
MySQL基本命令语法之select
MySQL基本命令语法之select
查询去重以及常数
在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT department_id
FROM employees;
针对于:
SELECT DISTINCT department_id,salary
FROM employees;
这里有两点需要注意:
- DISTINCT 需要放到所有列名的前面,如果写成
SELECT salary, DISTINCT department_id FROM employees会报错。 - DISTINCT 其实是对后面所有列名的组合进行去重,你能看到最后的结果是 74 条,因为这 74 个部门id不同,都有 salary 这个属性值。如果你想要看都有哪些不同的部门(department_id),只需要写
DISTINCT department_id即可,后面不需要再加其他的列名了。
查询常数
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。
你可能会问为什么我们还要对常数进行查询呢?
SQL 中的 SELECT 语法的确提供了这个功能,一般来说我们只从一个表中查询数据,通常不需要增加一个固定的常数列,但如果我们想整合不同的数据源,用常数列作为这个表的标记,就需要查询常数。
比如说,我们想对 employees 数据表中的员工姓名进行查询,同时增加一列字段corporation,这个字段固定值为“soberw”,可以这样写:
SELECT 'soberw' as corporation, last_name FROM employees;
空值与着重号
着重号
- 错误的
mysql> SELECT * FROM ORDER;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'ORDER' at line 1
- 正确的
mysql> SELECT * FROM `ORDER`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM `order`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
- 结论
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对``(着重号)引起来。
空值
- 所有运算符或列值遇到null值,运算的结果都为null
SELECT employee_id,salary,commission_pct,
12 * salary * (1 + commission_pct) "annual_sal"
FROM employees;
这里一定要注意,在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
运算符
算术运算符
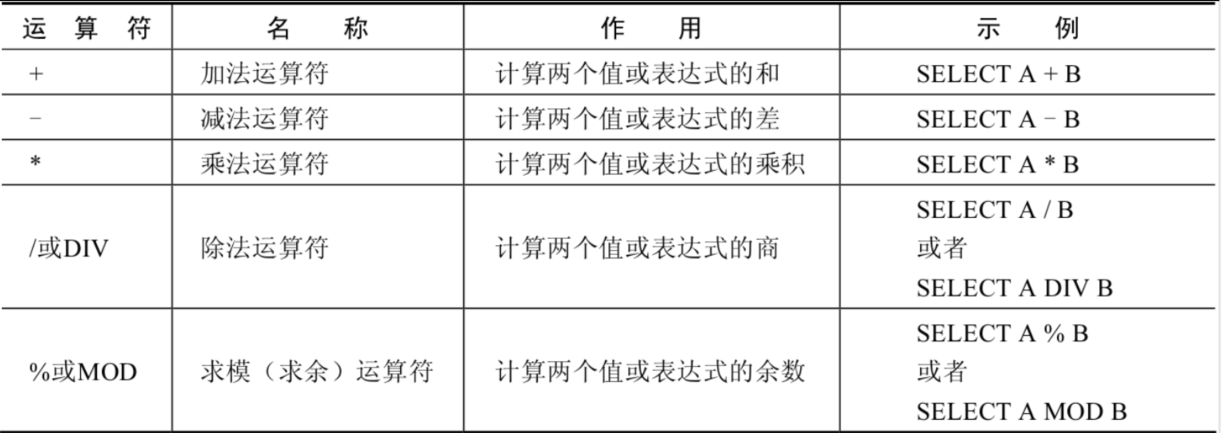
一个整数类型的值对整数进行加法和减法操作,结果还是一个整数;
一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数;
加法和减法的优先级相同,进行先加后减操作与进行先减后加操作的结果是一样的;
在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现)
一个数乘以整数1和除以整数1后仍得原数;
一个数乘以浮点数1和除以浮点数1后变成浮点数,数值与原数相等;
一个数除以整数后,不管是否能除尽,结果都为一个浮点数;
一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位;
