
汇编_如何暂存数据
由双重循环引发的思考
内存中定义了二维字符串数组,使用双重循环完成字符遍历。
由于loop指令只认cx寄存器,在循环的过程中为了避免cx值被覆写,需要在内层循环前,将外层循环的cx值暂存起来。
使用寄存器完成大小写转换
assume cs:codesg,ds:datasg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
datasg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,3
s0:
mov dx,cx
mov si,0
mov cx,3
s:
mov al,[bx+si]
and al,11011111b
mov [bx+si],al
inc si
loop s
add bx,16
mov cx,dx
loop s0
mov ax,4c00h
int 21h
codesg ends
end start
在汇编程序中,用'...'方式指明的数据是以字符的形式给出,编译器将他们转换为ASCII码
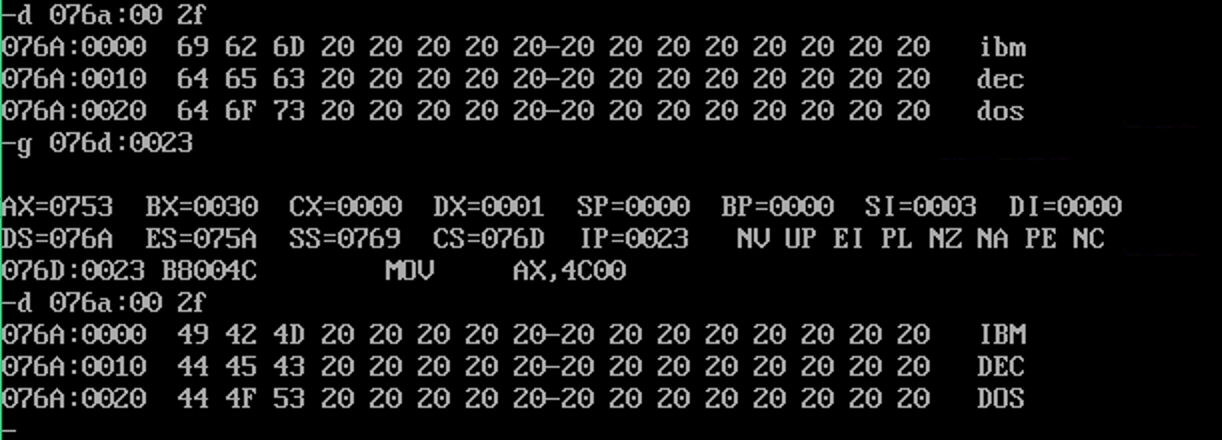
程序这里,唯一需要关注的就是,这里使用了dx暂存外层循环cx计数器值。
延伸出来的问题就是,没有这么多寄存器可供使用,我们应该把数据暂存在内存中。
改用内存暂存
assume cs:codesg,ds:datasg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
dw 0
datasg ends
codesg segment
start:
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,3
s0:
mov ds:[30h],cx
mov si,0
mov cx,3
s:
mov al,[bx+si]
and al,11011111b
mov [bx+si],al
inc si
loop s
add bx,16
mov cx,ds:[30h]
loop s0
mov ax,4c00h
int 21h
codesg ends
end start
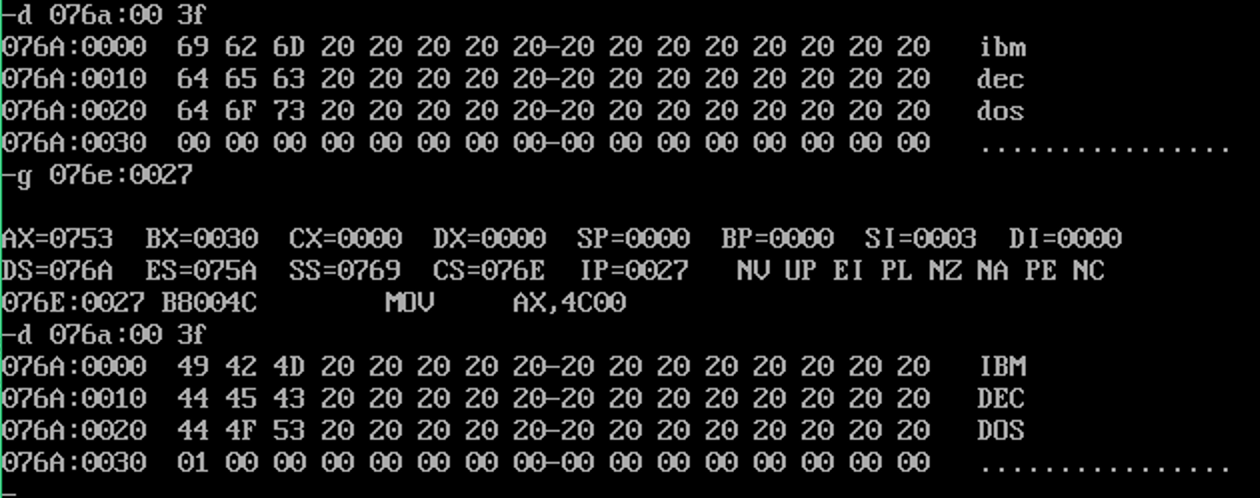
这段程序和之前不同的地方就是,使用内存暂存值,这样也有一个问题,就是变量多了,必须记住哪个数据放到了哪个内存单元。
使用栈
assume cs:codesg,ds:datasg,ss:stacksg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
datasg ends
stacksg segment
dw 0
stacksg ends
codesg segment
start:
mov ax,stacksg
mov ss,ax
mov sp,2
mov ax,datasg
mov ds,ax
mov bx,0
mov cx,3
s0:
push cx
mov si,0
