

MySQL语法命令之约束篇
文章目录
1.约束概述
数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。
为了保证数据的完整性,SQL规范以约束的方式对**表数据进行额外的条件限制**。从以下四个方面考虑:
实体完整性(Entity Integrity):例如,同一个表中,不能存在两条完全相同无法区分的记录域完整性(Domain Integrity):例如:年龄范围0-120,性别范围“男/女”引用完整性(Referential Integrity):例如:员工所在部门,在部门表中要能找到这个部门用户自定义完整性(User-defined Integrity):例如:用户名唯一、密码不能为空等,本部门经理的工资不得高于本部门职工的平均工资的5倍。
简单来说,**约束**就是对表中字段的限制作用
1.1约束的分类
-
**根据约束数据列的限制,**约束可分为:
- 单列约束:每个约束只约束一列
- 多列约束:每个约束只约束一列
-
根据约束的作用范围,约束可分为:
-
列级约束:只能作用在一个列上,跟在列的定义后面
-
表级约束:可以作用在多个列上,不与列一起,而是单独定义
位置 支持的约束类型 是否可以起约束名 列级约束 列的后面 语法都支持,但外键没有效果 语法都支持,但外键没有效果 表级约束 所有列的下面 默认和非空不支持,其他支持 可以(主键没有效果)
-
- 根据约束起的作用,约束可分为:
- NOT NULL 非空约束,规定某个字段不能为空
- UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
- PRIMARY KEY 主键(非空且唯一)约束
- FOREIGN KEY 外键约束
- CHECK 检查约束
- DEFAULT 默认值约束
注意: MySQL不支持check约束,但可以使用check约束,而没有任何效果
1.2添加约束
- 有两种方式:
- create table 时添加
- alter table 时添加删除约束(尽量避免)
2.查看表中的约束
#information_schema数据库名(系统库)
#table_constraints表名称(专门存储各个表的约束)
SELECT
*
FROM
information_schema.table_constraints
WHERE
table_name = 'employees'; #表名字

在开始介绍约束之前,先来创建一个数据库,这里我命名为dbtest3,之后所有的操作都是在这个库下面:
create database if not exists dbtest3;
use dbtest3;
3. not null 非空约束
-
默认,所有的类型的值都可以是NULL,包括INT、FLOAT等数据类型
-
非空约束只能出现在表对象的列上,只能某个列单独限定非空,不能组合非空
-
一个表可以有很多列都分别限定了非空
-
空字符串’'不等于NULL,0也不等于NULL
3.1 在 create table 时创建
- 创建表test1
create table test1(
id int not null,
last_name varchar(15) not null,
email varchar(25),
salary decimal(10,2)
);
desc test1;

- 测试插入数据:
insert into test1(id,last_name,email,salary)
values (1,'Tom','123@qqw.com',2600);
insert into test1(id,last_name,salary)
values (2,'Joinney',1000);
# > 1048 - Column 'last_name' cannot be null 错误
insert into test1(id,last_name,email,salary)
values (2,null,'123@qqw.com',2600);
# > 1364 - Field 'last_name' doesn't have a default value 错误
insert into test1(id,email) values (2,'abc@wq.com');
#> 1048 - Column 'last_name' cannot be null 错误
update test1 set last_name = null where id = 1;
select * from test1;

3.2 在alter table 时添加约束
#> 1138 - Invalid use of NULL value
alter table test1 modify email varchar(25) not null;
-- 在修改为not null时要保证已经添加进去的值没有null值
-- 如果非要添加not null约束,先把null值字段修改数据
3.3 在alter table时删除约束
alter table test1 modify email varchar(25) null;
4. unique 唯一性约束
- 同一个表可以有多个唯一约束。
- 唯一约束可以是某一个列的值唯一,也可以多个列组合的值唯一。
- 唯一性约束允许列值为空。
- 在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
- MySQL会给唯一约束的列上默认创建一个唯一索引。
4.1 在create table 时添加约束
- 创建表test2:
create table test2(
id int unique, # 列级约束
last_name varchar(15),
email varchar(25),
salary decimal(10,2),
# 表级约束(这里指定了约束的名字)
constraint uk_test2_email unique(email)
);
SELECT
* FROM
information_schema.table_constraints
WHERE
table_name = 'test2';
-- 注意:在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同

