

【笔记】Dynamic Taint Analysis 动态污点分析
Dynamic Taint Analysis 动态污点分析
什么是动态污点分析?为什么要搞动态污点分析?
“污点”指的是什么?
DTA中的“污点”指代的是不可信的输入,比如用户输入、网络请求、文件数据等。比方说,如果把程序看作一个城市,外部输入的数据就像来自外界的货物。有些货物可能携带危险物质(恶意输入),为了防止它们进入关键的地方(系统资源),我们需要给这些外界输入打上一个标记(污点)。
如果程序对外部输入的数据处理不当,这些“污点”数据可能进入到系统的重要区域,进而造成安全问题,比如:
- 缓冲区溢出:恶意输入影响内存,执行攻击者控制的代码。
- SQL注入:不可信的数据被直接传入数据库查询,导致数据泄露或篡改。
“动态”指的又是什么?
“动态”指的是在程序实际运行时(即“动态”)追踪不可信数据的传播路径。相比静态分析(即在代码不运行的情况下分析代码可能的问题),动态污点分析是在程序运行过程中,实时追踪不可信数据的流动和影响。
例如,当你在一个网页上输入信息并点击提交,动态污点分析会监控你的输入如何在后台代码中流动,直到它被用在某个地方(如数据库查询或文件操作)。如果这些不可信的输入未经验证地影响了程序的关键操作(如执行系统命令或修改内存),就可能是攻击的起点。
DTA要应对什么问题?
DTA主要用于防止外部输入引发安全漏洞,常见的应用场景包括:
- 缓冲区溢出攻击:攻击者通过恶意输入,修改程序内存,使其执行恶意代码。
- 命令注入攻击:未经验证的用户输入被用于执行系统命令。
- SQL注入:不可信的输入被直接插入SQL查询,导致数据库遭受攻击。
比方说,一个网站可能会接受用户的文件上传或输入,如果黑客通过文件或输入向服务器注入恶意代码,DTA会监控这些输入的路径,防止这些不可信的数据引发危险操作。
简单来说:
DTA 就像一个监控系统,实时跟踪外部输入的流动,确保它不会污染(即“污点”)关键的操作或资源。当外部不可信输入没有被正确过滤或验证时,DTA 会警告程序,防止漏洞利用或恶意行为。
与网络流量分析的比较:
前几天在看网络层流量分析的内容嘛,已经被各种术语绕晕了,流量分析要处理的是恶意流量之类的玩意,DTA应对的也是恶意输入、异常数据相关的东西,这二者。。看起来似乎是同一回事啊?
因此还是需要区分一下这俩货的异同的:
两者的最终目标都是为了发现恶意行为并保护系统。DTA 试图保护应用程序和系统免受由不可信输入引发的攻击,而网络恶意流量检测则是为了防范恶意流量通过网络入侵系统。
两者都涉及处理和监控不可信数据。DTA 追踪来自外部的输入(如用户输入、文件、网络请求等)在程序中的传播,而网络恶意流量检测追踪的是通过网络传输的数据包,判断其中是否存在异常或攻击行为。
二者的不同之处主要在于:DTA 主要聚焦在程序内部,分析应用程序如何处理外部输入,防止数据在程序中未经验证地传播到敏感位置。网络恶意流量检测 则关注整个网络层面,分析网络流量的特征,检测如 DDoS 攻击、端口扫描、网络蠕虫等大规模网络攻击。
在使用场景上,DTA 更适合检测软件漏洞,如缓冲区溢出、命令注入等,尤其是在应用程序代码层面,它能帮助发现内部安全问题。网络恶意流量检测 则适用于网络安全,应对的是来自外部网络的恶意访问和攻击,如流量异常、端口扫描、DoS攻击等。
假设在分析一个网络攻击场景:
如果攻击是通过网络传输大量数据导致服务器瘫痪(比如 DDoS 攻击),那么这是网络层的问题,适合用网络恶意流量检测来发现和应对。
但如果攻击者通过某个网络接口输入了恶意数据(比如通过网页表单提交恶意代码,试图进行SQL注入),而程序内部没有过滤这些输入导致系统被攻破,这时DTA可以帮助发现攻击的输入点和传播路径。
一些综述内容:A Review of Researching on Dynamic Taint Analysis Technique
找到一些综述了解一下,例如这个:A Review of Researching on Dynamic Taint Analysis Technique(2018)
