


基于yolov5及yolov5-lite的视觉识别模型训练
记录一下学习经历,先从yolov5开始探索训练和检测的基本流程,然后尝试使用更精简的yolov5-lite。
Yolov5
1.环境配置
Anaconda:
简单来说,Anaconda和Python之间的关系就像是一个加强版的套装和它的基本组件的关系。Python是一种编程语言,而Anaconda则是一个包含了Python、多个常用数据科学和机器学习库以及一个名为conda的环境管理工具的发行版。
那么,为什么我们要用Anaconda而不是直接用Python呢?这主要是因为Anaconda能帮我们省时省心。首先,安装Anaconda就意味着一次性安装了Python和很多常用的数据科学库,这样我们就不需要一个个去安装这些库了。其次,conda这个环境管理工具能帮我们管理不同版本的Python和库,还能隔离不同项目的环境,避免库之间的冲突。
对于搞深度学习的人来说,Anaconda更是一个利器。它包含了大量与深度学习相关的库,比如TensorFlow、PyTorch等,这些库能帮助我们更方便地进行深度学习模型的训练和推理。而且,通过conda,我们可以很容易地创建和管理不同项目的环境,确保每个项目都有它所需要的库和版本。
Anaconda就像一个全能的数据科学工具箱,而Python则是这个工具箱中的一把基础工具。搞深度学习用Anaconda,就像是用一套完整的工具套装来完成工作,既方便又高效。
直接在清华大学开源镜像站上下吧, Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror,我下载是Anaconda3-2024.02-1-Windows-x86_64.exe
pycharm
yolov5框架:https://github.com/ultralytics/yolov5,或通过项目目录预览 - yolov5 - GitCode下载,将yolov5框架下载下来后,放到平时存放项目的位置。
yolov5-lite框架(替代):ppogg/YOLOv5-Lite: 🍅🍅🍅YOLOv5-Lite: Evolved from yolov5 and the size of model is only 900+kb (int8) and 1.7M (fp16). Reach 15 FPS on the Raspberry Pi 4B~ (github.com),也可以选用这个轻量版yolov5框架,这个比较适合在树莓派上用。
