hadoop2.X使用手册1:通过web端口查看主节点、slave1节点及集群运行状态
问题导读:
1.如何通过web查看hdfs集群状态
2.如何通过web查看运行在在主节点master上ResourceManager状态
3.如何通过web查看运行在在slave节点NodeManager资源状态
4.JobHistory 可以查看什么信息![]()
本文是在hadoop2的基础上hadoop2完全分布式最新高可靠安装文档的一个继续。
hadoop2.2安装完毕,我们该怎么使用它,这里做一些简单的介绍
一、可以通过登录Web控制台,查看HDFS集群状态,访问如下地址:
- http://master:50070/
<ignore_js_op>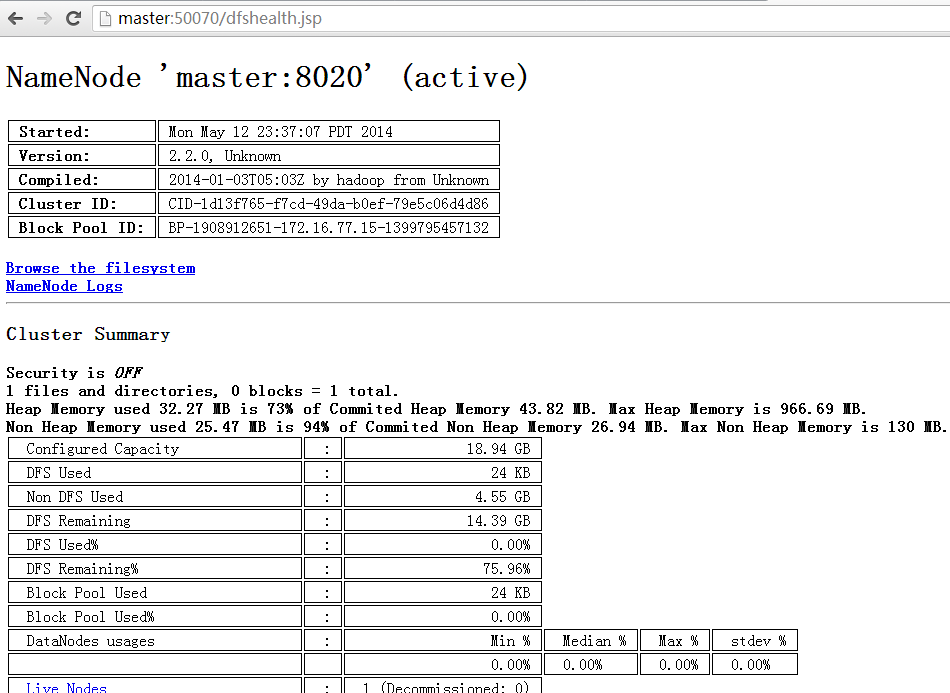
来源:
组件 :HDFS
节点 :NameNode
默认端口:50070
配置 :dfs.namenode.http-address
用途说明:http服务的端口
hadoop2.x常用端口及定义方法(可收藏方便以后查询)
二、ResourceManager运行在主节点master上,可以Web控制台查看状态
- http://master:8088/
如果你的主机名不是master,按照下面格式来访问。
- http://ip地址:8088/
或则
- http://hostname:8088/
<ignore_js_op>

这里介绍8088的来源:
yarn-site.xml中的属性:
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
三、NodeManager运行在从节点上,可以通过Web控制台查看对应节点的资源状态,例如节点slave1:
- http://slave1:8042/
<ignore_js_op>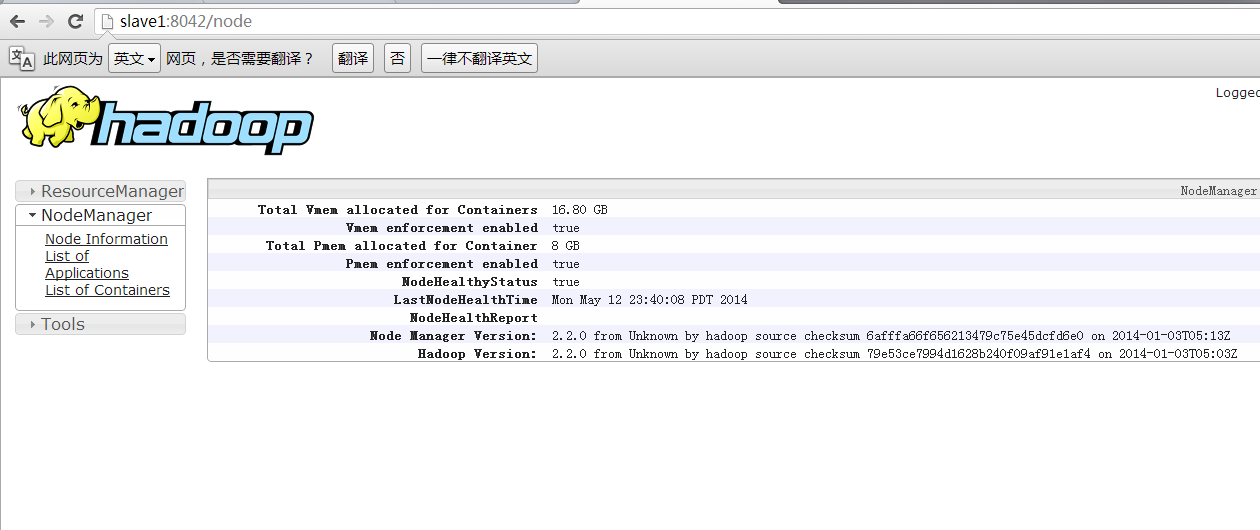
来源:
组件 :YARN
节点 :NodeManager
默认端口:8042
配置 :yarn.nodemanager.webapp.address
用途说明:http服务端口
四、管理JobHistory Server
启动可以JobHistory Server,能够通过Web控制台查看集群计算的任务的信息,执行如下命令:
- mr-jobhistory-daemon.sh start historyserver
默认使用19888端口。
通过访问http://master:19888/