A Review of Researching on Dynamic Taint Analysis Technique | Atlantis Press (atlantis-press.com)
这篇的Abstract:污点分析技术是分析程序鲁棒性和漏洞挖掘的关键技术手段。通过标记敏感或不可信的数据,可以观察这些受污染数据在程序执行过程中的流动,进而判断标记的数据是否影响程序的关键节点。根据实现机制,污点分析可分为静态污点分析和动态污点分析。作为辅助技术,可以与模糊测试、符号执行等主流漏洞挖掘技术相结合,在测试用例构建和路径可行性分析中发挥很大作用。本文首先介绍了动态污点分析技术的基本概念。其次,它侧重于动态污点标记、传播和检测的过程。然后总结了污点分析中的主要缺 陷以及动态污点分析技术的应用现状。最后,与当前主流的污点分析工具进行了比较,探讨了污点分析技术的未来趋势。
动态污点分析的原理
污点分析结构框架如图 1 所示:源点通常由入口点或程序接受输入数据的外部函数调用组成。这些输入数据大致可以分为三类:文件输入、网络输入和外部设备输入。将机器学习与统计数据相结合,自动识别源点和汇点(the source and sink points)。第二种类型,如 DroidSafe ,是根据程序调用的 API 手动标注的。第三类认为外部数据不可信。根据直觉或经验,标记变量逐渐针对启发式进行优化。例如 PHP 漏洞分析工具 Aspis。
检测规则主要有 3 条:第一条使用 taint 数据作为跳转地址。EIP 指向的内存数据也是被污染的数据。一个是过度污染。将非因变量标记为污点,导致分析路径在传播过程中爆炸,消耗更多系统资源。另一种类型是污染不足。控制依赖关系的变量(隐式流)可能会在污点传播过程中被错误地标记为 non-tainted,从而导致漏报。
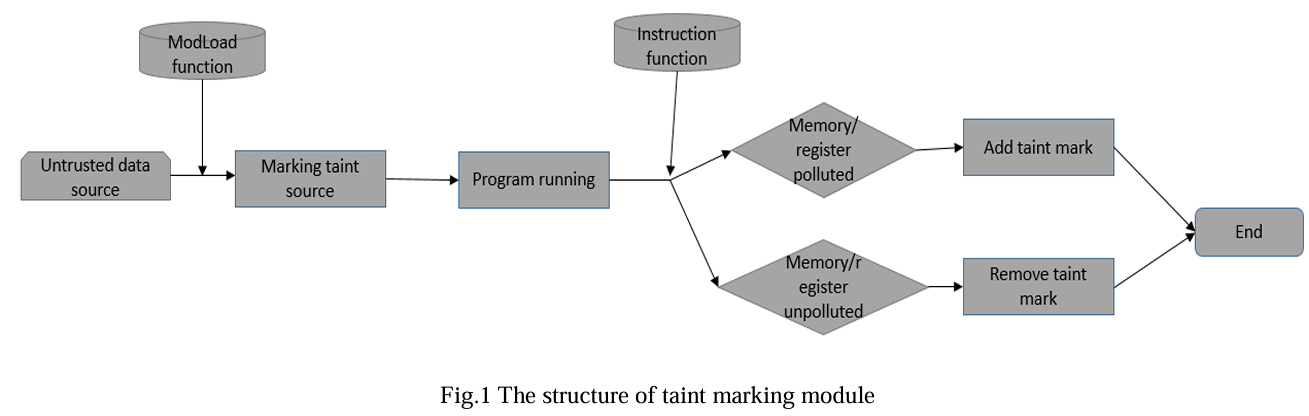
上图为污点标记模块的结构。
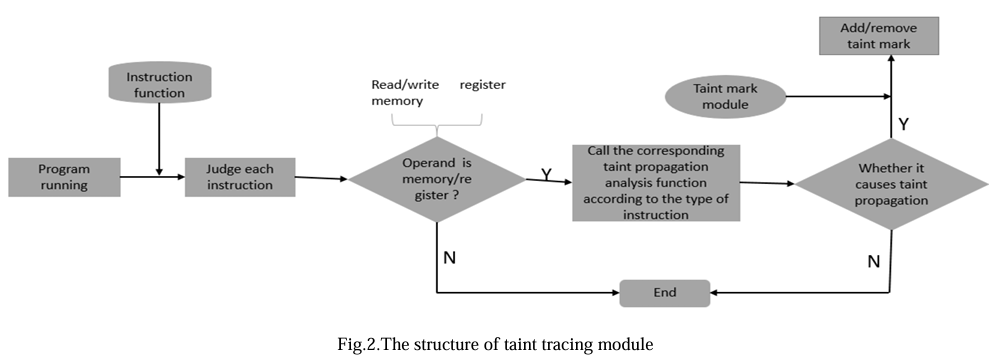
污点追踪模块的结构
缺陷和措施
A.动态隐式流标签范围的问题
准确的隐式流传播分析需要分析实际污点分析过程中每个分支控制条件是否传播了污点标记。这通常会导致过度污染。它会导致污点的大范围传播,最终产生路径爆炸,不仅消耗大量的系统资源。此外,用户获得的信息量是巨大的。难以筛选或标记不充分,导致分析不准确。
B.漏报和误报
C.难以平衡速度和准确性
污点分析技术根据分析粒度可分为细粒度动态污点分析技术和粗粒度动态污点分析技术。细粒度污点分析解决了数据流回溯问题,精度高。它主要用于检测易受攻击的攻击点。粗粒度污点分析速度快,占用空间小。
D. JIT(just in time)翻译执行中存在不支持浮点指令、执行效率低、污点损失等问题。(D. Problems such as not supporting the floating point instructions, low execution efficiency, and taint loss in JIT (just in time) translation execution. )
(Jinxin Ma等人在 Research on Taint Analysis Method Based on Execution Trace Offline Index提出了一种基于执行跟踪离线索引的污点分析方法。offline 索引可用于跳过与 taint 数据无关的指令。它可以以这种方式提高效率。同时,该文还提出了一种更完善的污点传播算法,该算法支持浮点指令的传播,提高了漏洞的检测能力。)
应用领域
Crash verifing 崩溃验证
使用污点检测来追踪输入数据如何影响程序执行,确保在处理用户输入时不会导致崩溃。
举例:在处理网络请求时,检测是否有污点数据流向关键函数,如果有,可能会触发程序崩溃。
Program vulnerability detection 程序漏洞检测
分析程序中输入数据的流向,识别可能导致缓冲区溢出或注入攻击的路径。
举例:如果用户输入直接被用于SQL查询,污点检测可以标识出这个路径并进行预警。
Information leak prevention 预防信息泄露
监测敏感信息(如密码)在程序中的传播路径,确保这些信息不会被意外泄露到不安全的地方。
