操作系统导论-虚拟化-雷姆兹·H.阿帕希杜塞尔、安德莉亚·C.阿帕希杜塞尔
学生:尊敬的教授,什么是虚拟化?
教授:想象我们有一个桃子。
学生:桃子?(不可思议)
教授:是的,一个桃子,我们称之为物理(physical)桃子。但有很多想吃这个桃子的人,我们希望向每个想吃的人提供一个属于他的桃子,这样才能皆大欢喜。我们把给每个人的桃子称为虚拟(virtual)桃子。我们通过某种方式,从这个物理桃子创造出许多虚拟桃子。重要的是,在这种假象中,每个人看起来都有一个物理桃子,但实际上不是。
学生:所以每个人都不知道他在和别人一起分享一个桃子吗?
教授:是的。
学生:但不管怎么样,实际情况就是只有一个桃子啊。
教授:是的,所以呢?
学生:所以,如果我和别人分享同一个桃子,我一定会发现这个问题。
教授:是的!你说得没错。但吃的人多才有这样的问题。多数时间他们都在打盹或者做其他事情,所以,你可以在他们打盹的时候把他手中的桃子拿过来分给其他人,这样我们就创造了有许多虚拟桃子的假象,每人一个桃子!
学生:这听起来就像糟糕的竞选口号。教授,您是在跟我讲计算机知识吗?
教授:年轻人,看来需要给你一个更具体的例子。以最基本的计算机资源CPU为例,假设一个计算机只有一个CPU(尽管现代计算机一般拥有2个、4个或者更多CPU),虚拟化要做的就是将这个CPU虚拟成多个虚拟CPU并分给每一个进程使用,因此,每个应用都以为自己在独占CPU,但实际上只有一个CPU。这样操作系统就创造了美丽的假象——它虚拟化了CPU。
学生:听起来好神奇,能再多讲一些吗?它是如何工作的?
教授:问得很及时,听上去你已经做好开始学习的准备了。
学生:是的,不过我还真有点担心您又要讲桃子的事情了。
教授:不用担心,毕竟我也不喜欢吃桃子。那我们开始学习吧……
进程
进程的非正式定义非常简单:进程就是运行中的程序。程序本身是没有生命周期的,它只是存在磁盘上面的一些指令(也可能是一些静态数据)。是操作系统让这些字节运行起来,让程序发挥作用。也就是说,进程就是操作系统为正在运行的程序提供的抽象。
事实表明,人们常常希望同时运行多个程序。比如:在使用计算机或者笔记本的时候,我们会同时运行浏览器、邮件、游戏、音乐播放器,等等。实际上,一个正常的系统可能会有上百个进程同时在运行。如果能实现这样的系统,人们就不需要考虑这个时候哪一个CPU是可用的。那么,如何提供有许多CPU的假象?
操作系统通过虚拟化(virtualizing)CPU来提供这种假象。通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟CPU的假象。这就是时分共享(time sharing)CPU技术,允许用户如愿运行多个并发进程。
时分共享(time sharing)是操作系统共享资源所使用的最基本的技术之一。通过允许资源由一个实体使用一小段时间,然后由另一个实体使用一小段时间,如此下去,所谓的资源(例如,CPU或网络链接)可以被许多人共享。时分共享的自然对应技术是空分共享,资源在空间上被划分给希望使用它的人。例如,磁盘空间自然是一个空分共享资源,因为一旦将块分配给文件,在用户删除文件之前,不可能将它分配给其他文件。
在这些机制之上,操作系统中有一些智能以策略(policy)的形式存在。策略是在操作系统内做出某种决定的算法。
进程API
所有现代操作系统都以某种形式提供这些API.