Pycharm配置Anaconda环境
参考了这篇文章Pycharm配置Anaconda环境的详细图文教程_python_脚本之家 (jb51.net)
python version选择anaconda安装位置下的python.exe。
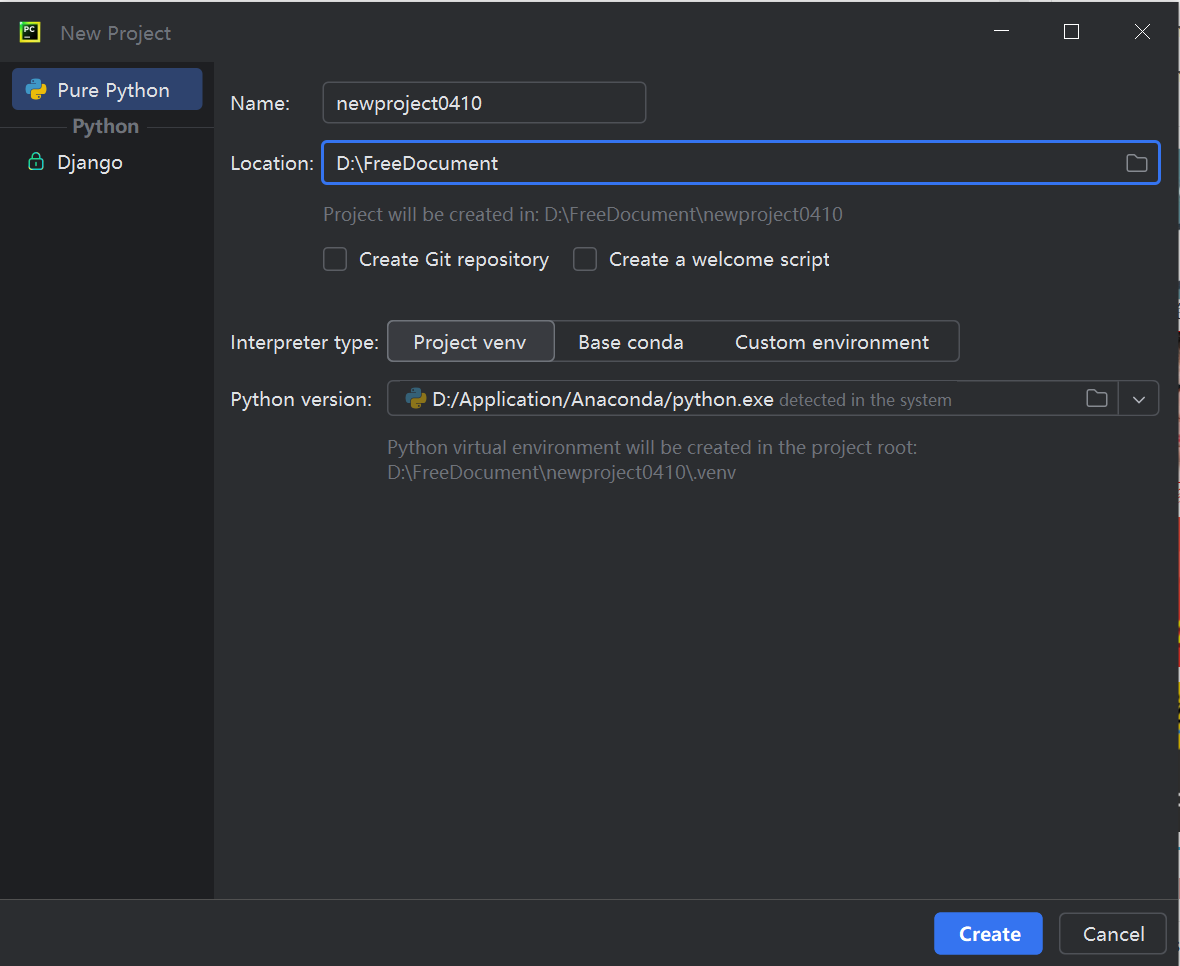
进入Settings----Project :pythonProject---Python Interpreter,然后选择Conda Environment,
找到anaconda安装位置,选择Anaconda\Scripts\conda.exe然后点Load Environments,然后点OK就行了(这新版本的pycharm的设置界面变得真大啊)
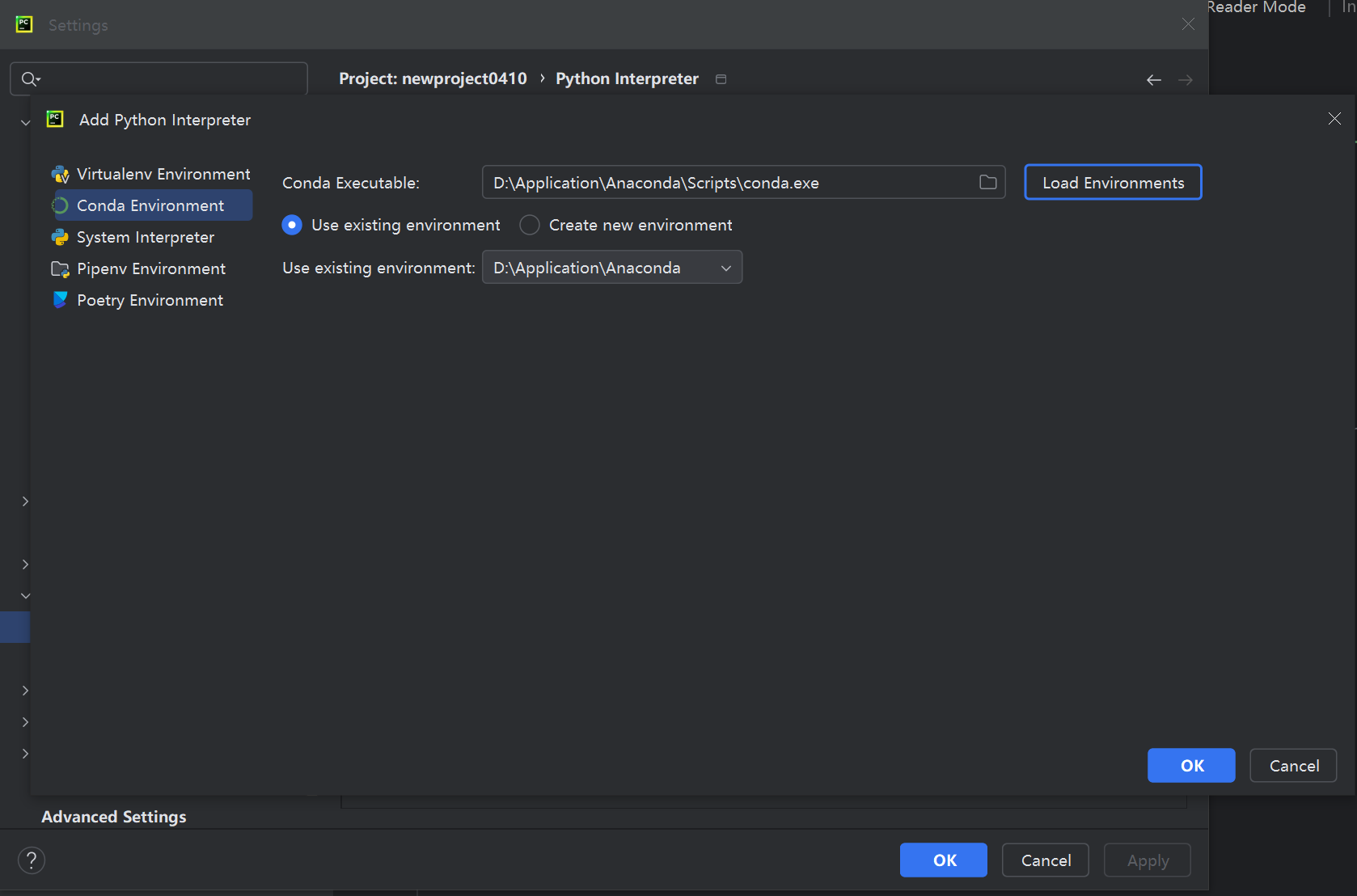
配置完成后可以看到python interpreter下多了许多包,表示在该环境下创建的工程就可以使用anaconda中已有的库了。

电脑搜索打开Anaconda prompt(其实就相当于anaconda版本的cmd命令行),cd到yolov5解压后所在的文件夹
(例如我把框架放到D盘去了,我需要先输入D:切换到D盘,然后cd D:FreeDocument\yolov5-master切换到这个文件夹里边去)
接下来读取yolov5框架下的requirement.txt文件,把需要的依赖都给弄下来
pip install -r requirements.txt
(一个小小的窍门,如果pip安装失败了,不妨尝试切换成国内镜像源再试试:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/)
2.手动制作训练集
标注数据要用到labelme这个东西。
Labelme是一个开源的图像标注工具,由麻省理工学院的计算机科学和人工智能实验室(CSAIL)开发。它主要用于创建计算机视觉和机器学习应用所需的标记数据集。LabelMe让用户可以在图片上标注对象和区域,为机器学习模型提供训练数据。它支持多种标注类型,如矩形框、多边形和线条等。它是用 Python 编写的,并使用 Qt 作为其图形界面。