乘法和除法的优先级相同,进行先乘后除操作与先除后乘操作,得出的结果相同。
在数学运算中,0不能用作除数,在MySQL中,一个数除以0为NULL。
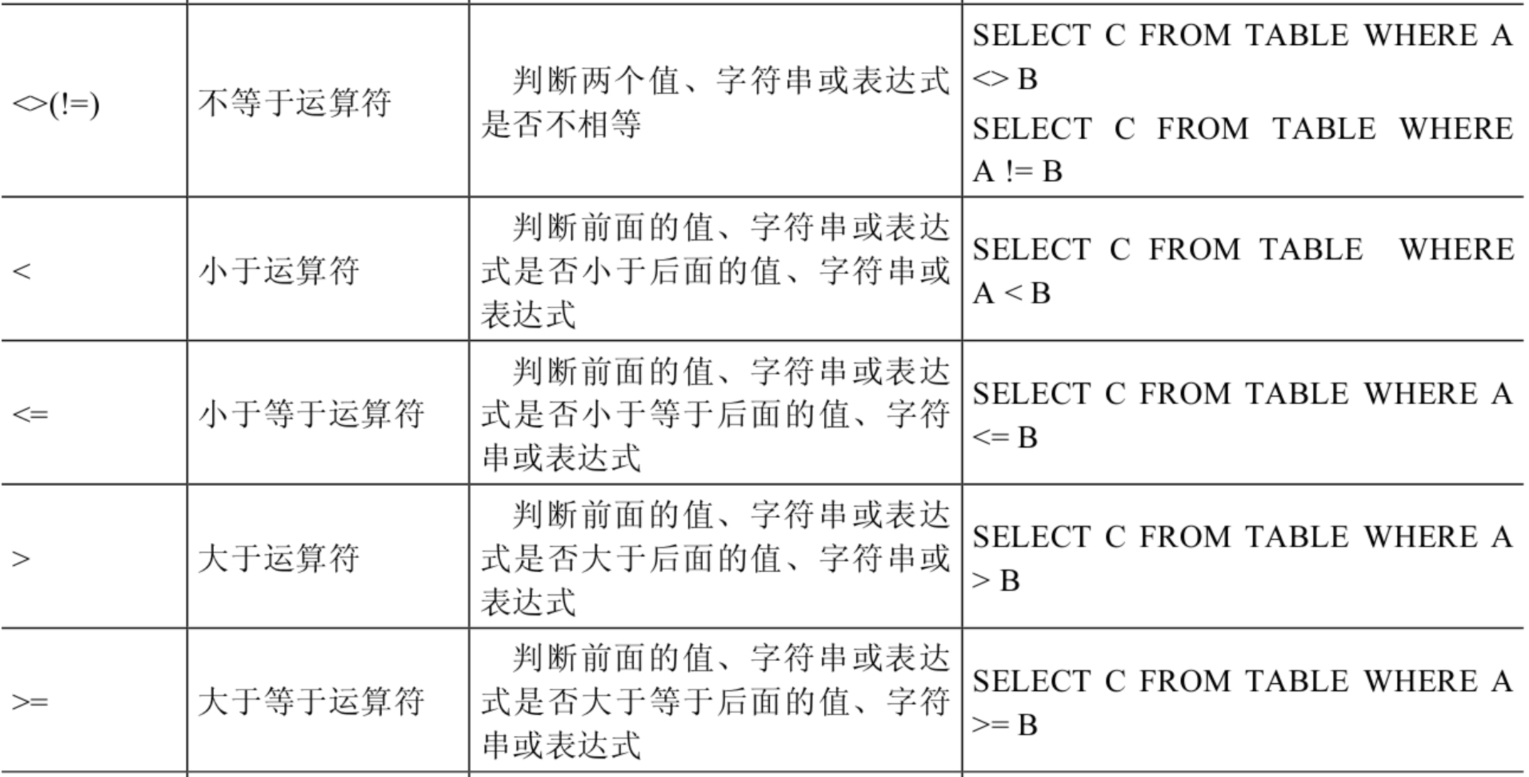
比较运算符
符号型
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。

1.等号运算符
-
等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回0。
-
在使用等号运算符时,遵循如下规则:
- 如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。
- 如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。
- 如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。
- 如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL。
-
对比:SQL中赋值符号使用 :=
mysql> SELECT 1 = 1, 1 = '1', 1 = 0, 'a' = 'a', (5 + 3) = (2 + 6), '' = NULL , NULL = NULL;
+-------+---------+-------+-----------+-------------------+-----------+-------------+
| 1 = 1 | 1 = '1' | 1 = 0 | 'a' = 'a' | (5 + 3) = (2 + 6) | '' = NULL | NULL = NULL |
+-------+---------+-------+-----------+-------------------+-----------+-------------+
| 1 | 1 | 0 | 1 | 1 | NULL | NULL |
+-------+---------+-------+-----------+-------------------+-----------+-------------+
1 row in set (0.00 sec)
mysql> SELECT 1 = 2, 0 = 'abc', 1 = 'abc' FROM dual;
+-------+-----------+-----------+
| 1 = 2 | 0 = 'abc' | 1 = 'abc' |
+-------+-----------+-----------+
| 0 | 1 | 0 |
+-------+-----------+-----------+
1 row in set, 2 warnings (0.00 sec)
#查询salary=10000,注意在Java中比较是==
SELECT employee_id,salary FROM employees WHERE salary = 10000;
2.安全等于运算符
安全等于运算符(<=>)与等于运算符(=)的作用是相似的,唯一的区别是‘<=>’可以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL时,其返回值为0,而不为NULL。
mysql> SELECT 1 <=> '1', 1 <=> 0, 'a' <=> 'a', (5 + 3) <=> (2 + 6), '' <=> NULL,NULL <=> NULL FROM dual;
+-----------+---------+-------------+---------------------+-------------+---------------+