·创建(create):操作系统必须包含一些创建新进程的方法。在shell中键入命令或双击应用程序图标时,会调用操作系统来创建新进程,运行指定的程序。
UNIX系统采用了一种非常有趣的创建新进程的方式,即通过一对系统调用:fork()和exec()。进程还可以通过第三个系统调用wait(),来等待其创建的子进程执行完成。
操作系统运行程序必须做的第一件事是将代码和所有静态数据(例如初始化变量)加载(load)到内存中,加载到进程的地址空间中。程序最初以某种可执行格式驻留在磁盘上(disk,或者在某些现代系统中,在基于闪存的SSD上)。因此,将程序和静态数据加载到内存中的过程,需要操作系统从磁盘读取这些字节,并将它们放在内存中的某处

将代码和静态数据加载到内存后,操作系统在运行此进程之前还需要执行其他一些操作。必须为程序的运行时栈(run-time stack或stack)分配一些内存。
操作系统也可能为程序的堆(heap)分配一些内存。在C程序中,堆用于显式请求的动态分配数据。操作系统还将执行一些其他初始化任务,特别是与输入/输出(I/O)相关的任务。
通过将代码和静态数据加载到内存中,通过创建和初始化栈以及执行与I/O设置相关的其他工作,OS现在(终于)为程序执行搭好了舞台。然后它有最后一项任务:启动程序,在入口处运行,即main()。通过跳转到main()例程(第5章讨论的专门机制),OS将CPU的控制权转移到新创建的进程中,从而程序开始执行

系统调用fork()用于创建新进程。创建的进程几乎与调用进程完全一样,对操作系统来说,这时看起来有两个完全一样的p1程序在运行,并都从fork()系统调用中返回。新创建的进程称为子进程(child),原来的进程称为父进程(parent)。子进程不会从main()函数开始执行(因此hello world信息只输出了一次),而是直接从fork()系统调用返回,就好像是它自己调用了fork()。
子进程并不是完全拷贝了父进程。具体来说,虽然它拥有自己的地址空间(即拥有自己的私有内存)、寄存器、程序计数器等,但是它从fork()返回的值是不同的。父进程获得的返回值是新创建子进程的PID,而子进程获得的返回值是0。这个差别非常重要,因为这样就很容易编写代码处理两种不同的情况(像上面那样)。
你可能还会注意到,它的输出不是确定的(deterministic)。子进程被创建后,我们就需要关心系统中的两个活动进程了:子进程和父进程。假设我们在单个CPU的系统上运行(简单起见),那么子进程或父进程在此时都有可能运行。在上面的例子中,父进程先运行并输出信息。在其他情况下,子进程可能先运行。CPU调度程序(scheduler)决定了某个时刻哪个进程被执行。
exec()会从可执行程序中加载代码和静态数据,并用它覆写自己的代码段(以及静态数据),堆、栈及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过argv传递给该进程。因此,它并没有创建新进程,而是直接将当前运行的程序(以前的p3)替换为不同的运行程序(wc)。子进程执行exec()之后,几乎就像p3.c从未运行过一样。对exec()的成功调用永远不会返回。
·销毁(destroy):由于存在创建进程的接口,因此系统还提供了一个强制销毁进程的接口。当然,很多进程会在运行完成后自行退出。但是,如果它们不退出,用户可能希望终止它们,因此停止失控进程的接口非常有用。
·等待(wait):有时等待进程停止运行是有用的,因此经常提供某种等待接口。·其他控制(miscellaneous control):除了杀死或等待进程外,有时还可能有其他控制。例如,大多数操作系统提供某种方法来暂停进程(停止运行一段时间),然后恢复(继续运行)。