- 添加数据:
insert into test2(id,last_name,email,salary)
values (1,'Tom','tom@162.com',4500);
select * from test2;

-- > 1062 - Duplicate entry '1' for key 'test2.id' 错误,id已经存在,不是唯一
insert into test2(id,last_name,email,salary)
values (1,'Tom1','tom1@162.com',4500);
-- 可以向声明为unique的字段添加null,在不指定为not null 的情况下
insert into test2(id,last_name,email,salary)
values (2,'Tom1',null,4500);
-- 可以多次添加null!!!!
insert into test2(id,last_name,email,salary)
values (3,'Tom2',null,4500);
select * from test2;

4.2 在alter table 时添加约束
-- 在修改为unique时要保证已经添加进去的值没有重复值
-- 如果非要添加唯一性约束,先把重复值字段修改
# 两种方式
-- 方式一:关键字add。此句会添加不成功,因为存在重复值
alter table test2
add constraint uk_test2_sal unique(salary);
-- 方式二:关键字modify。注意要加上字段的类型
alter table test2
modify last_name varchar(15) unique;
desc test2;

4.3 复合的唯一性约束
- 创建表user:
create table user(
id int,
`name` varchar(15),
`password` varchar(25),
# 表级约束
constraint uk_user_name_pwd unique(`name`,`password`)
);
# 表示用户名和密码组合不能重复
desc user;

- 添加数据:
insert into `user` values(1,'abc','123');
#也可以成功
insert into `user` values(2,'abc','123456');
select * from `user`;
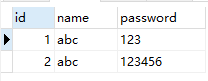
- 一个小案例帮助你更好理解复合唯一约束
#学生表
create table student(
sid int, #学号
sname varchar(20), #姓名
tel char(11) unique key, #电话
cardid char(18) unique key #身份证号
);
#课程表
create table course(
cid int, #课程编号
cname varchar(20) #课程名称
);
#选课表
create table student_course(
id int,
sid int, #学号
cid int, #课程编号
score int,
unique key(sid,cid) #复合唯一
-- 此处添加复合唯一的目的是:一个学生的某一学科只能有一个成绩
-- 因为是多对多的关系
);
insert into student values(1,'张三','13710011002','101223199012015623');#成功
insert into student values(2,'李四','13710011003','101223199012015624');#成功
insert into course values(1001,'Java'),(1002,'MySQL');#成功
select * from student;
select * from course;

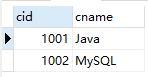
insert into student_course values
(1, 1, 1001, 89),
(2, 1, 1002, 90),
(3, 2, 1001, 88),
(4, 2, 1002, 56);#成功
select * from student_course;

-- > 1062 - Duplicate entry '2-1002' for key 'student_course.sid'失败,违反sid-cid的复合唯一
insert into student_course values (5,2,1002,67);
4.4 删除约束
- 添加唯一性约束的列上也会自动创建唯一索引。
- 删除唯一约束只能通过删除唯一索引的方式删除。
- 删除时需要指定唯一索引名,唯一索引名就和唯一约束名一样。
- 如果创建唯一约束时未指定名称,如果是单列,就默认和列名相同;如果是组合列,那么默认和()中排在第一个的列名相同。也可以自定义唯一性约束名。
# 查看表的索引
show index from test2; #表名
# 删除唯一性约束索引
alter table test2 drop index uk_test2_email;