下载labelme:https://github.com/wkentaro/labelme
把下载来的labelme解压到一个地方,然后在anaconda prompt里cd到labelme的文件夹,并依次执行:
conda create --name=labelme python=3
conda activate labelme
pip install labelme然后输入labelme打开labelme的GUI。
以后再打开labelme时也只需依次输入conda activate labelme、labelme即可。

接下来开始给提前准备好的图片做标注,用法很简单,使用正方形框选即可(我想要标记的东西是人,命名为person),然后保存,保存下来的标记文件为.json格式(后面要将.json格式转化成.txt格式)。
我们需要标注多少图片呢?这点我也不清楚,一般情况下投入的图片数量最好是几百张起步,最好在网上找现成的标记好的数据集。
但是从学习的角度来看,我标注了几十张图差不多就能识别出来了(没找着现成的数据集,只能手动标了),虽然精度比较抽象,但起码了解到这个流程就够了。

以其中一个图像标签为例,如train00016.jpg的标签被命名为train00016.json,打开json可见:
{
"version": "5.4.1",
"flags": {},
"shapes": [
{
"label": "person",
"points": [
[
6.413043478260885,
56.253623188405825
],
[
616.3150766849584,
426.0
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {},
"mask": null
},
{
"label": "person",
"points": [
[
364.3840579710145,
56.615942028985536
],
[
591.5579710144926,
409.15217391304344
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {},
"mask": null