有时候父进程需要等待子进程执行完毕。这项任务由wait()系统调用(或者更完整的兄弟接口waitpid())。
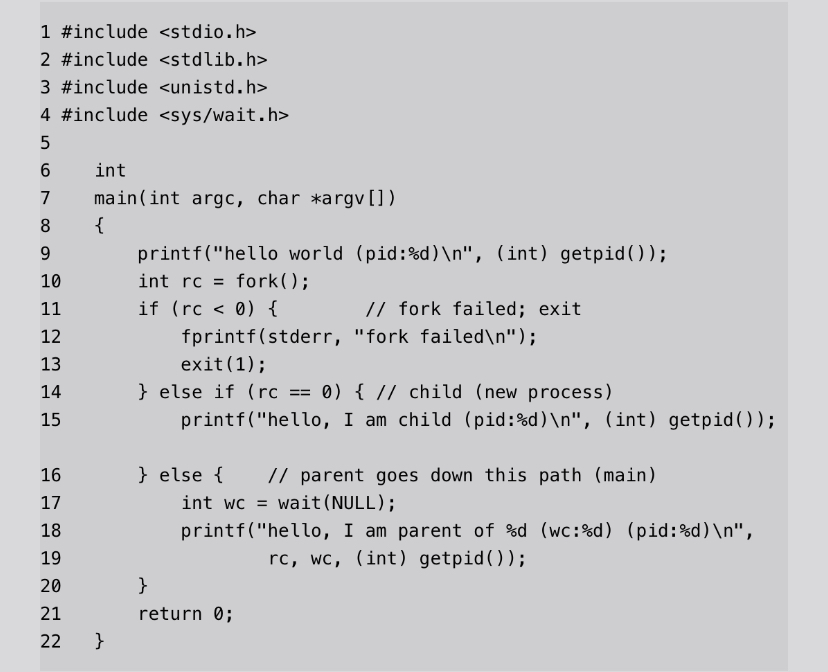
父进程调用wait(),延迟自己的执行,直到子进程执行完毕。当子进程结束时,wait()才返回父进程。通过这段代码,现在我们知道子进程总是先输出结果。为什么知道?好吧,它可能只是碰巧先运行,像以前一样,因此先于父进程输出结果。但是,如果父进程碰巧先运行,它会马上调用wait()。该系统调用会在子进程运行结束后才返回。因此,即使父进程先运行,它也会礼貌地等待子进程运行完毕,然后wait()返回,接着父进程才输出自己的信息。
状态(statu):通常也有一些接口可以获得有关进程的状态信息,例如运行了多长时间,或者处于什么状态。
在早期的计算机系统[DV66,V+65]中,出现了一个进程可能处于这些状态之一的概念。简而言之,进程可以处于以下3种状态之一。
·运行(running):在运行状态下,进程正在处理器上运行。这意味着它正在执行指令。
·就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统选择不在此时运行。
·阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备运行。一个常见的例子是,当进程向磁盘发起I/O请求时,它会被阻塞,因此其他进程可以使用处理器。
大多数情况下,shell可以在文件系统中找到这个可执行程序,调用fork()创建新进程,并调用exec()的某个变体来执行这个可执行程序,调用wait()等待该命令完成。子进程执行结束后,shell从wait()返回并再次输出一个提示符,等待用户输入下一条命令。
总结:
1、当调用fork()时,一个与父进程一模一样的子进程被创建,两个进程都从fork()系统调用返回,父进程的返回值是子进程的PID,而子进程的返回值是0。
2、当父进程调用wait()时,父进程在子进程运行完后才运行。
3、当子进程调用exec()时,子进程可以执行与父进程不同的程序。
受限直接执行
为了虚拟化CPU,操作系统需要以某种方式让许多任务共享物理CPU,让它们看起来像是同时运行。基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换。通过以这种方式时分共享(time sharing)CPU,就实现了虚拟化。
操作系统必须以高性能的方式虚拟化CPU,同时保持对系统的控制。为此,需要硬件和操作系统支持。操作系统通常会明智地利用硬件支持,以便高效地实现其工作。
为了使程序尽可能快地运行,操作系统开发人员想出了一种技术——我们称之为受限的直接执行(limited direct execution)。这个概念的“直接执行”部分很简单:只需直接在CPU上运行程序即可。因此,当OS希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码(从磁盘)加载到内存中,找到入口点(main()函数或类似的),跳转到那里,并开始运行用户的代码。但是,这种方法在我们的虚拟化CPU时产生了一些问题。第一个问题:如果我们只运行一个程序,操作系统怎么能确保程序不做任何我们不希望它做的事,同时仍然高效地运行它?第二个问题:当我们运行一个进程时,操作系统如何让它停下来并切换到另一个进程,从而实现虚拟化CPU所需的时分共享?如果对运行程序没有限制,操作系统将无法控制任何事情,因此会成为“仅仅是一个库”——对于有抱负的操作系统而言,这真是非常令人悲伤的事!