| 1 <=> '1' | 1 <=> 0 | 'a' <=> 'a' | (5 + 3) <=> (2 + 6) | '' <=> NULL | NULL <=> NULL |
+-----------+---------+-------------+---------------------+-------------+---------------+
| 1 | 0 | 1 | 1 | 0 | 1 |
+-----------+---------+-------------+---------------------+-------------+---------------+
1 row in set (0.00 sec)
#查询commission_pct等于0.40
SELECT employee_id,commission_pct FROM employees WHERE commission_pct = 0.40;
SELECT employee_id,commission_pct FROM employees WHERE commission_pct <=> 0.40;
#如果把0.40改成 NULL 呢?
可以看到,使用安全等于运算符时,两边的操作数的值都为NULL时,返回的结果为1而不是NULL,其他返回结果与等于运算符相同。
3.不等于运算符
不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等,如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL。
SQL语句示例如下:
mysql> SELECT 1 <> 1, 1 != 2, 'a' != 'b', (3+4) <> (2+6), 'a' != NULL, NULL <> NULL;
+--------+--------+------------+----------------+-------------+--------------+
| 1 <> 1 | 1 != 2 | 'a' != 'b' | (3+4) <> (2+6) | 'a' != NULL | NULL <> NULL |
+--------+--------+------------+----------------+-------------+--------------+
| 0 | 1 | 1 | 1 | NULL | NULL |
+--------+--------+------------+----------------+-------------+--------------+
1 row in set (0.00 sec)
非符号型

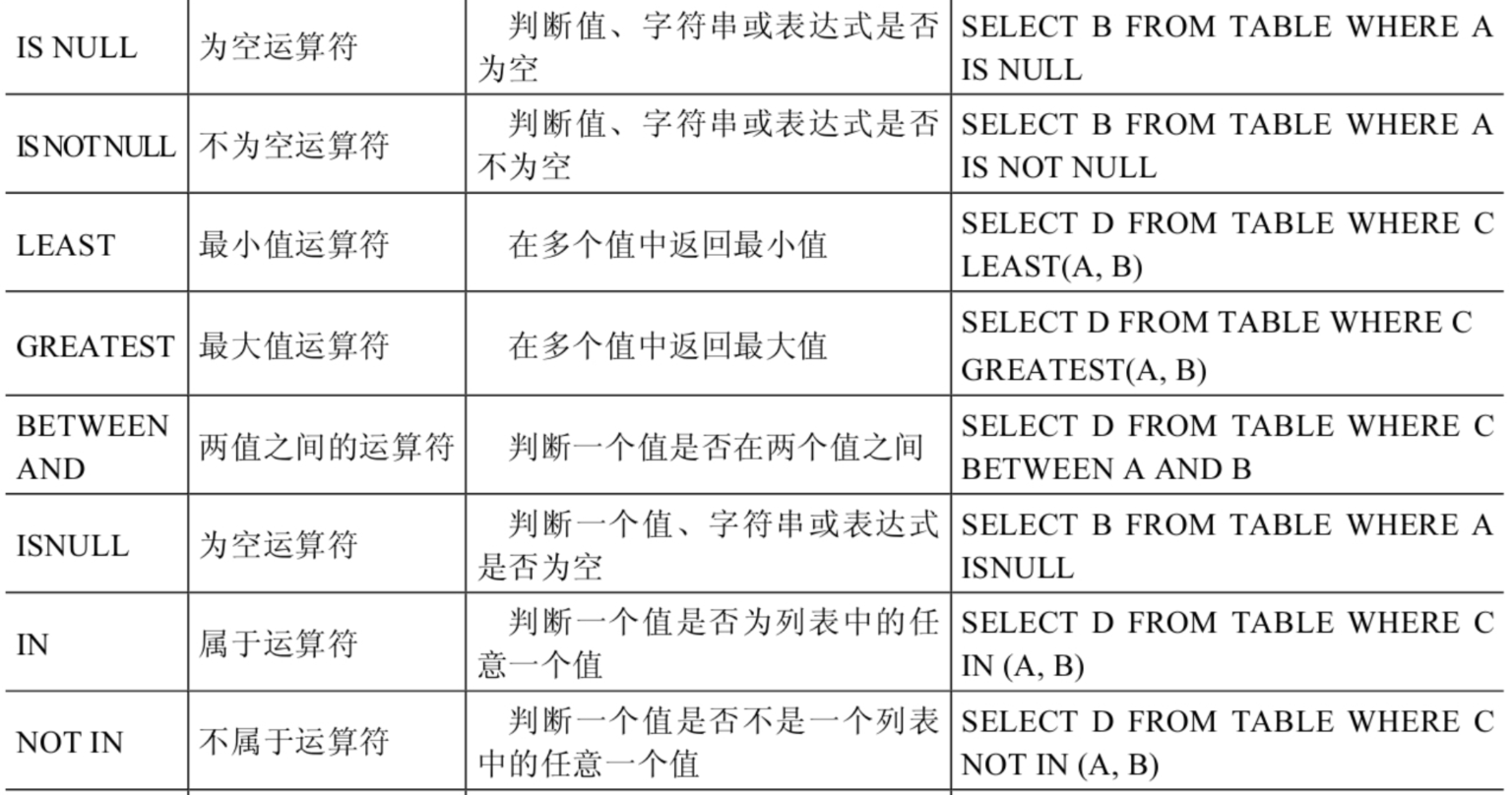

另外有
**ESCAPE**搭配使用LIKE时出现需要转义的情况
- 回避特殊符号的:使用转义符。例如:将[%]转为[ %]、[]转为[ ],然后再加上[ESCAPE‘$’]即可。
SELECT job_id
FROM jobs
WHERE job_id LIKE ‘IT\_%‘;
- 如果使用\表示转义,要省略ESCAPE。如果不是\,则要加上ESCAPE。
SELECT job_id
FROM jobs
WHERE job_id LIKE ‘IT$_%‘ escape ‘$‘;
逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。

1.逻辑非运算符
逻辑非(NOT或!)运算符表示当给定的值为0时返回1;当给定的值为非0值时返回0;当给定的值为NULL时,返回NULL。
mysql> SELECT NOT 1, NOT 0, NOT(1+1), NOT !1, NOT NULL;
+-------+-------+----------+--------+----------+
