Object Oriented Homework Summary(1)
OO第一单元总结(表达式求导)
一、程序结构分析
第一次作业(a*x^b)
本次作业需要完成形如多个a*x^b相加(减)构成的多项式求导,并以输出长度作为性能指标。
(1)UML:
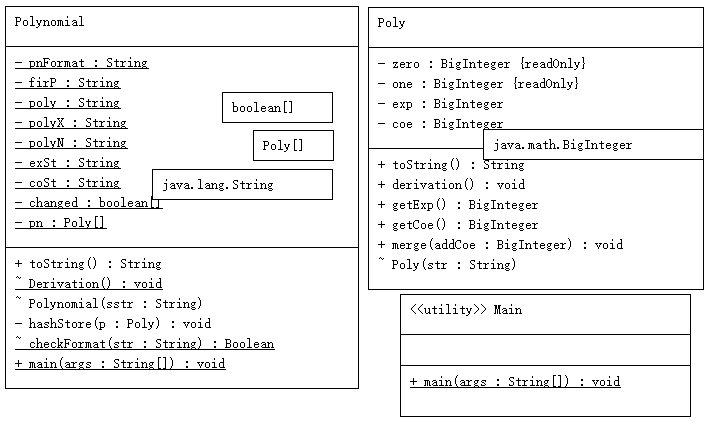
(2)功能概述
本次作业难度小,总体而言实现思路较为固定。
输入部分,本人利用正则表达式首先判断输入是否正确,如果正确按照在利用正则表达式的.find(String)方法读取每一项内容。
存储部分,将读到的内容先生成哈希值,再存入数组中。对,你没看错,由于本人当时并不知晓java自带的HashMap类,因此手动实现了一个哈希表算法,碰撞的处理方法是存入下一个空位置。如果查询到的项与存入项指数相同那么调用合并方法。
输出部分,中规中矩的调用重写的toString。当时还未想到将正项提前,因此在性能上未做到最优。(PS. 要早知道这是最后一次性能拿满的机会肯定会更认真对待的,sigh....)
第二次作业(a*x^b*cos(x)^c*sin(x)^d)
本次作业在前次的基础上加入了三角函数。同时项的格式也不仅限于a*x^b,转而变成了(x^n|cos(x)^n|sin(x)^n|n)+这样的形式。
(1)UML:

(2)功能概述
本次作业从本质上和上次作业类似,处理思路基本沿用第一次作业。
读入部分。通过正则表达式先读入一个独立项,对于项中得每一个部分利用正则表达式读入单独得因子。由于项和因子得格式是固定的,因此正则表达式完全可以胜任此次作业的需求。另外,在读入因子时可以通过equals()方法合并同类项,每一项都可以被四个参数(系数,x指数,cos(x)指数,sin(x)指数)表达。
计算部分与第一次作业类似,只是这次的单项求导结果会是最多四个项,因此在这次作业中本人没有采用更复杂的结构,而是用统一的输出格式返回一个包含四个类的数组。
除此以外,这次加入了一个allMerge()方法来化简多项式,化简采用的范式是(sin(x)^2+cos(x)^2),在每次合并前判断合并结果的长度是否小于原长度,如果小于则执行操作。总而言之,采用的是贪心策略进行合并化简,因此在某些特殊情况(比如sin(x)^4+cos(x)^4+2*sin(x)^2*cos(x)^2)下无法达成最优化简得结果。
输出部分和第一次相同,调用项的toString()方法形成最终的输出表达式字符串。为了保证正项提前采用了双StringBuilder的方法,如果正项则放入第一个StringBuilder;如果是负项则放入第二个。最后先输出第一个再输出第二个。
第三次作业(嵌套表达式)
(1)UML:

(2)功能概述
本次作业和前两次从本质上有着比较大的不同。尽管单纯从功能角度分析是真包含关系,然而实现角度比较难利用前两次的算法或是整体架构。尽管如此,一些底层实现的思路是相通的,可以一定程度借鉴之前。
本次作业的架构采用的是分层,即将所有表达式分成三层:Polynomial,Term,Factor。其中Polynomial由多个Term加减连接而成;Term由多个Factor相乘连接而成;Factor分成五类(sin(F)^n,cos(F)^n,x^n,n,(P))
输入部分。本次作业由于支持嵌套,输入需要一定程度的封装。本人在设计上犯了2,先检查格式错误再读取,这就导致许多格式检查或是重复或是遗漏(尽管没有检测出来,但不排除这种可能)。更合理的设计应当是将格式检查分离成多层,每层只检测属于本层的格式问题,其余的抛给下层判断。
