(currentOffsets, null); }
}
}
(6)再均衡监听器
在为消费者分配新的partition或者移除旧的partition时,可以通过消费者API执行一些应用程序代码,在使用subscribe()方法时传入一个ConsumerRebalanceListener实例。
ConsumerRebalanceListener需要实现的两个方法
1:public void onPartitionRevoked(Collection<TopicPartition> partitions)方法会在再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管partition的消费者就知道该从哪里开始读取了。
2:public void onPartitionAssigned(Collection<TopicPartition> partitions)方法会在重新分配partition之后和消费者开始读取消息之前被调用。
下面的例子演示如何在失去partition的所有权之前通过onPartitionRevoked()方法来提交偏移量。
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();//用于跟踪偏移量的map private class HandleRebalance implements ConsumerRebalanceListener { @Override public void onPartitionsAssigned(Collection<TopicPartition> partitions) { } @Override public void onPartitionsRevoked(Collection<TopicPartition> partitions) { //如果发生再均衡,要在即将失去partition所有权时提交偏移量。 //注意:(1)提交的是最近处理过的偏移量,而不是批次中还在处理的最后一个偏移量。因为partition有可能在我们还在处理消息时被撤回。 //(2)我们要提交所有分区的偏移量,而不只是即将市区所有权的分区的偏移量。因为提交的偏移量是已经处理过的,所以不会有什么问题。 //(3)调用commitSync方法,确保在再均衡发生之前提交偏移量 consumer.commitSync(currentOffsets); } } try{ consumer.subscribe(topics, new HandleRebalance()); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());//模拟对消息的处理 //在读取每条消息后,使用期望处理的下一个消息的偏移量更新map里的偏移量。下一次就从这里开始读取消息 currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, “no matadata”)); } consumer.commitAsync(currentOffsets, null); } catch(WakeupException e) { //忽略异常,正在关闭消费者 } catch (Exception e) { log.error("unexpected error", e); } finally { try{ consumer.commitSync(currentOffsets); } finally { consumer.close(); } }
参考:《Kafka权威指南》