| NOT 1 | NOT 0 | NOT(1+1) | NOT !1 | NOT NULL |
+-------+-------+----------+--------+----------+
| 0 | 1 | 0 | 1 | NULL |
+-------+-------+----------+--------+----------+
1 row in set, 1 warning (0.00 sec)
2.逻辑与运算符
逻辑与(AND或&&)运算符是当给定的所有值均为非0值,并且都不为NULL时,返回1;当给定的一个值或者多个值为0时则返回0;否则返回NULL。
mysql> SELECT 1 AND -1, 0 AND 1, 0 AND NULL, 1 AND NULL;
+----------+---------+------------+------------+
| 1 AND -1 | 0 AND 1 | 0 AND NULL | 1 AND NULL |
+----------+---------+------------+------------+
| 1 | 0 | 0 | NULL |
+----------+---------+------------+------------+
1 row in set (0.00 sec)
3.逻辑或运算符
逻辑或(OR或||)运算符是当给定的值都不为NULL,并且任何一个值为非0值时,则返回1,否则返回0;当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;当两个值都为NULL时,返回NULL。
mysql> SELECT 1 OR -1, 1 OR 0, 1 OR NULL, 0 || NULL, NULL || NULL;
+---------+--------+-----------+-----------+--------------+
| 1 OR -1 | 1 OR 0 | 1 OR NULL | 0 || NULL | NULL || NULL |
+---------+--------+-----------+-----------+--------------+
| 1 | 1 | 1 | NULL | NULL |
+---------+--------+-----------+-----------+--------------+
1 row in set, 2 warnings (0.00 sec)
注意:
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
4.逻辑异或运算符
逻辑异或(XOR)运算符是当给定的值中任意一个值为NULL时,则返回NULL;如果两个非NULL的值都是0或者都不等于0时,则返回0;如果一个值为0,另一个值不为0时,则返回1。
mysql> SELECT 1 XOR -1, 1 XOR 0, 0 XOR 0, 1 XOR NULL, 1 XOR 1 XOR 1, 0 XOR 0 XOR 0;
+----------+---------+---------+------------+---------------+---------------+
| 1 XOR -1 | 1 XOR 0 | 0 XOR 0 | 1 XOR NULL | 1 XOR 1 XOR 1 | 0 XOR 0 XOR 0 |
+----------+---------+---------+------------+---------------+---------------+
| 0 | 1 | 0 | NULL | 1 | 0 |
+----------+---------+---------+------------+---------------+---------------+
