

大家都对模糊查询并不陌生,比如我们想根据商品名称,商品标题劳或者是人的名称查询的时候都是去模糊匹配,不知道大家是怎么去模糊匹配的,小编用的是数据库的like关键字,可是就在不久前被人鄙视了,说like不走索引,效率低下。
于是我便去项目里面查看一下,看看我那牛逼的同事用的什么方法解决模糊匹配,我看到了一个陌生的函数INSTR,于是就去网上查了一番,说INSTR的效率比like略高,还有类似的函数,如:LOCATE,POSITION,由于是受到了鄙视,我也很不服气,于是在电脑上装了个虚拟机,安装了mysql,进行以下的测试。
数据库:mysql
版本:5.7.20
表:
CREATE TABLE `product` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '主键,不为空',
`merchant_id` int(11) DEFAULT NULL COMMENT '商家id',
`product_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '商品名称',
`product_title` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '商品标题',
`classify_1` int(10) DEFAULT NULL COMMENT '1级分类',
`classify_2` int(10) DEFAULT NULL COMMENT '2级分类',
`classify_3` int(10) DEFAULT NULL COMMENT '3级分类',
`brand_id` int(10) DEFAULT NULL COMMENT '品牌',
`product_amount` decimal(10,0) DEFAULT NULL COMMENT '商品金额',
`sales_amount` decimal(10,0) DEFAULT NULL COMMENT '销售金额',
`product_status` int(10) DEFAULT NULL COMMENT '商品状态,1删除,0正常',