mov cx,3
s:
mov al,[bx+si]
and al,11011111b
mov [bx+si],al
inc si
loop s
add bx,16
pop cx
loop s0
mov ax,4c00h
int 21h
codesg ends
end start
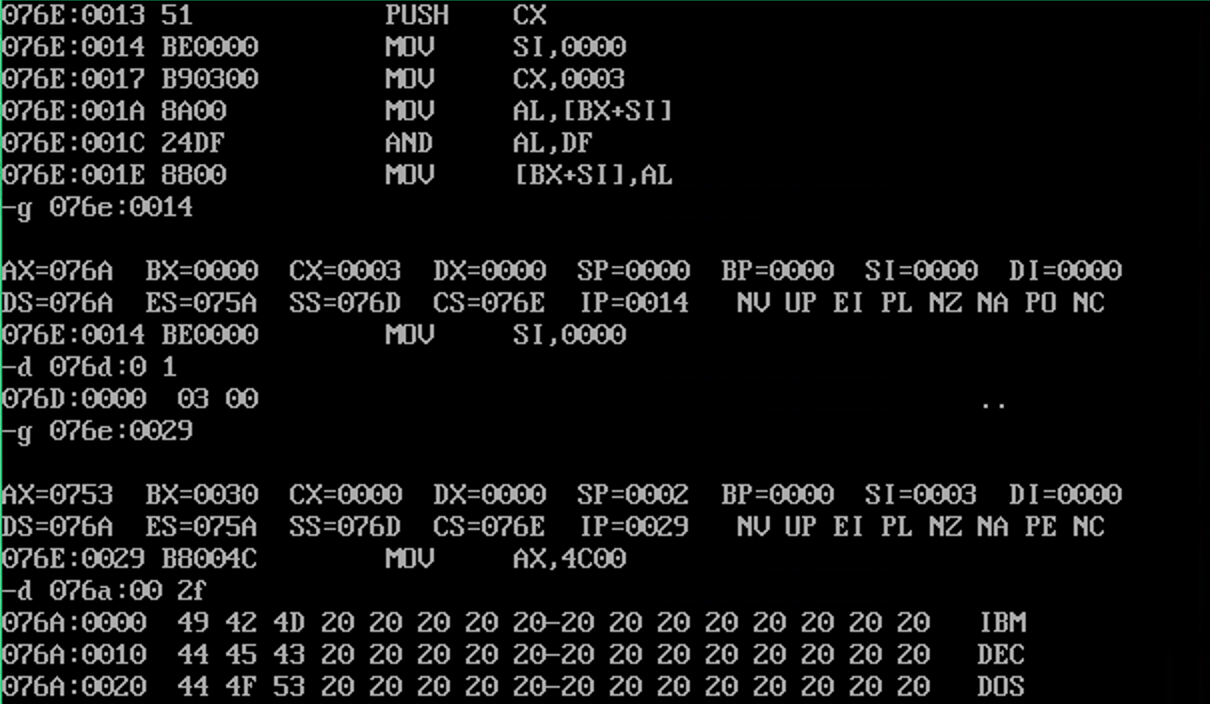
这里使用了栈,栈就很适合在当前循环场景下,这样即便有许多个循环或者变量,只要可以按顺序放入和取出,就可以放在栈里。
这要比单纯的放在某一个内存空间,自己记住数据对应的内存地址要好一点。
反汇编C语言双层循环代码
我们在高级语言里,循环这里一般都是任意定义i,j,k,实际反汇编看一下,这些局部变量被放到了哪里。
反汇编使用的是,在线编译,编译器使用的是x86-64 clang 16.0.0
int square() {
int i;
int j;
for(i=0;i<1;i++) {
for(j=0;j<1;j++) {
}
}
}
square: # @square
push rbp
mov rbp, rsp
mov dword ptr [rbp - 8], 0
.LBB0_1: # =>This Loop Header: Depth=1
cmp dword ptr [rbp - 8], 1
jge .LBB0_8
mov dword ptr [rbp - 12], 0
.LBB0_3: # Parent Loop BB0_1 Depth=1
cmp dword ptr [rbp - 12], 1
jge .LBB0_6
jmp .LBB0_5
.LBB0_5: # in Loop: Header=BB0_3 Depth=2
mov eax, dword ptr [rbp - 12]
add eax, 1
mov dword ptr [rbp - 12], eax
jmp .LBB0_3
.LBB0_6: # in Loop: Header=BB0_1 Depth=1
jmp .LBB0_7
.LBB0_7: # in Loop: Header=BB0_1 Depth=1
mov eax, dword ptr [rbp - 8]
add eax, 1
mov dword ptr [rbp - 8], eax
jmp .LBB0_1
.LBB0_8:
mov eax, dword ptr [rbp - 4]
pop rbp
ret
这里i,j是放在内存中的,也可以发现int是占用了4字节。
总结
今天收获有二。
其一,字符转换大小写之前都是使用的先判断的'a','z'大小关系,然后再加减。这里学到二进制按位操作后,去看了java源码,发现源码里也是通过二进制位判断的,不由得感叹这帮写源码的家伙们,技术都在细节里。
其二,暂存数据如何放置。高级语言里可以任意定义i,j,k,之前从来没有想过这些变量在具体执行的时候,变量放在哪里的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号