<ignore_js_op>
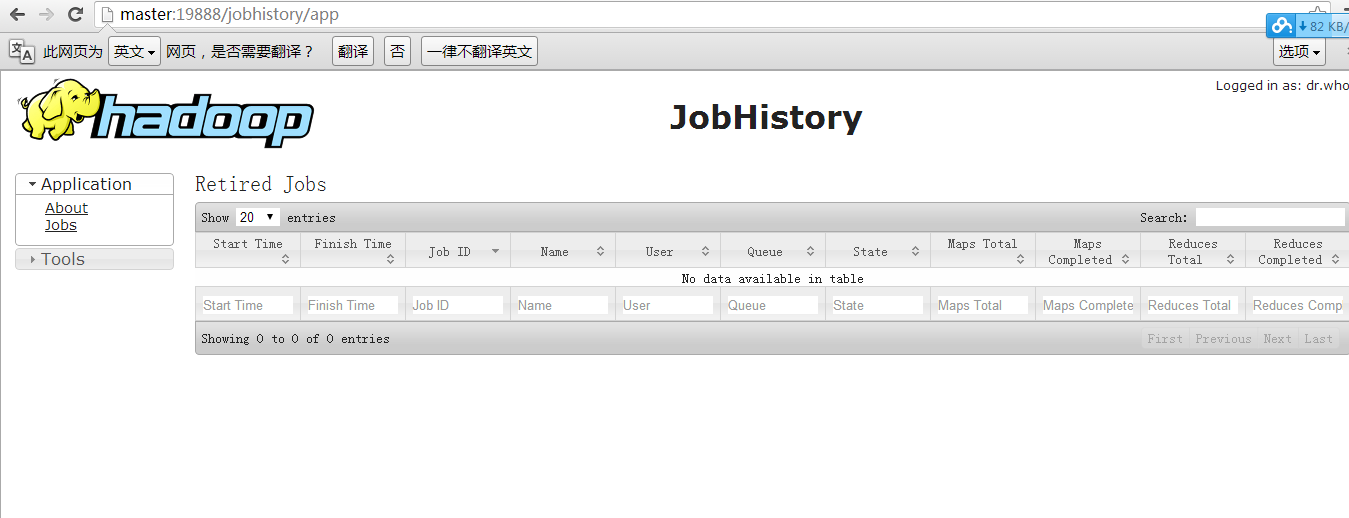
来源:
组件 :YARN
节点 :JobHistory Server
默认端口:19888
配置 :mapreduce.jobhistory.webapp.address
用途说明:http服务端口
以上所有端口都可以从hadoop2.x常用端口及定义方法(可收藏方便以后查询)文章中找到。
终止JobHistory Server,执行如下命令:
- mr-jobhistory-daemon.sh stop historyserver
问题导读
1.Hadoop文件系统shell与Linux shell有哪些相似之处?
2.如何改变文件所属组?
3.如何改变hdfs的文件权限?
4.如何查找hdfs文件,并且不区分大小写?![]()
概述
文件系统 (FS) shell 包括各种类似的命令直接与 Hadoop Distributed File System (HDFS)交互。hadoop也支持其它文件系统,比如 Local FS, HFTP FS, S3 FS, 和 其它的. FS shell被下面调用:
|
1
|
bin/hadoop fs <args> |
所有的FS shell命令带有URIs路径参数。The URI 格式是://authority/path。对 HDFS文件系统,scheme是hdfs。其中scheme和 authority参数都是可选的
如果没有指定,在文件中使用默认scheme.一个hdfs文件或则目录比如 /parent/child,可以是 hdfs://namenodehost/parent/child 或则简化为/parent/child(默认配置设置成指向hdfs://namenodehost).大多数FS shell命令对应 Unix 命令.每个命令都有不同的描述。将错误信息发送到标准错误输出和输出发送到stdout。
appendToFile【添加文件】
用法: hadoop fs -appendToFile <localsrc> ... <dst>添加单个src,或则多个srcs从本地文件系统到目标文件系统。从标准输入读取并追加到目标文件系统。
- hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
返回代码:
返回 0成功返回 1 错误
cat
用法: hadoop fs -cat URI [URI ...]
