正则表达式
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
-
创建一个匹配Email的正则表达式;
-
用该正则表达式去匹配用户的输入来判断是否合法
\d可以匹配一个数字
\w可以匹配一个字母或数字
\s匹配空白,空格或tab
.可以匹配任意字符
*可以匹配变长字符(包括0个)
+表示至少一个字符
?表示0个或1个字符
{n}表示n个字符
{n,m}表示n-m个字符
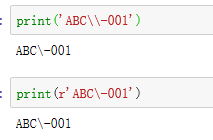
\转义字符,后面接特殊字符,忽略字符的特殊意义(\-,后面表示短横杠而不是减号)
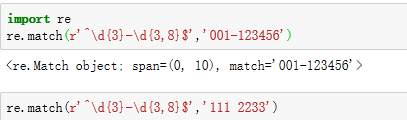
\d{3}\s+\d{3,8}
-
\d{3}表示匹配3个数字,例如'010'; -
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等; -
\d{3,8}表示3-8个数字,例如'1234567'。
要做更精确地匹配,可以用[]表示范围,比如:
-
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线; -
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等; -
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量; -
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
re模块
善用rrrrrrrrrrrrrrrrrrrrr
通过 re.amtch检测是否匹配,匹配则返回Match对象,否额返回None
test=input('用户输入字符串:') if re.match(r'^\d{3}-\d{3,8}$',test): print('OK') else: print('NO')
用户输入字符串:001-123456 OK
切分字符串
用正则表达式切分字符串比用固定的字符更灵活

分组
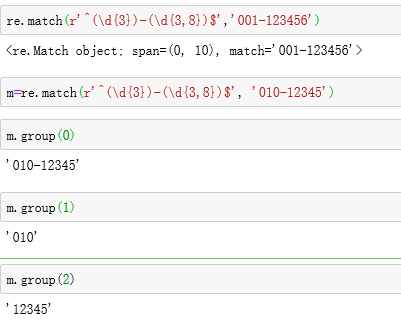
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('19', '05', '30')
贪婪匹配
正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
-
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
-
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
import re re_telephone=re.compile(r'^(\d{3})-(\d{3,8})$') re_telephone.match('010-12345').groups() Out:('010', '12345') re_telephone.match('010-8086').groups() Out:('010', '8086')
def is_valid_email(addr): re_email=re.compile(r'^(\w+)(.?)(\w+)@(gmail|microsoft).com$') if re_email.match(addr): return True else: return False assert is_valid_email('someone@gmail.com') assert is_valid_email('bill.gates@microsoft.com') assert not is_valid_email('bob#example.com') assert not is_valid_email('mr-bob@example.com') print('ok') ok
import re def name_of_email(addr): re_email = re.compile(r'^(<.+>\s)?(\w+)@(\w+).(com|org)$') m=re_email.match(addr) if m.group(1): return re.split('>|<',m.group(1))[1] else: return m.group(2) assert name_of_email('<Tom Paris> tom@voyager.org') == 'Tom Paris' assert name_of_email('tom@voyager.org') == 'tom' print('ok') ok
def name_of_email(addr): name=re.match(r'^<?(\w*\s*\w*)>?\s*(\w*)@(\w+\.org)$',addr) return name.group(1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号