1 row in set (0.00 sec)
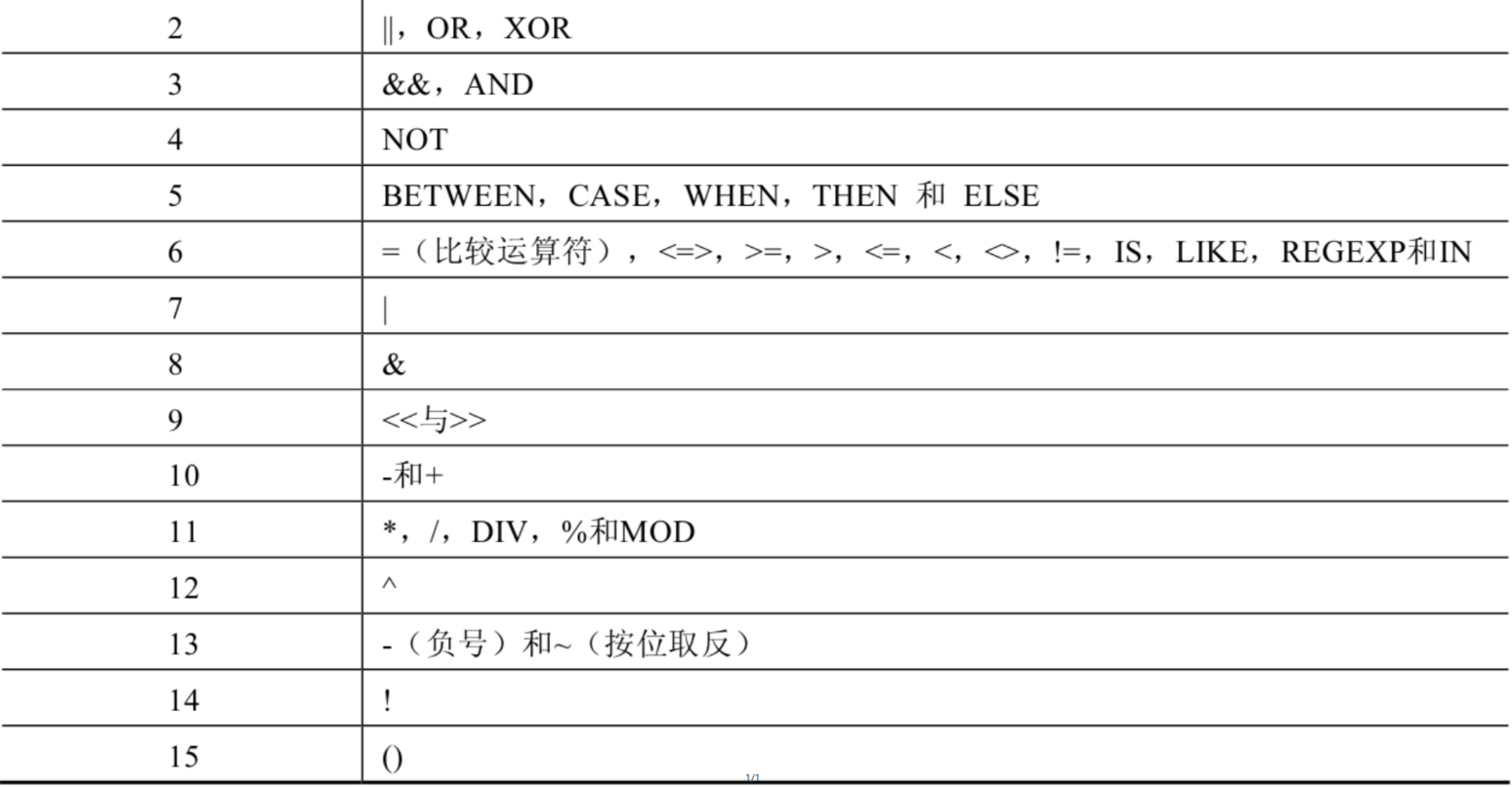
优先级

排序分页
排序
- 使用 ORDER BY 子句排序
- ASC(ascend): 升序
- DESC(descend):降序
- ORDER BY 子句在SELECT语句的结尾。
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date; # 单列排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary ...DESC; # 多列排序
- 可以使用不在SELECT列表中的列排序。
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
分页
-
分页原理
所谓分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件。
-
MySQL中使用 LIMIT 实现分页
-
格式:
LIMIT [位置偏移量,] 行数第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);第二个参数“行数”指示返回的记录条数。
-
举例
--前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
--第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
--第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT 4,3;”返回的结果相同。
- 分页显式公式**:(当前页数-1)每页条数,每页条数*
SELECT * FROM table
LIMIT(PageNo - 1)*PageSize,PageSize;
- 注意:LIMIT 子句必须放在整个SELECT语句的最后!
- 使用 LIMIT 的好处
约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。如果我们知道返回结果只有 1 条,就可以使用LIMIT 1,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
拓展
在不同的 DBMS 中使用的关键字可能不同。在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 关键字,而且需要放到 SELECT 语句的最后面。
- 如果是 SQL Server 和 Access,需要使用
TOP关键字,比如:
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
- 如果是 DB2,使用
FETCH FIRST 5 ROWS ONLY这样的关键字:
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
- 如果是 Oracle,你需要基于
ROWNUM来统计行数:
SELECT rownum,last_name,salary FROM employees WHERE rownum < 5 ORDER BY salary DESC;
需要说明的是,这条语句是先取出来前 5 条数据行,然后再按照 hp_max 从高到低的顺序进行排序。但这样产生的结果和上述方法的并不一样。我会在后面讲到子查询,你可以使用
SELECT rownum, last_name,salary
FROM (
SELECT last_name,salary
FROM employees
ORDER BY salary DESC)
WHERE rownum < 10;
得到与上述方法一致的结果。
