Demo_通过JavaWeb完成文件下载
文件下载的实质就是文件拷贝,将文件从服务器端拷贝到浏览器端。所以文件下载需要IO技术将服务器端的文件使用InputStream读取到,在使用 ServletOutputStream写到response缓冲区中。
代码如下:

上述代码可以将图片从服务器端传输到浏览器,但浏览器直接解析图片显示在页面上,而不是提供下载,我们需要设置两个响应头,告知浏览器的类型和文件的打开方式。
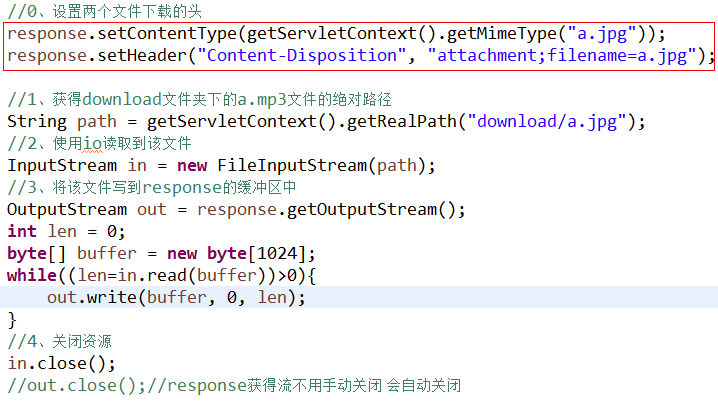
1)告知浏览器文件的类型:response.setContentType(文件的MIME类型);
2)告示浏览器文件的打开方式是下载:
response.setHeader("Content-Disposition","attachment;filename=文件名称");
代码如下:
但是,如果下载中文文件,页面在下载时会出现中文乱码或不能显示文件名的情况, 原因是不同的浏览器默认对下载文件的编码方式不同,ie是UTF-8编码方式,而火狐 浏览器是Base64编码方式。所里这里需要解决浏览器兼容性问题,解决浏览器兼容 性问题的首要任务是要辨别访问者是ie还是火狐(其他),通过Http请求体中的一 个属性可以辨别

解决乱码方法如下(不要记忆--了解): if (agent.contains("MSIE")) { // IE浏览器 filename = URLEncoder.encode(filename, "utf-8"); filename = filename.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filename = URLEncoder.encode(filename, "utf-8"); } 其中agent就是请求头User-Agent的值

关于Response的细节点需要注意:
① response 获得的流不需要手动关闭,Tomcat容器会帮助我们关闭
② getWriter 和 getOutputStream 不能同时调用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号