},
{
"label": "words",
"points": [
[
240.1086956521739,
361.32608695652175
],
[
379.2391304347826,
383.0652173913043
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {},
"mask": null
}
],
"imagePath": "00016.jpg",
"imageData": ......(一大堆字符)
}我们需要将这个标签转化成.txt的形式,标签里的数据也要转化成不同的表现形式:
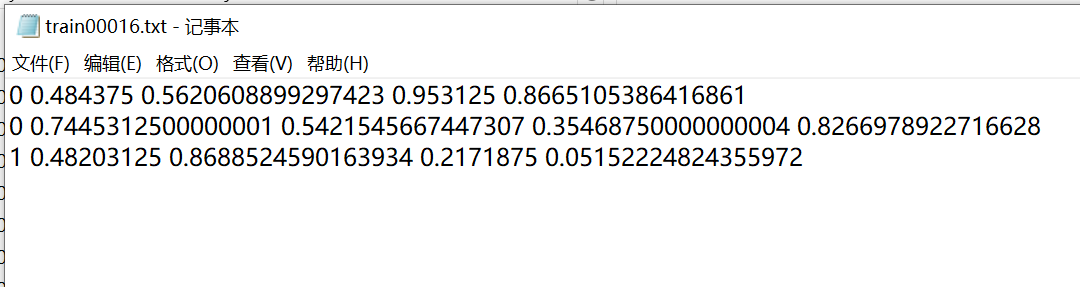
当我们标记了足够多的.json标签后,可以用如下代码将它们批量转化成.txt格式了。
import json
import os
name2id = {'person':0,'words':1}
'''标签名称,我只设置了两个标签person和words,可以按个人需求修改'''
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'C:\\存放txt的\\绝对路径' + json_name[0:-5] + '.txt'
#存放txt的绝对路径,注意是双斜线
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312',errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'C:\\存放json的\\文件夹\\的绝对\\路径'
#存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)
以上代码和接下来的不少内容参考了【Yolov5】1.认真总结6000字Yolov5保姆级教程(2022.06.28全新版本v6.1)_yolov5教程-CSDN博客,就是参照着这个佬的流程一步一步做出来的。
标签和图片都已经就位了:


3.Yolov5配置
打开yolov5-master的文件夹,在yolov5-master的根目录下创建一个新文件夹,文件夹的名字可以自定,如我打算将其命名为xunlianji(训练集).