多表查询
等值连接 vs 非等值连接
等值连接即为连接多个表中相同列的情况
非等值连接,顾名思义,一般是查询趋于某个范围的情况
区分重复的列名
- 多个表中有相同列时,必须在列名之前加上表名前缀。
- 在不同表中具有相同列名的列可以用
表名加以区分。
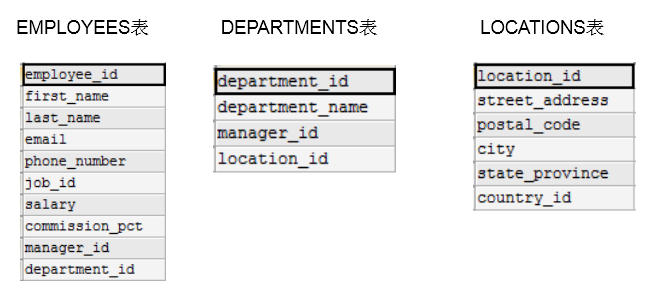
SELECT employees.last_name, departments.department_name,employees.department_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
表的别名
-
使用别名可以简化查询。
-
列名前使用表名前缀可以提高查询效率。
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
连接 n个表,至少需要n-1个连接条件。比如,连接三个表,至少需要两个连接条件。
自连接 vs 非自连接
当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两个表再进行内连接,外连接等查询。
简而言之,自连接本质还是同一张表,而非自连接才涉及到多张表
内连接 vs 外连接
-
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行 -
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。 -
如果是
左外连接,则连接条件中左边的表也称为主表,右边的表称为从表。如果是
右外连接,则连接条件中右边的表也称为主表,左边的表称为从表。另有
满外连接,包含了所有的情况,包含左表以及右表中所有情况行。
MySQL支持的连接语法(SQL99)
UNION[ALL]的使用
合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2
UNION操作符

UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符

UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
-
使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column, table2.column,table3.column FROM table1 JOIN table2 ON table1 和 table2 的连接条件 JOIN table3 ON table2 和 table3 的连接条件它的嵌套逻辑类似我们使用的 FOR 循环:
for t1 in table1: for t2 in table2: if condition1: for t3 in table3: if condition2: output t1 + t2 + t3 -
语法说明:
- 可以使用
ON子句指定额外的连接条件。 - 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
- 关键字
JOIN、INNER JOIN、CROSS JOIN的含义是一样的,都表示内连接
- 可以使用
内连接(INNER JOIN)
- 语法:
SELECT 字段列表
FROM A表
INNER JOIN B表
# 或者 JOIN
ON 关联条件
WHERE 等其他子句;
外连接(OUTER JOIN)
- 语法:
#实现查询结果是A (左外连接)
SELECT 字段列表
FROM A表
LEFT JOIN B表
# 或者 LEFT OUTER JOIN
ON 关联条件
WHERE 等其他子句;
左外连接(LEFT OUTER JOIN)
- 语法:
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表 # 或者 LEFT OUTER JOIN
ON 关联条件
WHERE 等其他子句;
右外连接(RIGHT OUTER JOIN)
- 语法:
#实现查询结果是B
SELECT 字段列表
FROM A表 RIGHT JOIN B表 # 或者RIGHT OUTER JOIN
ON 关联条件
WHERE 等其他子句;
满外连接(FULL OUTER JOIN)
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
需要注意的是,MySQL不支持FULL JOIN,但是可以用LEFT JOIN,UNION,RIGHT JOIN组合代替。
7种JOIN以及实现方式
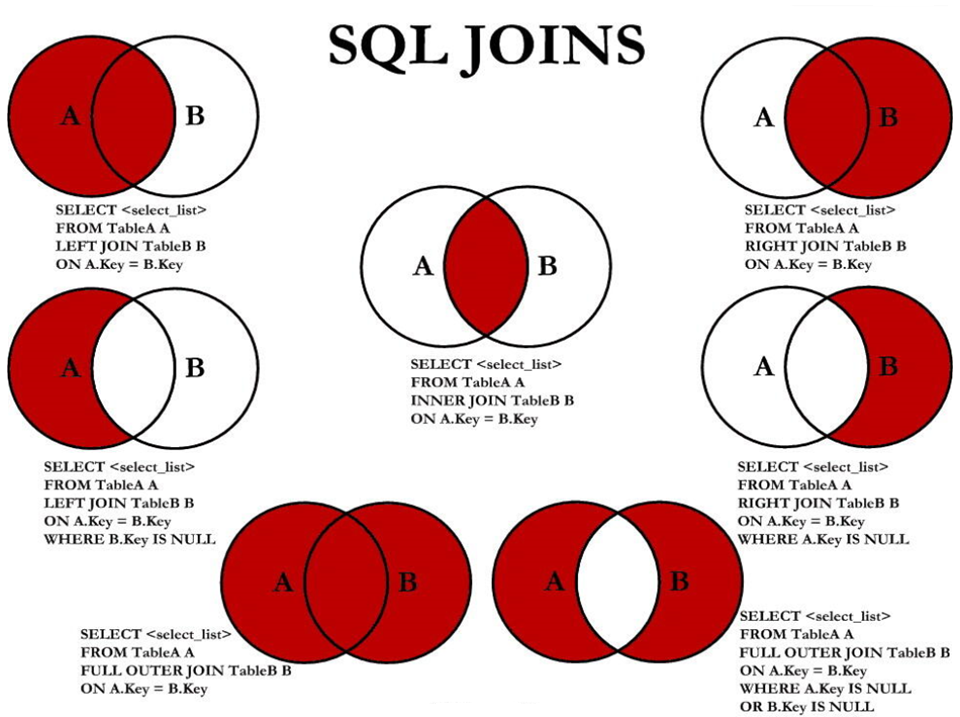
举例实现
#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#左下图:满外连接
# 左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
总结
- 左中图
#实现A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 右中图
#实现B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 左下图
#实现查询结果是A∪B
#用左外的A,union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
- 右下图
#实现A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
#使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
SQL99语法新特性(自然连接与USING连接)
自然连接(NATURAL JOIN)
SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中所有相同的字段,然后进行等值连接。
在SQL92标准中:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;
在 SQL99 中你可以写成:
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
USING连接
当我们进行连接的时候,SQL99还支持使用 USING 指定数据表里的同名字段进行等值连接。但是只能配合JOIN一起使用。比如:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id);
你能看出与自然连接 NATURAL JOIN 不同的是,USING 指定了具体的相同的字段名称,你需要在 USING 的括号 () 中填入要指定的同名字段。同时使用 JOIN...USING 可以简化 JOIN ON 的等值连接。它与下面的 SQL 查询结果是相同的:
SELECT employee_id,last_name,department_name
FROM employees e ,departments d
WHERE e.department_id = d.department_id;
MySQL不支持的语法格式
使用(+)创建连接
-
在 SQL92 中采用(+)代表从表所在的位置。即左或右外连接中,(+) 表示哪个是从表。
-
Oracle 对 SQL92 支持较好,而 MySQL 则不支持 SQL92 的外连接。