举例:如果程序从数据库中获取用户信息并在日志中输出,污点检测可以提醒开发者该行为的风险。
Attacking feature generation and detection 攻击特征生成和检测
基于污点分析生成攻击模式的特征,并用于检测系统中的恶意活动。
举例:通过分析历史数据流,污点检测可以帮助识别和生成针对特定漏洞的攻击特征。
Vulnerability mining 漏洞挖掘
通过分析大量程序,找出常见的污点传播模式,以识别潜在的安全漏洞。
举例:分析开源软件项目,利用污点检测技术找出代码中可能存在的安全缺陷。
Malware detection 恶意软件检测
监测恶意软件的行为,通过分析污点数据来识别其对系统的影响。
举例:通过动态污点分析,检测到某个应用程序试图从用户输入中获取敏感信息并发送到外部服务器,从而识别恶意软件的存在。
未来发展趋势
综述认为污点分析技术的未来发展趋势将有以下几点:
A. Program performance analysis, defect location, and error detection 程序性能分析、缺陷定位和错误检测
B. Optimize the efficiency of dynamic taint analysis 优化动态污点分析的效率
(更高、更快、更强!)动态污点分析在性能上可能比较耗时,因此未来会着重于优化其效率,以便在实时检测中减少性能开销,使其更适用于大规模应用。
C. Hidden channel issues 隐藏的频道问题
隐藏频道问题指的是通过不易察觉的方式泄露信息(如电磁泄露或其他侧信道攻击)。未来的污点分析技术将致力于识别和防范这些隐秘的信息泄露方式。
D. Automation 自动化检测
将污点分析与自动化工具结合,以减少手动检查的工作量。使得安全检测过程更高效和可靠,帮助开发者在代码开发阶段及时发现安全漏洞。
下面来看看另外一篇涉及到DTA相关的技术
Neutaint: Efficient Dynamic Taint Analysis with Neural Networks
Neutaint:使用神经网络进行高效的动态污点分析(2020)
原文:Neutaint: Efficient Dynamic Taint Analysis with Neural Networks 1907.03756 (arxiv.org)
Abstract:
—Dynamic taint analysis (DTA) is widely used by various applications to track information flow during runtime execution. Existing DTA techniques use rule-based taint-propagation, which is neither accurate (i.e., high false positive rate) nor efficient (i.e., large runtime overhead). It is hard to specify taint rules for each operation while covering all corner cases correctly. More over, the overtaint and undertaint errors can accumulate during the propagation of taint information across multiple operations. Finally, rule-based propagation requires each operation to be inspected before applying the appropriate rules resulting in prohibitive performance overhead on large real-world applications.