5. primary key主键约束
- 主键约束相当于唯一约束+非空约束的组合,主键约束列不允许重复,也不允许出现空值。
-
一个表最多只能有一个主键约束,建立主键约束可以在列级别创建,也可以在表级别上创建。
-
主键约束对应着表中的一列或者多列(复合主键)
-
如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复。
-
MySQL的主键名总是PRIMARY,就算自己命名了主键约束名也没用。 -
当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引(能够根据主键查询的,就根据主键查询,效率更高)。如果删除主键约束了,主键约束对应的索引就自动删除了。
-
需要注意的一点是,不要修改主键字段的值。因为主键是数据记录的唯一标识,如果修改了主键的值,就有可能会破坏数据的完整性。
5.1 在create table 时添加约束
- 创建两张表test3 和test4:
- 分别通过
列级约束和表级约束创建
- 分别通过
create table test3(
id int primary key, #列级约束
-- > 1068 - Multiple primary key defined 错误 一张表中只能有一个主键
# last_name varchar(15) primary key,
last_name varchar(15),
salary decimal(10,2),
email varchar(25)
);
desc test3;
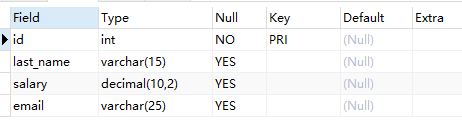
create table test4(
id int,
last_name varchar(15),
salary decimal(10,2),
email varchar(25),
# 表级约束
constraint pk_test4_id primary key(id) # 注意:没有必要命名,就算命名了还是primary key 因为主键唯一
);
desc test4;
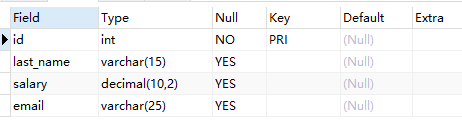
- 添加数据
insert into test4(id,last_name,salary,email)
values (1,'Tom',4500,'tom@qq.com');
-- > 1062 - Duplicate entry '1' for key 'test4.PRIMARY' 错误,主键是惟一的
insert into test4(id,last_name,salary,email)
values (1,'Tom',4500,'tom@qq.com');
-- > 1048 - Column 'id' cannot be null 错误 ,主键作为识别表的依据,不能为空
insert into test4(id,last_name,salary,email)
values (null,'Tom',4500,'tom@qq.com');
select * from test4;

复合型主键约束
#复合型主键约束
create table users(
id int,
`name` varchar(15),
`password` varchar(25),
primary key(name,password)
);
insert into users values(1,'Tom','abc');
insert into users values(1,'Tom1','abc');
select * from users;
-- > 1048 - Column 'name' cannot be null 错误,都不能为空
insert into users values(1,null,'abc');

5.2 在alter table 中添加约束
create table test5(
id int,
last_name varchar(15),
salary decimal(10,2),
email varchar(25)
);
desc test5;
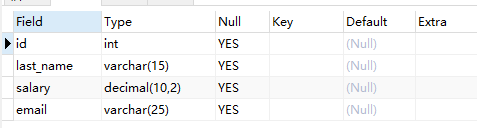
alter table test5 add primary key(id); #追加主键
5.3 删除主键约束(开发中不推荐使用,其实肯本不用)
alter table test5 drop primary key; # 不需要指定名字
6. auto_increment 自增列
(1)一个表最多只能有一个自增长列
(2)当需要产生唯一标识符或顺序值时,可设置自增长
(3)自增长列约束的列必须是键列(主键列,唯一键列)
(4)自增约束的列的数据类型必须是整数类型
(5)如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值。
6.1 在create table 时添加auto_increment
- 创建表test7:
create table test7(
id int primary key auto_increment, #正确,只能加在主键上(或者唯一键列)
last_name varchar(15) #auto_increment 错误 添加自增必须是整形数据
);
desc test7;

- 添加数据
#不指定,默认从1开始自增,每次增1 (开发中最常用)
insert into test7(last_name) values('Tom');
insert into test7(last_name) values('Tom');
insert into test7(last_name) values('Jony');
insert into test7(last_name) values('Red');
select * from test7;

#如果自增列指定了 0 和 null,会在当前最大值的基础上自增
insert into test7(id,last_name) values(0,'Joy');
insert into test7(id,last_name) values(null,'Xio');
select * from test7;

#如果自增列手动指定了具体值,直接赋值为具体值。
insert into test7(id,last_name) values(10,'Xio');
insert into test7(id,last_name) values(-10,'Xio');
#始终是最大值加1
insert into test7(last_name) values('Xio');
select * from test7;

6.2 在alter table 时添加(不常用)
create table test8(
id int primary key,
last_name varchar(15)
);
desc test8;