提示:采用受保护的控制权转移
硬件通过提供不同的执行模式来协助操作系统。在用户模式(user mode)下,应用程序不能完全访问硬件资源。在内核模式(kernel mode)下,操作系统可以访问机器的全部资源。还提供了陷入(trap)内核和从陷阱返回(return-from-trap)到用户模式程序的特别说明,以及一些指令,让操作系统告诉硬件陷阱表(trap table)在内存中的位置。
对于I/O和其在用户模式下运行的代码会受到限制。例如,在用户模式下运行时,进程不能发出I/O请求。这样做会导致处理器引发异常,操作系统可能会终止进程。
与用户模式不同的内核模式(kernel mode),操作系统(或内核)就以这种模式运行。在此模式下,运行的代码可以做它喜欢的事,包括特权操作,如发出I/O请求和执行所有类型的受限指令。
我们仍然面临着一个挑战——如果用户希望执行某种特权操作(如从磁盘读取),应该怎么做?为了实现这一点,几乎所有的现代硬件都提供了用户程序执行系统调用的能力。要执行系统调用,程序必须执行特殊的陷阱(trap)指令。该指令同时跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许),从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从陷阱返回(return-from-trap)指令,如你期望的那样,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
为什么系统调用看起来像过程调用?原因很简单:它是一个过程调用,但隐藏在过程调用内部的是著名的陷阱指令。更具体地说,当你调用open()(举个例子)时,你正在执行对C库的过程调用。其中,无论是对于open()还是提供的其他系统调用,库都使用与内核一致的调用约定来将参数放在众所周知的位置(例如,在栈中或特定的寄存器中),将系统调用号也放入一个众所周知的位置(同样,放在栈或寄存器中),然后执行上述的陷阱指令。库中陷阱之后的代码准备好返回值,并将控制权返回给发出系统调用的程序。因此,C库中进行系统调用的部分是用汇编手工编码的,因为它们需要仔细遵循约定,以便正确处理参数和返回值,以及执行硬件特定的陷阱指令。
陷阱如何知道在OS内运行哪些代码?内核通过在启动时设置陷阱表(trap table)来实现。当机器启动时,它在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事,就是告诉硬件在发生某些异常事件时要运行哪些代码。能够执行指令来告诉硬件陷阱表的位置是一个非常强大的功能。因此,你可能已经猜到,这也是一项特权(privileged)操作。如果你试图在用户模式下执行这个指令,硬件不会允许,你可能会猜到会发生什么(提示:再见,违规程序)。
我们假设每个进程都有一个内核栈,在进入内核和离开内核时,寄存器(包括通用寄存器和程序计数器)分别被保存和恢复。

受限直接运行协议
LDE协议(受限直接运行协议)有两个阶段。第一个阶段(在系统引导时),内核初始化陷阱表,并且CPU记住它的位置以供随后使用。内核通过特权指令来执行此操作(所有特权指令均以粗体突出显示)。第二个阶段(运行进程时),在使用从陷阱返回指令开始执行进程之前,内核设置了一些内容(例如,在进程列表中分配一个节点,分配内存)。这会将CPU切换到用户模式并开始运行该进程。当进程希望发出系统调用时,它会重新陷入操作系统,然后再次通过从陷阱返回,将控制权还给进程。该进程然后完成它的工作,并从main()返回。这通常会返回到一些存根代码,它将正确退出该程序(例如,通过调用exit()系统调用,这将陷入OS中)。此时,OS清理干净,任务完成了。
操作系统如何重新获得CPU的控制权(regain control),以便它可以在进程之间切换?
协作(cooperative)方式。在这种风格下,操作系统相信系统的进程会合理运行。运行时间过长的进程被假定会定期放弃CPU,以便操作系统可以决定运行其他任务。大多数进程通过进行系统调用,将CPU的控制权转移给操作系统,例如打开文件并随后读取文件,或者向另一台机器发送消息或创建新进程。像这样的系统通常包括一个显式的yield系统调用,它什么都不干,只是将控制权交给操作系统,以便系统可以运行其他如果应用程序执行了某些非法操作,也会将控制转移给操作系统。例如,如果应用程序以0为除数,或者尝试访问应该无法访问的内存,就会陷入(trap)操作系统。操作系统将再次控制CPU(并可能终止违规进程)。因此,在协作调度系统中,OS通过等待系统调用,或某种非法操作发生,从而重新获得CPU的控制权。
事实证明,没有硬件的额外帮助,如果进程拒绝进行系统调用(也不出错),从而将控制权交还给操作系统,那么操作系统无法做任何事情。事实上,在协作方式中,当进程陷入无限循环时,唯一的办法就是使用古老的解决方案来解决计算机系统中的所有问题——重新启动计算机。因为 OS 只是个运行在 CPU 上的软件,跟能够运行在没有 OS 的 裸机上的普通软件是一样的,所以在争抢 CPU 资源上,其本身并没有特别卓越的能力。这个时候,就需要上游的场外裁判进场了,也就是硬件。
如何在没有协作的情况下获得控制权?
