
MapReduce论文总结
解决了什么问题
MapReduce是隐藏了分布式环境下的代码复杂性,抽象出map和reduce两个阶段,分布式计算解决框架
如何实现
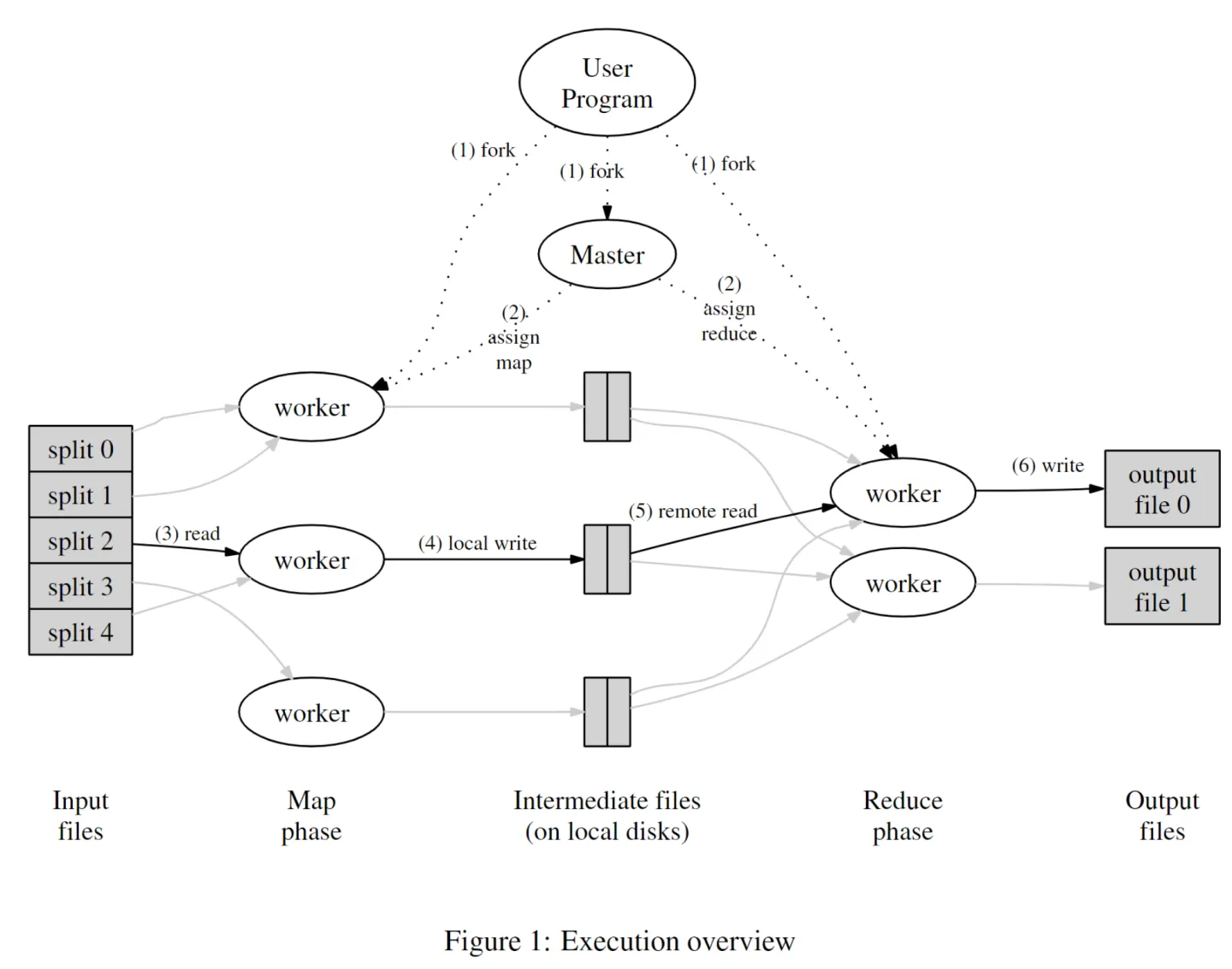
由MapReduce运行流程图可知,程序分为1个master节点和多个worker节点。worker节点负责实际计算,而master节点协调worker节点的任务分配。程序执行过程分为Map和Reduce两个阶段,Map阶段接收一组输入(例如多个文本文件),执行用户自定义的map函数,输出中间key/value对(例如单词出现次数1);Reduce阶段则是执行用户自定义的reduce函数,整合中间值(例如单词词频累加),输出结果
可能会有什么问题
master节点宕机如何解决
master周期性的将自身数据写入磁盘,即checkpoint。如果这个master挂掉了,那么就可以从最新的checkpoint创建出一个新的备份,重新运行MapReduce程序
worker节点超时/宕机如何解决
master会周期性ping下每个worker。如果在一定时间内无法收到来自某个worker的响应,那么master就会将该worker标记为failed。正在由该worker进行的任务需要安排给其他的worker去完成
如何保证多个worker执行同一任务时的幂等性
由于可能存在worker节点超时,由原本本该他完成的任务,交给了别的worker。这样,这一个任务就会生成多个对应的输出,worker执行时生成系统临时文件,确定某一worker完成时,再由master重命名这些文件
优化
尽可能节省网络带宽
- worker机器执行MapReduce操作时,输入数据尽可能在本地进行读取
提升执行速度
- 合理的任务粒度,包括map任务拆分为M个子任务,reduce任务拆分为R个子任务,worker机器数量
- 当MapReduce计算接近完成时,master会调度一个备用任务来执行剩下的处于正在执行中的任务
策略优化
- 合理的分区函数,哈希取模、前缀匹配等
- 有序的输出文件
- map执行完成之后,执行Combiner函数,整合重复数据
- 跳过损坏的记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号