alter table test8 modify id int auto_increment;
6.3 在alter table 时删除(不常用)
alter table test8 modify id int;
6.4 MySQL 8.0新特性—自增变量的持久化
在MySQL 8.0之前,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1,这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。
下面通过案例来对比不同的版本中自增变量是否持久化。
在MySQL 5.7版本中,测试步骤如下:
创建的数据表中包含自增主键的id字段,语句如下:
CREATE TABLE test1(
id INT PRIMARY KEY AUTO_INCREMENT
);
插入4个空值,执行如下:
INSERT INTO test1
VALUES(0),(0),(0),(0);
查询数据表test1中的数据,结果如下:
mysql> SELECT * FROM test1;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
+----+
4 rows in set (0.00 sec)
删除id为4的记录,语句如下:
DELETE FROM test1 WHERE id = 4;
再次插入一个空值,语句如下:
INSERT INTO test1 VALUES(0);
查询此时数据表test1中的数据,结果如下:
mysql> SELECT * FROM test1;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 5 |
+----+
4 rows in set (0.00 sec)
从结果可以看出,虽然删除了id为4的记录,但是再次插入空值时,并没有重用被删除的4,而是分配了5。
删除id为5的记录,结果如下:
DELETE FROM test1 where id=5;
重启数据库,重新插入一个空值。
INSERT INTO test1 values(0);
再次查询数据表test1中的数据,结果如下:
mysql> SELECT * FROM test1;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
+----+
4 rows in set (0.00 sec)
从结果可以看出,新插入的0值分配的是4,按照重启前的操作逻辑,此处应该分配6。出现上述结果的主要原因是自增主键没有持久化。
在MySQL 5.7系统中,对于自增主键的分配规则,是由InnoDB数据字典内部一个计数器来决定的,而该计数器只在内存中维护,并不会持久化到磁盘中。当数据库重启时,该计数器会被初始化。
在MySQL 8.0版本中,上述测试步骤最后一步的结果如下:
mysql> SELECT * FROM test1;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 6 |
+----+
4 rows in set (0.00 sec)
从结果可以看出,自增变量已经持久化了。
MySQL 8.0将自增主键的计数器持久化到重做日志中。每次计数器发生改变,都会将其写入重做日志中。如果数据库重启,InnoDB会根据重做日志中的信息来初始化计数器的内存值。
7. foreign key 外键约束
作用:限定某个表的某个字段的引用完整性。
引入概念
-
主表和从表/父表和子表-
主表(父表):被引用的表,被参考的表
-
从表(子表):引用别人的表,参考别人的表
-
例如:员工表的员工所在部门这个字段的值要参考部门表:部门表是主表,员工表是从表。
-
例如:学生表、课程表、选课表:选课表的学生和课程要分别参考学生表和课程表,学生表和课程表是主表,选课表是从表。
(1)从表的外键列,必须引用/参考主表的主键或唯一约束的列
为什么?因为被依赖/被参考的值必须是唯一的
(2)在创建外键约束时,如果不给外键约束命名,默认名不是列名,而是自动产生一个外键名(例如 student_ibfk_1;),也可以指定外键约束名
(3)创建(CREATE)表时就指定外键约束的话,先创建主表,再创建从表
(4)删表时,先删从表(或先删除外键约束),再删除主表
(5)当主表的记录被从表参照时,主表的记录将不允许删除,如果要删除数据,需要先删除从表中依赖该记录的数据,然后才可以删除主表的数据
(6)在“从表”中指定外键约束,并且一个表可以建立多个外键约束
(7)从表的外键列与主表被参照的列名字可以不相同,但是数据类型必须一样,逻辑意义一致。如果类型不一样,创建子表时,就会出现错误“ERROR 1005 (HY000): Can’t create table’database.tablename’(errno: 150)”。
例如:都是表示部门编号,都是int类型。
(8)当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是外键的约束名。(根据外键查询效率很高)
(9)删除外键约束后,必须
手动删除对应的索引(10)主表和从表可以是同一个表,此时为
自连接 -
7.1 在create table 时添加
- 创建主表和从表:
# 先创建主表
create table dept1(
dept_id int,
dept_name varchar(15)
);
# 再创建从表
create table emp1(
emp_id int primary key auto_increment,
emp_name varchar(15),
department_id int,
#表级约束
constraint fk_emp1_dept_id foreign key(department_id) references dept1(dept_id)
);
-- > 1822 - Failed to add the foreign key constraint. Missing index for constraint 'fk_emp1_dept_id' in the referenced table 'dept1'
-- 错误:因为创建外键约束时,参考的主表的字段必须是唯一的(具有唯一性约束或者为主键)
#修改主表dept1关联字段为唯一
alter table dept1 add primary key (dept_id);
desc dept1;
#再次执行建立从表操作,成功!
desc emp1;