`flag` int(10) DEFAULT NULL COMMENT '标记',
`freight` decimal(10,2) DEFAULT NULL COMMENT '运费',
`sku_info` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '规格说明',
`remarks` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '售后说明',
`pic_url` varchar(500) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '预览图片地址',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`user_id` int(10) DEFAULT NULL COMMENT '操作人',
`user_ip` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL COMMENT '操作人ip',
`product_name_query` varchar(255) GENERATED ALWAYS AS (locate('8',`product_name`)) STORED,
PRIMARY KEY (`id`),
FULLTEXT KEY `index_name` (`product_name`)
) ENGINE=InnoDB AUTO_INCREMENT=4390799 DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
数据插入:
CREATE PROCEDURE product_insert()
BEGIN
DECLARE Y BIGINT DEFAULT 1;
WHILE Y<10000000
DO
INSERT INTO product(product_title,product_name,remarks,merchant_id,create_time,update_time,classify_1,classify_2,classify_3,brand_id,user_id,user_ip,freight,pic_url,sales_amount,product_amount,product_status)
VALUES(CONCAT('商品_iphone8_title_test_',Y),CONCAT('商品_iphone8_name_test_',Y),CONCAT('商品_iphone8_remrk_test_',Y),Y,NOW(),NOW(),1,1,1,1,1000,'192.168.18.100',5000,'http://www.baidu.com',5000,5000,0);
SET Y=Y+1;
COMMIT;
END WHILE ;
END;
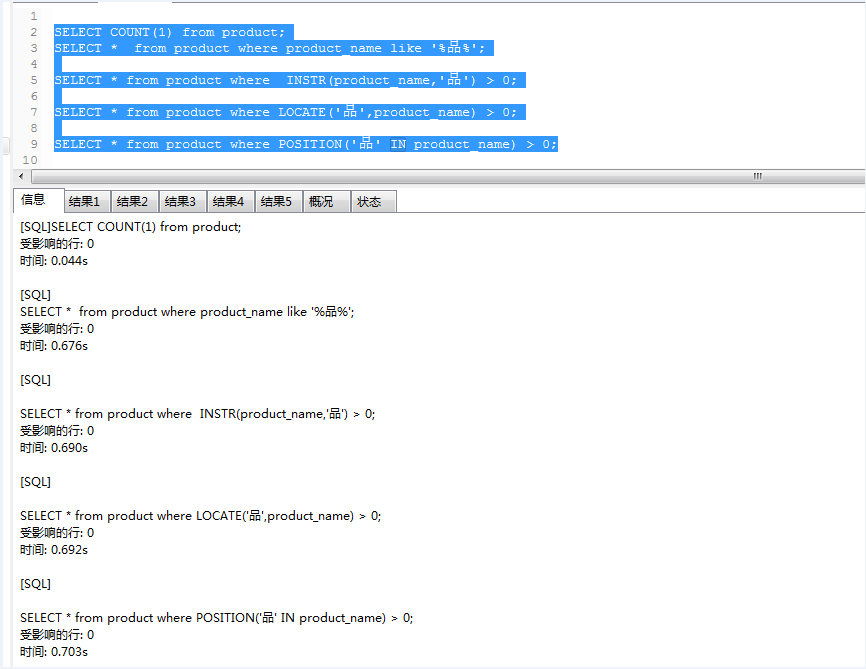
以下是24W+数据的测试结果:
英文模糊匹配
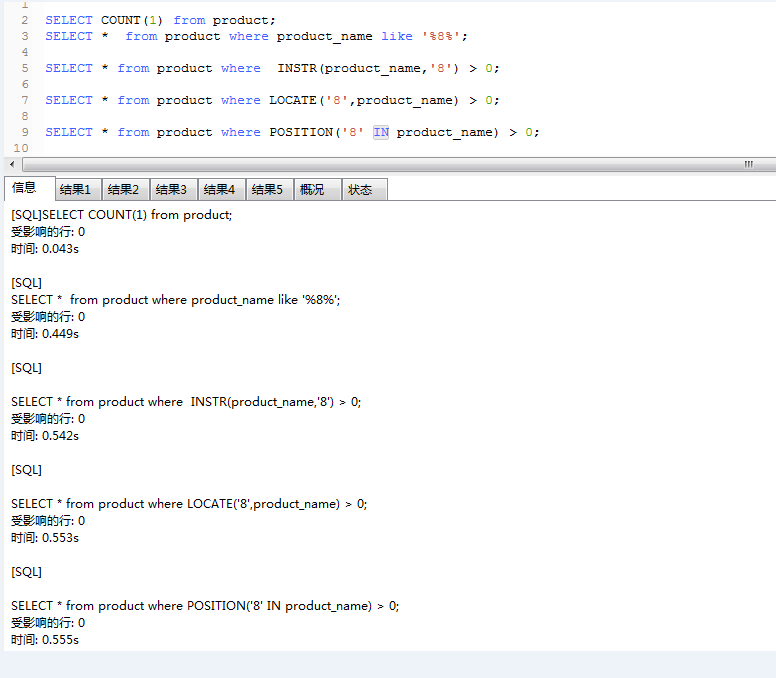
中文模糊匹配
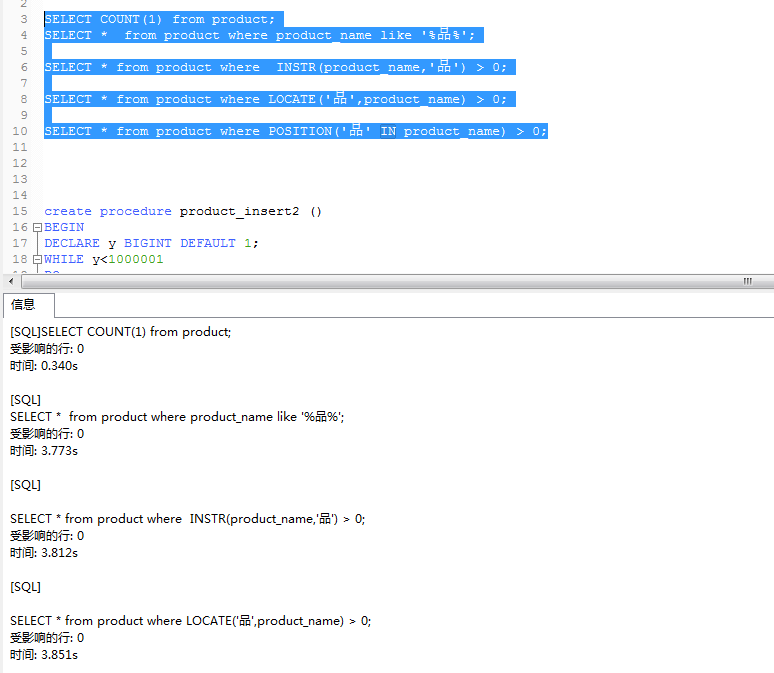
124W+数据的测试结果:
英文模糊匹配
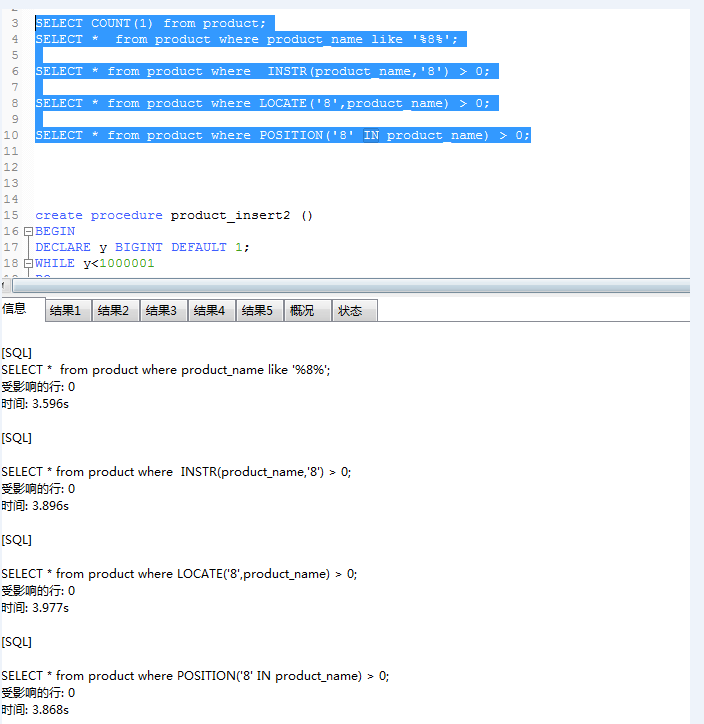
中文模糊匹配
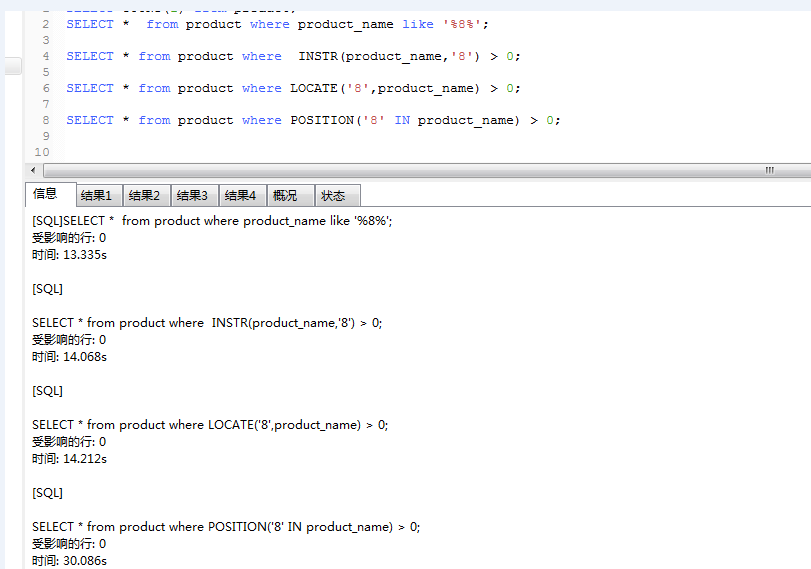
439W+数据的测试结果:
英文的测试结果:
中文的测试结果:
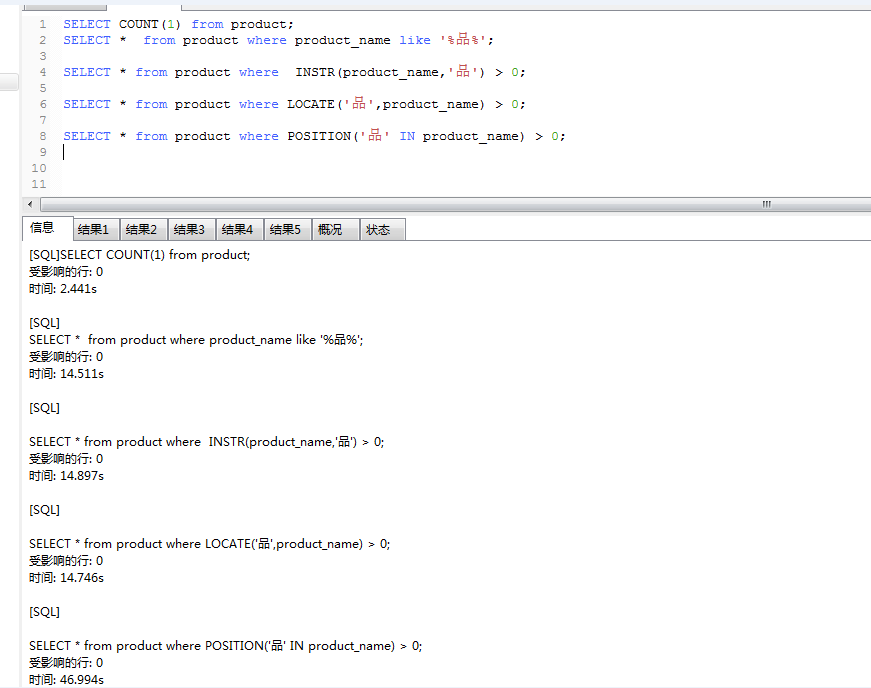
注意:POSITION函数查询结果并没有那么慢,也是15秒左右
测试的具体结果大家可以看以上的图片,也可以自行进行测试.
我通过查询中文和英文测试下的结论:
1:like,INSTR,LOCATE,POSITION它们都不走索引
2:like效率相对于INSTR,LOCATE,POSITION较高,这种效率随着数据的增大越明显
如果真的需要十几秒是查询一个sql,那该项目也腐朽到一定程度了,我想也应该换一种做法,比如增加搜索服务.
也听别人的朋友说,可以用全文索引或者虚拟列实现,但是小编觉得一旦数据量上去,这些都不可取,数据量小的话like和其它函数的效率有过之而无不及
希望小编的测试能给大家一些帮助,别人说的未必是真的,实践出真知,谢谢.