动态污点分析 (DTA) 被各种应用程序广泛用于跟踪运行时执行期间的信息流。现有的 DTA 技术使用基于规则的污点传播,这既不准确(即高假阳性率)也不有效(即运行时间开销大)。很难为每个操作指定污点规则,同时正确覆盖所有极端情况。此外,在跨多个操作传播污点信息期间,overtaint 和 undertaint 错误可能会累积。最后,基于规则的传播要求在应用适当的规则之前检查每个操作,这会导致大型实际应用程序的性能开销过高。
In this work, we propose NEUTAINT, a novel end-to-end approach to track information flow using neural program embed dings. The neural program embeddings model the target’s programs computations taking place between taint sources and sinks, which automatically learns the information flow by observing a diverse set of execution traces. To perform lightweight and precise information flow analysis, we utilize saliency maps to reason about most influential sources for different sinks. NEUTAINT constructs two saliency maps, a popular machine learning approach to influence analysis, to summarize both coarse-grained and finegrained information flow in the neural program embeddings.
在这项工作中,我们提出了 NEUTAINT,这是一种使用神经程序嵌入叮当声跟踪信息流的新型端到端方法。神经程序嵌入对发生在污点源和接收器之间的目标程序计算进行建模,它通过观察一组不同的执行跟踪来自动学习信息流。为了执行轻量级和精确的信息流分析,我们利用显著性图来推断不同汇的最有影响力的来源。NEUTAINT 构建了两个显著性图,这是一种流行的影响分析机器学习方法,用于总结神经程序嵌入中的粗粒度和细粒度信息流。
We compare NEUTAINT with 3 state-of-the-art dynamic taint analysis tools. The evaluation results show that NEUTAINT can achieve 68% accuracy, on average, which is 10% improvement while reducing 40× runtime overhead over the second-best taint tool Libdft on 6 real world programs. NEUTAINT also achieves 61% more edge coverage when used for taint-guided fuzzing indicating the effectiveness of the identified influential bytes. We also evaluate NEUTAINT’s ability to detect real world software attacks. The results show that NEUTAINT can successfully detect different types of vulnerabilities including buffer/heap/integer overflows, division by zero, etc. Lastly, NEUTAINT can detect 98.7% of total flows, the highest among all taint analysis tools.