将路径指定文件的内容输出到stdout
例子:
- hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回代码:
返回 0成功返回 1 错误
checksum
用法: hadoop fs -checksum URI
返回 checksum 文件信息
例子:
- hadoop fs -checksum hdfs://nn1.example.com/file1
- hadoop fs -checksum file:///etc/hosts
chgrp
用法: hadoop fs -chgrp [-R] GROUP URI [URI ...]
改变文件所属组. 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行
chmod
用法: hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
更改文件的权限. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
chown
用法: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
更改文件的所有者. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
copyFromLocal
用法: hadoop fs -copyFromLocal <localsrc> URI
类似put命令, 需要指出的是这个限制是本地文件
选项:
- -f 选项会重写已存在的目标文件
copyToLocal
用法: hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
与get命令类似, 除了限定目标路径是一个本地文件外。
count
用法: hadoop fs -count [-q] [-h] [-v] <paths>统计目录个数,文件和目录下文件的大小。输出列:DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【目录个数,文件个数,总大小,路径名称】
输出列带有 -count -q 是: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【配置,其余指标,空间配额,剩余空间定额,目录个数,文件个数,总大小,路径名称】
The -h 选项,size可读模式.
The -v 选项显示一个标题行。
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
返回代码:
返回 0成功返回 1 错误
cp
用法: hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>复制文件,这个命令允许复制多个文件到一个目录。
‘raw.*’ 命名空间扩展属性被保留
(1)源文件和目标文件支持他们(仅hdfs)
(2)所有的源文件和目标文件路径在 /.reserved/raw目录结构下。
决定是否使用 raw.*命名空间扩展属性依赖于-P选项
选项:
- -f 选项如果文件已经存在将会被重写.
- -p 选项保存文件属性 [topx] (timestamps, ownership, permission, ACL, XAttr). 如果指定 -p没有参数, 保存timestamps, ownership, permission. 如果指定 -pa, 保留权限 因为ACL是一个权限的超级组。确定是否保存raw命名空间属性取决于是否使用-p决定
例子:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回代码:
返回 0成功返回 1 错误
createSnapshot
查看 HDFS Snapshots Guide.
deleteSnapshot
查看 HDFS Snapshots Guide.
df【查看还剩多少hdfs空间】
用法: hadoop fs -df [-h] URI [URI ...]
显示剩余空间
选项:
- -h 选项会让人更加易读 (比如 64.0m代替 67108864)
Example:
- hadoop dfs -df /user/hadoop/dir1
du
用法: hadoop fs -du [-s] [-h] URI [URI ...]显示给定目录的文件大小及包含的目录,如果只有文件只显示文件的大小
选项:
- -s 选项汇总文件的长度,而不是现实单个文件.
- -h 选项显示格式更加易读 (例如 64.0m代替67108864)
例子:
- hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
返回代码:
返回 0成功返回 1 错误
dus
用法: hadoop fs -dus <args>
显示统计文件长度
注意:这个命令已被启用, hadoop fs -du -s即可
expunge
用法: hadoop fs -expunge
清空垃圾回收站. 涉及 HDFS Architecture Guide 更多信息查看回收站特点
find
用法: hadoop fs -find <path> ... <expression> ...查找与指定表达式匹配的所有文件,并将选定的操作应用于它们。如果没有指定路径,则默认查找当前目录。如果没有指定表达式默认-print
下面主要表达式:
- -name 模式
-iname 模式
如果
值为TRUE如果文件基本名匹配模式使用标准的文件系统组合。如果使用-iname匹配不区分大小写。
- -print
-print0Always
值为TRUE. 当前路径被写至标准输出。如果使用 -print0 表达式, ASCII NULL 字符是追加的.
下面操作:
- expression -a expression
expression -and expression
expression expression
and运算符连接两个表达式,如果两个字表达式返回true,则返回true.由两个表达式的并置暗示,所以不需要明确指定。如果第一个失败,则不会应用第二个表达式。
例子:
hadoop fs -find / -name test -print
返回代码:
返回 0成功返回 1 错误
get
用法: hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>复制文件到本地文件。
复制文件到本地文件系统. 【CRC校验失败的文件复制带有-ignorecrc选项(如翻译有误欢迎指正)】
Files that fail the CRC check may be copied with the -ignorecrc option.
文件CRC可以复制使用CRC选项。
例子:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
返回代码:
返回 0成功返回 1 错误
相关内容
hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
hadoop入门手册3:Hadoop【2.7.1】初级入门之命令指南
hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2
hadoop2.X使用手册1:通过web端口查看主节点、slave1节点及集群运行状态
http://www.aboutyun.com/thread-7712-1-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号