时钟中断(timer interrupt)。时钟设备可以编程为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得CPU的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。即使进程以非协作的方式运行,添加时钟中断(timer interrupt)也让操作系统能够在CPU上重新运行。因此,该硬件功能对于帮助操作系统维持机器的控制权至关重要。
首先,正如我们之前讨论过的系统调用一样,操作系统必须通知硬件哪些代码在发生时钟中断时运行。因此,在启动时,操作系统就是这样做的。其次,在启动过程中,操作系统也必须启动时钟,这当然是一项特权操作。一旦时钟开始运行,操作系统就感到安全了,因为控制权最终会归还给它,因此操作系统可以自由运行用户程序。
硬件在发生中断时有一定的责任,尤其是在中断发生时,要为正在运行的程序保存足够的状态,以便随后从陷阱返回指令能够正确恢复正在运行的程序。这一组操作与硬件在显式系统调用陷入内核时的行为非常相似,其中各种寄存器因此被保存(进入内核栈),因此从陷阱返回指令可以容易地恢复。
既然操作系统已经重新获得了控制权,无论是通过系统调用协作,还是通过时钟中断更强制执行,都必须决定:是继续运行当前正在运行的进程,还是切换到另一个进程。这个决定是由调度程序(scheduler)做出的,它是操作系统的一部分。
如果决定进行切换,OS就会执行一些底层代码,即所谓的上下文切换(context switch)。上下文切换在概念上很简单:操作系统要做的就是为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程)的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进程。至此上下文切换完成。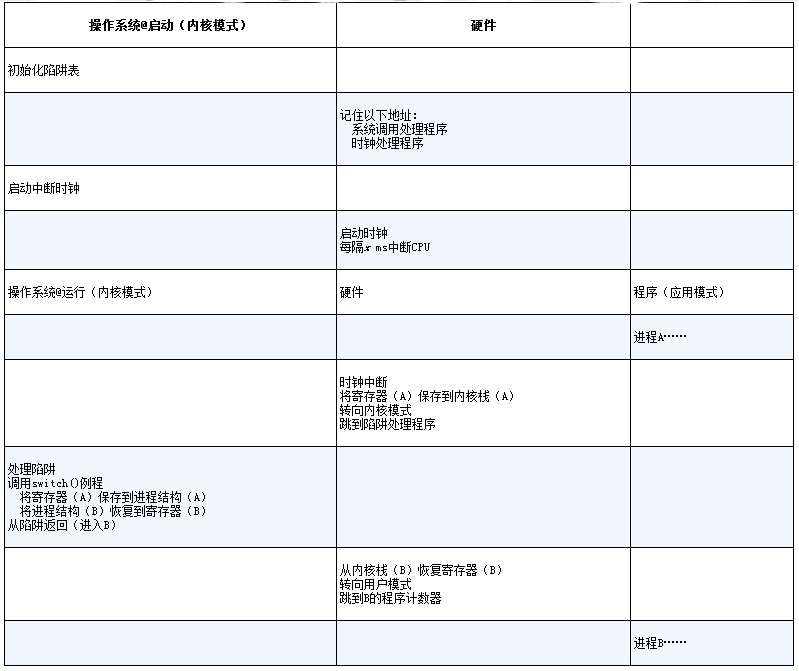
进程调度
抢占式调度程序
新度量指标:响应时间
如何构建对响应时间敏感的调度程序?
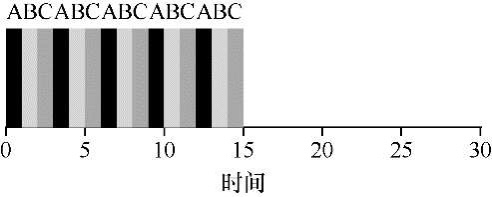
调度:多级反馈队列
MLFQ:基本规则
MLFQ的一些问题:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号