我们将 NEUTAINT 与 3 种最先进的动态污点分析工具进行了比较。评估结果表明,NEUTAINT 平均可以达到 68% 的准确率,这比 6 个实际程序上第二好的污点工具 Libdft 提高了 10%,同时减少了 40× 的运行时间开销。当用于污点引导模糊测试时,NEUTAINT 还实现了 61% 的边缘覆盖率,表明已识别的有影响力字节的有效性。我们还评估了 NEUTAINT 检测真实世界软件攻击的能力。结果表明,NEUTAINT 可以成功检测不同类型的漏洞,包括缓冲区/堆/整数溢出、被零除等。最后,NEUTAINT 可以检测到 98.7% 的总流量,是所有污点分析工具中最高的。
工作原理
Neutaint使用神经网络来学习程序的行为,而不是依赖于预定义的规则来传播污点标签。
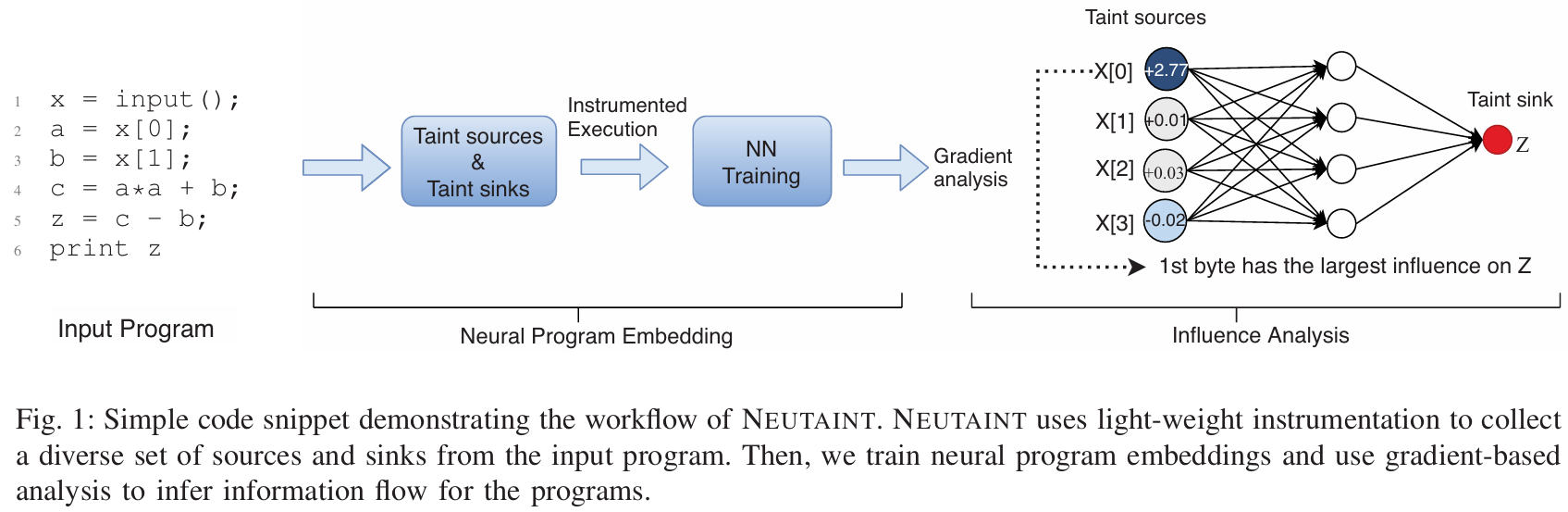
以上图为例,展示Neutaint的工作流程:假设污点源是x,从用户输入获取6个字节,污点接收器是变量 z。在这种情况下,基于传播的动态污点分析无法得出准确的信息流。由于第 4 行的变量 c 是由用户输入的前两个字节 a 和 b 计算的,因此 c 的污点值是 a 和 b。在第 5 行,z 是根据 c 和 b 计算的,因此 z 的污点值由 c 和 b 组成。第 4 行和第 5 行的分析都是准确的,但将传播规则组合在一起会放大误差。
该分析忽略了这样一个事实,即在第 5 行 z 实际上等于 a*a,并且仅受用户输入的第一个字节的影响。组合在动态污点分析中引入并放大了错误和运行时开销。
相反,N 使用端到端方法来构建用于信息流分析的神经程序嵌入。基于一些训练样本(即用户输入,z),N 从动态执行结果中学习神经程序,该结果保留了程序上下文——z 仅受 a 影响。如图 1 右侧所示,给定用户输入 x,N 计算变量 z 相对于 x 的梯度,并构建一个显著性图,该图表示 x 的每个字节如何影响 z 的敏感度。从显著性图中,我们发现第一个字节是影响 z 的输入中最关键的字节。图 1 显示了我们方法的高级概述。
(然后具体的工作原理各种公式balabala略...)