7.2 基本使用
# 向从表添加数据
-- > 1452 - Cannot add or update a child row: a foreign key constraint fails (`dbtest3`.`emp1`, CONSTRAINT `fk_emp1_dept_id` FOREIGN KEY (`department_id`) REFERENCES `dept1` (`dept_id`))
-- 失败:主表中与之相关联的字段没有此属性
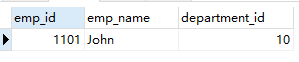
insert into emp1 values(1101,'John',10);
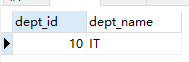
# 在主表dept1中添加数据(dept_id 为 10)
insert into dept1 values(10,'IT');
#再向从表添加数据(成功)
insert into emp1 values(1101,'John',10);
select * from dept1;
select * from emp1;
-- > 1451 - Cannot delete or update a parent row: a foreign key constraint fails (`dbtest3`.`emp1`, CONSTRAINT `fk_emp1_dept_id` FOREIGN KEY (`department_id`) REFERENCES `dept1` (`dept_id`))
# 错误:在删除主表数据之前,必须先删除从表中与之对应的数据
delete from dept1 where dept_id = 10;
# 错误:与上述原因形同
update dept1 set dept_id = 20 where dept_id = 10;
7.3 在alter table 时添加外键约束
# 先创建主表
create table dept2(
dept_id int primary key,
dept_name varchar(15)
);
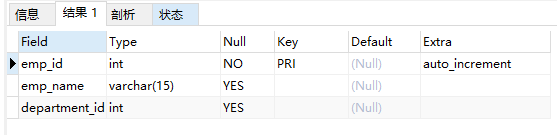
# 再创建从表 (此时未添加外键约束)
create table emp2(
emp_id int primary key auto_increment,
emp_name varchar(15),
department_id int
);
desc emp2;
# 添加外键约束
alter table emp2 add constraint fk_emp2_dept_id foreign key(department_id) references dept2(dept_id);
desc emp2;

