

YARN的重启动问题:RM Restart/RM HA/Timeline Server/NM Restart
ResourceManger Restart
ResourceManager负责资源管理和应用的调度,是YARN的核心组件,有可能存在单点失败的问题。ResourceManager Restart是使RM在重启动时能够使Yarn集群正常工作的feature,并且使RM的出现的失败不被用户知道。
ResourceManager Restart feature is divided into two phases:
- ResourceManager Restart Phase 1 (Non-work-preserving RM restart,since hadoop2.4.0): Enhance RM to persist application/attempt state and other credentials information in a pluggable state-store. RM will reload this information from state-store upon restart and re-kick the previously running applications. Users are not required to re-submit the applications.
- ResourceManager Restart Phase 2 (Work-preserving RM restart, since hadoop2.6.0): Focus on re-constructing the running state of ResourceManager by combining the container statuses from NodeManagers and container requests from ApplicationMasters upon restart. The key difference from phase 1 is that previously running applications will not be killed after RM restarts, and so applications won’t lose its work because of RM outage.
ResourceManager High Availability
Hadoop2.4.0之前,ResourceManager存在单点失败的问题。Yarn的HA(高可用)使用Actice/Standby结构。在任意一个时刻,只有一个Active RM,一个到多个Standby RM。其实就是将ResourceManager进行了备份,使得系统中存在Active RM和Standby RM。
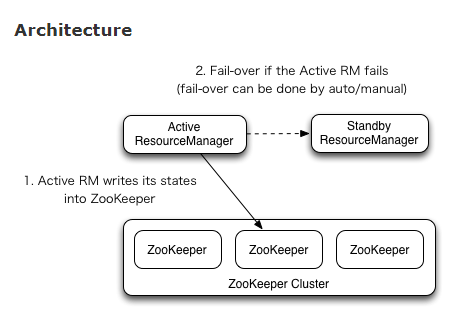
Manual transitions and failover
输入yarn rmadmin
Automatic failover
当RM 失效或者不再响应时,基于Zookeeper的ActiveStandbyElector(已经内嵌到了RM中,不用启动单独的ZKFC daemon)选举出新的Active RM。
Client, ApplicationMaster and NodeManager on RM failover
如果有多个RM,那么所有节点上的yarn-site.xml文件都需要列出所有的RM。Clients、AMs、NMs以Round-Robin的方式连接RMs,直到遇到一个Active RM为止。如果Active RM失效,那么重新以Round-Robin的方式找到新的Active RM。
The YARN Timeline Server
YARN通过Timeline Server解决apps当前信息和历史信息的存储和检索。TimelineServer的两个职责:
Persisting Application Specific Information
信息的搜集和检索与特定的app或者框架有关。例如MapReduce框架的信息可以包括number of map tasks, reduce tasks, counters…etc。用户可以将app专门的信息通过Application Master包含的TimelineClient
或者App的container进行发布。
Persisting Generic Information about Completed Applications
Generic information为app level的信息,例如queue-name,user info等。通用数据被Yarn的RM发布到timeline store中,用于web-UI的已经完成的apps的信息展示。
NodeManager Restart
NodeManager Restart机制能够使NodeManager所在节点的active Containers不丢失。NM在处理container 管理请求时,将必要的state存储到local state-store。当NMs restart时,首先为不同的子系统加载state,然后让子系统使用加载的state进行恢复。
enabling NM Restart:
(1) 将/conf/yarn-site.xml中的yarn.nodemanager.recovery.enabled设置为true。默认为false
(2) Configure a path to the local file-system directory where the NodeManager can save its run state.
(3) Configure a valid RPC address for the NodeManager.
(4) Auxiliary services.
Link:
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerRestart.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/TimelineServer.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/NodeManagerRestart.html