Data Collection(讲这篇论文怎么搞来的数据集)
要了解从污点源到污点汇的信息流,获得一个大型、多样化和有代表性的数据集至关重要。然而,与传统的机器学习任务(例如图像分类、自然语言处理、语音识别)不同,没有针对各种污点源和汇的标准数据集。有许多选项可用于收集训练数据集。收集此类数据集的自然解决方案是随机采样指定程序的污点源-接收器执行对。作为生成训练数据集的示例,我们可以从一个常见的污点源开始,随机翻转污点源中的字节,并记录相应的污点 sink 值。或者,我们可以使用一个简单的fuzzer来生成一组污点源,这些源触发不同的程序状态并记录污点 sinks 值。训练数据覆盖率会影响NEUTAINT可以跟踪的信息量。
我们可以使用更复杂的技术(如覆盖率引导、模糊测试、符号执行等)进一步提高信息流覆盖率。然而,在本文中,我们证明,即使使用简单的模糊测试器生成的训练数据,NEUTAINT也可以轻松胜过现有的DTA工具。
请注意,污点来源通常是用户输入、文件或用户隐私字符串,它们可以表示为字节序列。因此,我们可以轻松地将字节序列转换为 [0, 255] 范围内的有界数值向量。但是,污点接收器可以是程序中具有无限值的任意变量,例如指令指针寄存器、复杂的套接字结构或程序中的用户定义变量。这些任意变量很难建模为NN输出的统一表示,并且使NN难以收敛。为了解决这个问题,我们将这些无界变量归一化为不同应用程序的有界数据。例如,在污点导向模糊测试中,我们在分支条件中使用的一组变量上设置污点汇,并使用二进制数据对汇变量进行归一化(即,1表示采用分支,0 表示不采用分支)。NN输出的二进制表示可以保证模型的快速收敛。
Fuzzer是一种自动化测试工具,用于向程序输入随机或特制的数据,以发现潜在的漏洞或错误。通过这种方式,fuzzer可以生成多种输入,帮助触发不同的程序状态,从而检测安全问题或性能缺陷。
对比实验
跟现有的动态污点分析工具进行比较。介绍了现有的工具:
- Libdft:
- Libdft是一个动态污点分析引擎,基于Intel PIN框架构建。
- 它通过为每种指令类型预定义污点传播规则来进行动态分析。
- 这些规则通过PIN的分析API以外部函数的形式实现,然后动态地在运行时对二进制代码进行插桩。
- Libdft在执行每条指令时调用相应的外部函数来跟踪污点流。
- 它仅支持x86架构,且由于需要对每条指令进行处理,因此运行时开销较大。
- Triton:
- Triton是一个支持动态污点分析和符号执行的平台。
- 它同样使用Intel PIN来监控污点流,并有一套预定义的污点传播规则。
- Triton提供了Python绑定,允许用户编写脚本来执行定制的分析任务。
- 但是,Python绑定的功能有限,可能无法捕获PIN的全部功能,且可能引起较大的运行时开销。
- Triton也主要支持x86架构。
- DFSan:
- DFSan(DataFlowSanitizer)是由Clang提供的数据流分析框架。
- 它包括编译时插桩模块和运行时动态库,用于跟踪x86-64架构上的污点流。
- 用户只需要使用DFSan的公共API定义污点源和汇。
- DFSan基于LLVM IR指令而不是特定于架构的汇编指令来依赖预定义的污点传播规则,因此在编译时将污点跟踪功能插入程序。
- 相比其他基于PIN的工具,DFSan的运行时开销更小。
- 但是,DFSan无法运行在依赖外部共享库的程序上,因为这些动态共享库在编译时不能被插桩。
这仨工具都是基于规则的动态污点分析工具,它们并没有使用神经网络或其他机器学习技术。这些工具通过在程序执行过程中动态地插桩和跟踪污点标签来实现动态污点分析,但可能会因为复杂的污点传播规则和运行时开销而受到影响。
(然后讲实验环境)环境设置。我们所有的测量都是在 ubuntu 16.04 系统上进行的,该系统配备 Intel Xeon E5-2623 v4@2.60GHz CPU、Nvidia GTX 1080 Ti GPU 和 256 GB RAM。我们在 Keras-2.1.4 [6] 中实现 N,并使用 Tensorflow-1.8.0 [7] 作为后端。
然后是:
B. 热点字节准确性 (Is NEUTAINT more accurate at finding hot bytes?)
- 热点字节定义:定义了能够显著影响程序行为的输入字节为热点字节。
热点字节是指在输入数据中,那些对程序行为有显著影响的字节。这些字节通常位于输入数据的关键位置,如文件格式的头部或特定的控制信息。在动态污点分析中,找到这些热点字节对于理解输入数据如何影响程序行为至关重要,特别是在安全测试和漏洞分析中。
- 基准测试数据:介绍了如何获取和分析文件格式,以获得用于评估的热点字节的基准数据。使用Neutaint和其他动态污点分析工具处理相同的输入数据集,并记录每个工具识别的热点字节。
- 结果:展示了Neutaint在识别热点字节方面的准确性,并与其它工具进行了比较。
C. 运行时开销 (What is the runtime overhead of NEUTAINT?)
- 开销测试:测量了Neutaint和其它三种动态污点分析工具处理所有输入数据集所需的总时间。
- 结果:比较了Neutaint与其它工具在运行时开销方面的表现,并讨论了Neutaint的效率。
D. 漏洞分析 (Can NEUTAINT detect vulnerabilities in real-world programs?)
- 漏洞定义:选择了一些已知的、公开的软件漏洞作为案例研究,以评估Neutaint在实际应用中的表现。
- 结果:展示了Neutaint是否能够成功地从源头跟踪到汇点,从而发现漏洞。
E. 污点引导的模糊测试 (Application on Taint-Guided Fuzzing)
- 模糊测试实现:构建了一个模糊测试后端,并使用相同的变异算法来评估不同前端工具的性能。
- 结果:比较了Neutaint和其他工具在引导模糊测试时的代码覆盖率。
F. 模型选择 (How does NEUTAINT perform with different machine learning models?)
- 模型比较:比较了不同的机器学习模型,如逻辑回归、支持向量机等,与神经网络的性能。
- 结果:展示了神经网络模型在热点字节准确性方面的优势。
G. 信息丢失 (What kinds of flows are missed by NEUTAINT?)
- 信息流定义:定义了信息流,并讨论了如何通过静态分析和手动检查来估计总的信息流数量。
- 结果:评估了Neutaint在信息流检测方面的完整性,并与其他工具进行了比较。
最后的Conclusion:"我们提出了一种使用神经程序嵌入进行污点分析的新方法 N。我们的神经程序直接从污点源学习信息流到污点汇。我们使用显著性图来分析神经程序中的信息流。为了评估 N 的准确性、开销和应用效用,我们与三种最先进的动态污点分析工具进行了比较。结果表明,与第二好的动态污点分析工具 Libdft 相比,N 的准确率平均提高了 10%,运行时间开销减少了 40 倍。N 还可以成功地跟踪漏洞利用中从 source 到 sink 的信息。我们通过一种流行的污点应用程序 —— 模糊测试来进一步评估 N。污点引导的模糊测试结果表明,与最先进的动态污点分析工具相比,N 的边缘覆盖率平均高出 61%。"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号