7.4 约束等级
-
Cascade方式:在父表上update/delete记录时,同步update/delete掉子表的匹配记录 -
Set null方式:在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not null -
No action方式:如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作 -
Restrict方式:同no action, 都是立即检查外键约束 -
Set default方式(在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别
如果没有指定等级,就相当于Restrict方式。
对于外键约束,最好是采用: ON UPDATE CASCADE ON DELETE RESTRICT 的方式。
(1)演示1:on update cascade on delete set null
create table dept(
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) on update cascade on delete set null
#把修改操作设置为级联修改等级,把删除操作设置为set null等级
);
insert into dept values(1001,'教学部');
insert into dept values(1002, '财务部');
insert into dept values(1003, '咨询部');
insert into emp values(1,'张三',1001); #在添加这条记录时,要求部门表有1001部门
insert into emp values(2,'李四',1001);
insert into emp values(3,'王五',1002);
mysql> select * from dept;
mysql> select * from emp;
#修改主表成功,从表也跟着修改,修改了主表被引用的字段1002为1004,从表的引用字段就跟着修改为1004了
mysql> update dept set did = 1004 where did = 1002;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from dept;
+------+--------+
| did | dname |
+------+--------+
| 1001 | 教学部 |
| 1003 | 咨询部 |
| 1004 | 财务部 | #原来是1002,修改为1004
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | 1001 |
| 2 | 李四 | 1001 |
| 3 | 王五 | 1004 | #原来是1002,跟着修改为1004
+-----+-------+--------+
3 rows in set (0.00 sec)
#删除主表的记录成功,从表对应的字段的值被修改为null
mysql> delete from dept where did = 1001;
Query OK, 1 row affected (0.01 sec)
mysql> select * from dept;
+------+--------+
| did | dname | #记录1001部门被删除了
+------+--------+
| 1003 | 咨询部 |
| 1004 | 财务部 |
+------+--------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | NULL | #原来引用1001部门的员工,deptid字段变为null
| 2 | 李四 | NULL |
| 3 | 王五 | 1004 |
+-----+-------+--------+
3 rows in set (0.00 sec)
(2)演示2:on update set null on delete cascade
create table dept(
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) on update set null on delete cascade
#把修改操作设置为set null等级,把删除操作设置为级联删除等级
);
insert into dept values(1001,'教学部');
insert into dept values(1002, '财务部');
insert into dept values(1003, '咨询部');
insert into emp values(1,'张三',1001); #在添加这条记录时,要求部门表有1001部门
insert into emp values(2,'李四',1001);
insert into emp values(3,'王五',1002);
mysql> select * from dept;
+------+--------+
| did | dname |
+------+--------+
| 1001 | 教学部 |
| 1002 | 财务部 |
| 1003 | 咨询部 |
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | 1001 |
| 2 | 李四 | 1001 |
| 3 | 王五 | 1002 |
+-----+-------+--------+
3 rows in set (0.00 sec)
#修改主表,从表对应的字段设置为null
mysql> update dept set did = 1004 where did = 1002;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from dept;
+------+--------+
| did | dname |
+------+--------+
| 1001 | 教学部 |
| 1003 | 咨询部 |
| 1004 | 财务部 | #原来did是1002
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | 1001 |
| 2 | 李四 | 1001 |
| 3 | 王五 | NULL | #原来deptid是1002,因为部门表1002被修改了,1002没有对应的了,就设置为null
+-----+-------+--------+
3 rows in set (0.00 sec)
#删除主表的记录成功,主表的1001行被删除了,从表相应的记录也被删除了
mysql> delete from dept where did=1001;
Query OK, 1 row affected (0.00 sec)
mysql> select * from dept;
+------+--------+
| did | dname | #部门表中1001部门被删除
+------+--------+
| 1003 | 咨询部 |
| 1004 | 财务部 |
+------+--------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |#原来1001部门的员工也被删除了
+-----+-------+--------+
| 3 | 王五 | NULL |
+-----+-------+--------+
1 row in set (0.00 sec)
(3)演示:on update cascade on delete cascade
create table dept(
did int primary key, #部门编号
dname varchar(50) #部门名称
);
create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) on update cascade on delete cascade
#把修改操作设置为级联修改等级,把删除操作也设置为级联删除等级
);
insert into dept values(1001,'教学部');
insert into dept values(1002, '财务部');
insert into dept values(1003, '咨询部');
insert into emp values(1,'张三',1001); #在添加这条记录时,要求部门表有1001部门
insert into emp values(2,'李四',1001);
insert into emp values(3,'王五',1002);
mysql> select * from dept;
+------+--------+
| did | dname |
+------+--------+
| 1001 | 教学部 |
| 1002 | 财务部 |
| 1003 | 咨询部 |
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | 1001 |
| 2 | 李四 | 1001 |
| 3 | 王五 | 1002 |
+-----+-------+--------+
3 rows in set (0.00 sec)
#修改主表,从表对应的字段自动修改
mysql> update dept set did = 1004 where did = 1002;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from dept;
+------+--------+
| did | dname |
+------+--------+
| 1001 | 教学部 |
| 1003 | 咨询部 |
| 1004 | 财务部 | #部门1002修改为1004
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid |
+-----+-------+--------+
| 1 | 张三 | 1001 |
| 2 | 李四 | 1001 |
| 3 | 王五 | 1004 | #级联修改
+-----+-------+--------+
3 rows in set (0.00 sec)
#删除主表的记录成功,主表的1001行被删除了,从表相应的记录也被删除了
mysql> delete from dept where did=1001;
Query OK, 1 row affected (0.00 sec)
mysql> select * from dept;
+------+--------+
| did | dname | #1001部门被删除了
+------+--------+
| 1003 | 咨询部 |
| 1004 | 财务部 |
+------+--------+
2 rows in set (0.00 sec)
mysql> select * from emp;
+-----+-------+--------+
| eid | ename | deptid | #1001部门的员工也被删除了
+-----+-------+--------+
| 3 | 王五 | 1004 |
+-----+-------+--------+
1 row in set (0.00 sec)
7.5 删除外键约束
-- (1)第一步先查看约束名和删除外键约束
SELECT * FROM information_schema.table_constraints WHERE table_name = '表名称';#查看某个表的约束名
ALTER TABLE 从表名 DROP FOREIGN KEY 外键约束名;
-- (2)第二步查看索引名和删除索引。(注意,只能手动删除)
SHOW INDEX FROM 表名称; #查看某个表的索引名
ALTER TABLE 从表名 DROP INDEX 索引名;
7.6 开发场景
问题1:如果两个表之间有关系(一对一、一对多),比如:员工表和部门表(一对多),它们之间是否一定要建外键约束?
答:不是的
问题2:建和不建外键约束有什么区别?
答:建外键约束,你的操作(创建表、删除表、添加、修改、删除)会受到限制,从语法层面受到限制。例如:在员工表中不可能添加一个员工信息,它的部门的值在部门表中找不到。
不建外键约束,你的操作(创建表、删除表、添加、修改、删除)不受限制,要保证数据的引用完整性,只能依靠程序员的自觉,或者是在Java程序中进行限定。例如:在员工表中,可以添加一个员工的信息,它的部门指定为一个完全不存在的部门。
问题3:那么建和不建外键约束和查询有没有关系?
答:没有
在 MySQL 里,外键约束是有成本的,需要消耗系统资源。对于大并发的 SQL 操作,有可能会不适合。比如大型网站的中央数据库,可能会
因为外键约束的系统开销而变得非常慢。所以, MySQL 允许你不使用系统自带的外键约束,在应用层面完成检查数据一致性的逻辑。也就是说,即使你不用外键约束,也要想办法通过应用层面的附加逻辑,来实现外键约束的功能,确保数据的一致性。
8. check 约束(MySQL8.0 以上有效,5.*版本无效但不报错)
MySQL5.7 可以使用check约束,但check约束对数据验证没有任何作用。添加数据时,没有任何错误或警告
但是MySQL 8.0中可以使用check约束了。
create table test10(
id int,
last_name varchar(15),
salary decimal(10,2) check(salary > 2000)
);
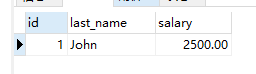
insert into test10 values(1,'John',2500);
-- > 3819 - Check constraint 'test10_chk_1' is violated. 错误:不满足标准
insert into test10 values(2,'soberw',1000);
select * from test10;
9. default 约束
给某个字段/某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。
9.1 在create table 时添加约束
create table test11(
id int,
last_name varchar(15),
salary decimal(10,2) default 2000
);
desc test11;