#左外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id = departments.department_id(+); #右外连接 SELECT last_name,department_name FROM employees ,departments WHERE employees.department_id(+) = departments.department_id; -
而且在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接。
子查询
子查询的基本使用
- 子查询的基本语法结构:

-
子查询(内查询)在主查询之前一次执行完成。
-
子查询的结果被主查询(外查询)使用 。
-
注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
注意:
在SELECT中,除了GROUP BY 和 LIMIT之外,其他位置都可以声明子查询!
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
另外需要注意:
from型的子查询:子查询是作为from的一部分,子查询要用()引起来,并且要给这个子查询取别名,
把它当成一张“临时的虚拟的表”来使用。
子查询的分类
分类方式1:
我们按内查询的结果返回一条还是多条记录,将子查询分为单行子查询、多行子查询。
-
单行子查询
![image-20220109205830241]()
-
多行子查询


分类方式2:
我们按内查询是否被执行多次,将子查询划分为相关(或关联)子查询和不相关(或非关联)子查询。
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做不相关子查询。
同样,如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为相关子查询。
单行子查询
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
多行子查询
- 也称为集合比较子查询
- 内查询返回多行
- 使用多行比较操作符
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。


说明:子查询中使用主查询中的列
EXISTS 与 NOT EXISTS关键字
- 关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
- NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
最后,子查询虽然好用,但是却不万能,不要过度依赖使用,若可以使用自连接。一般情况建议使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
|
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。
相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
说明:子查询中使用主查询中的列
EXISTS 与 NOT EXISTS关键字
- 关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
- NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
最后,子查询虽然好用,但是却不万能,不要过度依赖使用,若可以使用自连接。一般情况建议使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
本博客大部分内容摘抄自康师傅mysql笔记,附上他本人的教学视频,讲的非常好,建议大家观看点击这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号