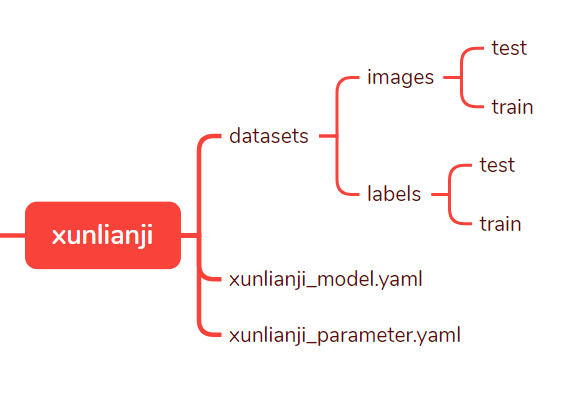
下边那俩先不管,先按如上所示在xunlianji里创建datasets文件夹和里边的文件夹,接下来,将.jpg图片文件扔进datasets\images\train,将转化后的.txt文件都扔到datasets\labels\train。
接着将yolov5-master/data/coco128.yaml复制粘贴到xunlianji中,改名为xunlianji_parameter.yaml,以作为xunlianji的参数配置文件。
将yolov5-master/models中的yolov5s.yaml复制粘贴到xunlianji中,改名为xunlianji_model.yaml(意为模型)。
现在xunlianji里的文件夹结构已经完全成型了,下一步就是修改配置文件了。
编辑xunlianji_parameter.yaml:(如下,只弄了两个标签,person和words,其他的都删了好了,path、train、val修改成自己的文件目录结构名,test不用管)
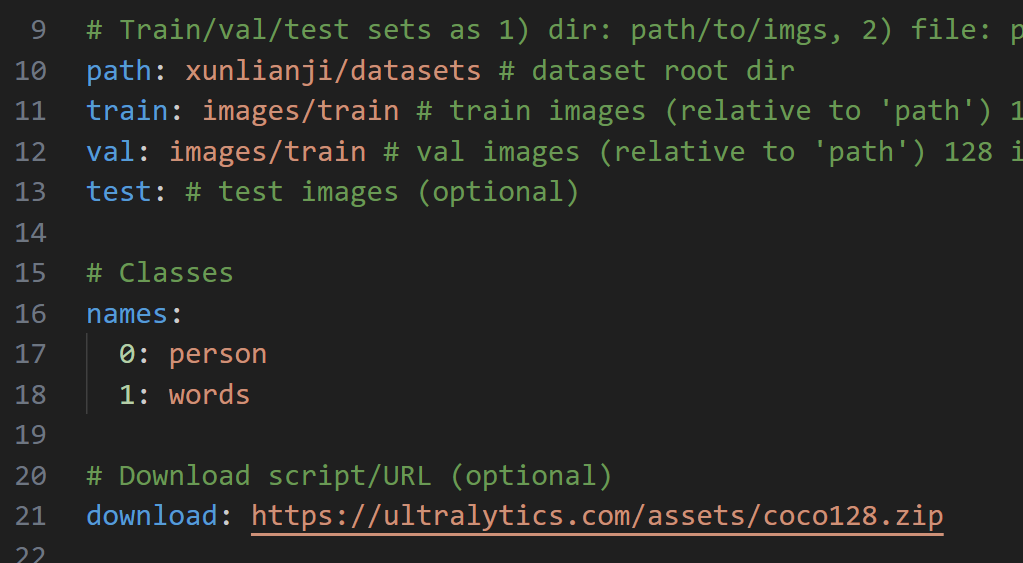
path是项目下的绝对路径,train是在path绝对路径条件下的训练集路径,即:xunlianji/datasets/images/train
val是验证集,但省事期间这里让训练集既当训练集也当验证集了。
接着修改xunlianji_model.yaml
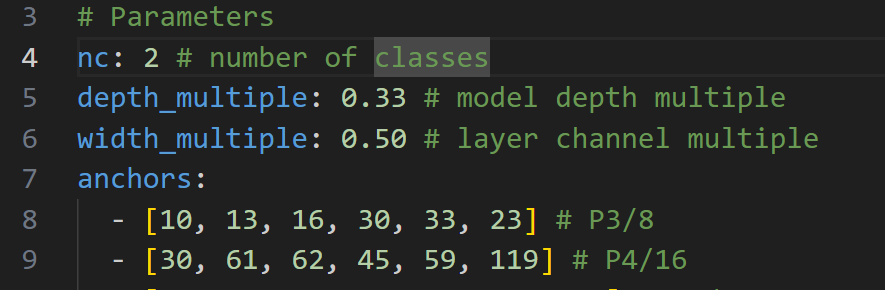
我只有俩标签,把nc改成2即可。
4.训练
回到根目录,打开train.py,调整参数
在train.py里一直往下拉到def parse_opt(known=False):
修改:
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")#使用yolov5s权重进行训练#这两个换成自己的训练集目录
parser.add_argument("--cfg", type=str, default=ROOT/"xunlianji/xunlianji_model.yaml", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "xunlianji/xunlianji_parameter.yaml", help="dataset.yaml path")#训练轮数,100轮、200轮都行
parser.add_argument("--epochs", type=int, default=200, help="total training epochs")parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")#批量处理的文件数
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="train, val image size (pixels)")#图片大小#断续训练,如果说在训练过程中意外地中断,那么下一次可以在这里填True,会接着上一次runs/exp继续训练
parser.add_argument("--resume", nargs="?", const=True, default=False, help="resume most recent training")#电脑没cuda,轻薄本的gpu又太差了,那只能拿cpu加速了
parser.add_argument("--device", default="cpu", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")#多线程设置,越大读取数据越快,但是太大了也会报错,因此也要根据自己状况填小。
parser.add_argument("--workers", type=int, default=4, help="max dataloader workers (per RANK in DDP mode)")然后运行train.py,开始训练。
等它训练完吧......