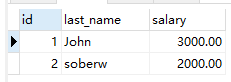
insert into test11 (id,last_name,salary) values(1,'John',3000);
insert into test11 (id,last_name) values(2,'soberw'); # 不指定salary值
select * from test11;
9.2 在 alter table 添加约束
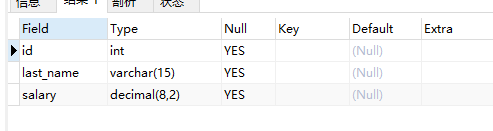
create table test12(
id int,
last_name varchar(15),
salary decimal(10,2)
);
desc test12;
alter table test12 modify salary decimal(8,2) default 2500;
desc test12;


9.3 在alter table删除约束
alter table test12 modify salary decimal(8,2);
desc test12;
10. 一些关于约束的面试题
- 面试1、为什么建表时,加 not null default ‘’ 或 default 0
答:不想让表中出现null值。
- 面试2、为什么不想要 null 的值
答: (1)不好比较。null是一种特殊值,比较时只能用专门的is null 和 is not null来比较。碰到运算符,通常返回null。
(2)效率不高。影响提高索引效果。因此,我们往往在建表时 not null default ‘’ 或 default 0
-
面试3、带AUTO_INCREMENT约束的字段值是从1开始的吗?
在MySQL中,默认AUTO_INCREMENT的初始值是1,每新增一条记录,字段值自动加1。设置自增属性(AUTO_INCREMENT)的时候,还可以指定第一条插入记录的自增字段的值,这样新插入的记录的自增字段值从初始值开始递增,如在表中插入第一条记录,同时指定id值为5,则以后插入的记录的id值就会从6开始往上增加。添加主键约束时,往往需要设置字段自动增加属性。 -
面试4、并不是每个表都可以任意选择存储引擎?
外键约束(FOREIGN KEY)不能跨引擎使用。MySQL支持多种存储引擎,每一个表都可以指定一个不同的存储引擎,需要注意的是:外键约束是用来保证数据的参照完整性的,如果表之间需要关联外 键,却指定了不同的存储引擎,那么这些表之间是不能创建外键约束的。所以说,存储引擎的选择也不完全是随意的。
本博客内容根据康师傅mysql视频整理所得,附上他本人的教学视频,讲的非常好,建议大家观看点击这里跳转