计算部分。求导的本质没有改变,但每层之间的状态转换表本质上是一个有限状态机。Polymonial的求导结果一定是Polymonial;Term的求导结果是多个Term;Factor的求导结果可以被归结成(Polymonial)类型的Factor,如此一来便可以规范化求导的过程,使得递归求导的过程可预测。
输出部分。本次采用的是递归输出,即上层的toString方法调用下层的toString,遇到基本元素的toString则返回其实际内容。
二、Bug分析
一言以蔽之,正则。(没错,就这个,没别的了,真的)
其实这单元的作业在求导的计算方面很难出现问题。第一二两次作业较为简单,只需要指数减一即可;第三次作业一但形成模块化处理,如果整个程序能够正常运行,单独某个模块出现计算问题的概率可以忽略不计。
三、发现别人Bug所采用的策略
一言以蔽之,正则。
除此之外,大量随机样例对拍。
很多人代码不写注释,没有说明,可读性几乎不存在。
事实上,从debug的结果上来看,大多数碰到的问题都是格式判断有误,要不就是少考虑了一些特殊情况(比如指数为零,或是乘零乘负一)。一些格式问题来源于优化,比如结果是零时无输出等。
四、重构心得
本部分分为两个主题:架构设计以及细节实现。
架构设计
出于面向对象的思路,综合自己几次代码,所获得的心得如下:
1、封装的完整性
对于每一个类一定应该有明确的功能范围。不仅要规范其中构造方法所需要的数据格式,也要规范这个类所应对的问题范围。比如第三次作业的Polynomial类,其应对的应当是所有形如([+-]Term)+这样的表达式的识别以及处理。对于功能部分比如格式判断,应当保证能够识别所有属于本层的格式问题(比如加减号的数量),并且对于不属于本层范畴的问题应当将其包装递送至下一层处理(Term)。如此设计可以保证类和类之间的协作实现连贯性与完备性,避免功能的重复实现以及缺漏现象。
2、数据递送的规范性
承接上条。每个方法的输入和输出应当保证其规范性。大多数涉及到类之间交互的方法不应当将基础数据(比如Int或是BigInteger)作为递送的形式,而是将数据封装成一个独立的类再传递给其他类。比如derivate()方法,不同层的derivate()应当返回的内容时不同的,上级调用下级derivate()时收到的返回值应当是一个可以兼容的类(比如Polynomial类的derivate()需要调用其中每个Term的derivate(),此时就应当让Term.derivate()返回一个Polynomial型的对象,再统一集中处理)。
细节实现
1、合并同类项优化
目前设计了一个较为高效的识别同类项方法。通过判断两个对象在x不同取值下的值来判定是否为同类项,比如x^3*cos(x)^2*cos(x)^-1与x^2*x*cos(x)^+1这两项在x取值相同时值明显相同。这种方法同样适用于更为复杂的情况。具体实现上目前有两种思路。一种是预先准备一组x的取值,然后对于每一个待合并的项都计算出一组对应结果。通过比对对应结果来判断是否可以合并;一种是在每次比对时随机生成x的值,然后比对结果。两种方法前者在效能上更优,可以在读入过程中生成每一个对象的特征值组;后者则更保险,因为随机生成的值不容易出现不匹配但却能兼容的错误判断(如x^3与x在x=1时值相等)。
2、模拟退火合并sin(x)^2+cos(x)^2
针对目前优化方案中贪心所导致的缺陷,可以引入模拟退火的方式来寻找最优解。具体实现方案如下:
(1)随机选择两项,判断是否可以合并
(2)如果可以合并,但长度增长,则按照当前的温度选择接受概率;否则进行合并。
(3)如果进行多次上述操作均无发生合并,则将结果返回
这样可以在一定程度上避免局部最优的情况发生。实现细节可能还需要进一步雕琢,但大致思路如上,希望能够抛砖引玉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号