训练完成后,会在yolov5-master\runs\train\exp4\weights这里生成一个exp文件夹,每一次训练都会自动生成一个新的目录存放目录结果。
然后点开exp\weights,发现这里有两个文件last.pt和best.pt,一个是最后一轮训练得到的权重,一个是最佳权重(它认为的最佳),这就是训练得出的权重结果,接下来的测试就需要这次训练得到的.pt文件了。
5.测试
回到yolov5-master下,打开detect.py这个文件,找到def parse_opt():下边的代码,做如下修改:
##改成自己刚刚训练得到的权重文件,last.pt或者best.pt都行(先跑起来再说)
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "runs\\train\\exp4\\weights\\best.pt", help="model path or triton URL")#改成要检测的视频文件位置,为0时是检测电脑摄像头
parser.add_argument("--source", type=str, default=ROOT / "0", help="file/dir/URL/glob/screen/0(webcam)")#改成自己的数据集参数文件
parser.add_argument("--data", type=str, default=ROOT / "xunlianji/xunlianji_parameter.yaml", help="(optional) dataset.yaml path")#置信度,大于这个置信度才会显示框框
parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")#GPU加速选项,如前所述,轻薄本GPU实在太拉了,只能用cpu加速了
parser.add_argument("--device", default="cpu", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")其他的也不太懂,保持默认即可。
运行detect.py
测试的结果会保存到yolov5-master\runs\test\exp里。
Yolov5-lite
上述流程都是以yolov5为例的,Yolov5-lite是yolov5的精简版本,保留了必要的功能同时提供了更快的训练和检测速度,适合往树莓派之类乱七八糟的嵌入式设备上塞。
在尝试折腾yolov5-lite的时候同样遇到了一些坑(要是能下载下来后啥都不配置直接就能运行得起来该多好😭)
下载yolov5-lite:https://github.com/ppogg/YOLOv5-Lite,或git clone https://github.com/ppogg/YOLOv5-Lite
在YOLOv5-Lite-master项目根目录下pip install -r requirements.txt
接下来在根目录下新建一个文件夹,命名为weights。(作者大大没把权重文件直接放进去,那咱们直接手动下载吧)
打开README.md,找着
parser.add_argument('--weights', nargs='+', type=str, default='weights/v5lite-s.pt', help='model.pt path(s)')
#这个就是刚才手动下载下来的权重了,其实换成别的训练权重也行,这不是慢嘛parser.add_argument('--source', type=str, default='0', help='source') # default='0'时是打开电脑摄像头parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
#老规矩,改成cpu,等上了研究生一定要弄一台有显卡的电脑啊啊啊啊啊然后运行detect.py,报错了:
1/1: 0... Traceback (most recent call last):
File "D:\FreeDocument\YOLOv5-Lite-master\detect.py", line 178, in <module>
detect()
File "D:\FreeDocument\YOLOv5-Lite-master\detect.py", line 51, in detect
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\FreeDocument\YOLOv5-Lite-master\utils\datasets.py", line 279, in __init__
if 'youtube.com/' in url or 'youtu.be/' in url: # if source is YouTube video
^^^^^^^^^^^^^^^^^^^^^
TypeError: argument of type 'int' is not iterable

直接去utils/datasets.py这个文件里边,把 if 代码块给注释掉算了,反正好像也没啥用

重新运行detect.py,开始打开摄像头检测了。
yolov5-lite的训练应该也跟yolov5差不多,举一反三呗。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)