谈谈工厂的作用
在设计模式的教学和推广过程中,很多企业学员和在校学生经常问我,工厂模式(包括简单工厂模式、工厂方法模式和抽象工厂模式)到底有什么用,很多时候通过反射机制就可以很灵活地创建对象,为毛还要工厂? ,在本文中我将围绕创建对象和使用对象来简单谈谈工厂的作用。
,在本文中我将围绕创建对象和使用对象来简单谈谈工厂的作用。
与一个对象相关的职责通常有三类:对象本身所具有的职责、创建对象的职责和使用对象的职责。对象本身的职责比较容易理解,就是对象自身所具有的一些数据和行为,可通过一些公开的方法来实现它的职责。在本文中,我们将简单讨论一下对象的创建职责和使用职责。
在Java语言中,我们通常有以下几种创建对象的方式:
(1) 使用new关键字直接创建对象;
(2) 通过反射机制创建对象;
(3) 通过clone()方法创建对象;
(4) 通过工厂类创建对象。
毫无疑问,在客户端代码中直接使用new关键字是最简单的一种创建对象的方式,但是它的灵活性较差,下面通过一个简单的示例来加以说明:
- class LoginAction {
- private UserDAO udao;
- public LoginAction() {
- udao = new JDBCUserDAO(); //创建对象
- }
- public void execute() {
- //其他代码
- udao.findUserById(); //使用对象
- //其他代码
- }
- }
在LoginAction类中定义了一个UserDAO类型的对象udao,在LoginAction的构造函数中创建了JDBCUserDAO类型的udao对象,并在execute()方法中调用了udao对象的findUserById()方法,这段代码看上去并没有什么问题。下面我们来分析一下LoginAction和UserDAO之间的关系,LoginAction类负责创建了一个UserDAO子类的对象并使用UserDAO的方法来完成相应的业务处理,也就是说LoginAction即负责udao的创建又负责udao的使用,创建对象和使用对象的职责耦合在一起,这样的设计会导致一个很严重的问题:如果在LoginAction中希望能够使用UserDAO的另一个子类如HibernateUserDAO类型的对象,必须修改LoginAction类的源代码,违反了“开闭原则”。如何解决该问题?
最常用的一种解决方法是将udao对象的创建职责从LoginAction类中移除,在LoginAction类之外创建对象,那么谁来负责创建UserDAO对象呢?答案是:工厂类。通过引入工厂类,客户类(如LoginAction)不涉及对象的创建,对象的创建者也不会涉及对象的使用。引入工厂类UserDAOFactory之后的结构如图1所示:
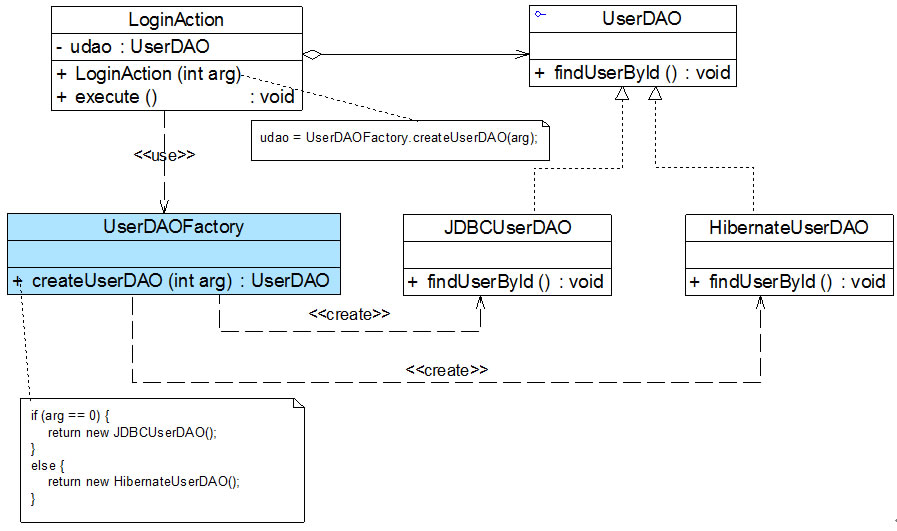
图1 引入工厂类之后的结构图
工厂类的引入将降低因为产品或工厂类改变所造成的维护工作量。如果UserDAO的某个子类的构造函数发生改变或者要需要添加或移除不同的子类,只要维护UserDAOFactory的代码,而不会影响到LoginAction;如果UserDAO的接口发生改变,例如添加、移除方法或改变方法名,只需要修改LoginAction,不会给UserDAOFactory带来任何影响。
在所有的工厂模式中,我们都强调一点:两个类A和B之间的关系应该仅仅是A创建B或是A使用B,而不能两种关系都有。将对象的创建和使用分离,也使得系统更加符合“单一职责原则”,有利于对功能的复用和系统的维护。
此外,将对象的创建和使用分离还有一个好处:防止用来实例化一个类的数据和代码在多个类中到处都是,可以将有关创建的知识搬移到一个工厂类中,这在Joshua Kerievsky的《重构与模式》一书中有专门的一节来进行介绍。因为有时候我们创建一个对象不只是简单调用其构造函数,还需要设置一些参数,可能还需要配置环境,如果将这些代码散落在每一个创建对象的客户类中,势必会出现代码重复、创建蔓延的问题,而这些客户类其实无须承担对象的创建工作,它们只需使用已创建好的对象就可以了。此时,可以引入工厂类来封装对象的创建逻辑和客户代码的实例化/配置选项。
使用工厂类还有一个“不是特别明显的”优点,一个类可能拥有多个构造函数,而在Java、C#等语言中构造函数名字都与类名相同,客户端只能通过传入不同的参数来调用不同的构造函数创建对象,从构造函数和参数列表中也许大家根本不了解不同构造函数所构造的产品的差异。但如果将对象的创建过程封装在工厂类中,我们可以提供一系列名字完全不同的工厂方法,每一个工厂方法对应一个构造函数,客户端可以以一种更加可读、易懂的方式来创建对象,而且,从一组工厂方法中选择一个意义明确的工厂方法,比从一组名称相同参数不同的构造函数中选择一个构造函数要方便很多。如图2所示:

那么,有人可能会问,是否需要为设计中的每一个类都配备一个工厂类?答案是:具体情况具体分析。如果产品类很简单,而且不存在太多变数,其构造过程也很简单,此时无须为其提供工厂类,直接在使用之前实例化即可,例如Java语言中的String类,我们就无须为它专门提供一个StringFactory,这样做反而有点像杀鸡用牛刀,大材小用,而且会导致工厂泛滥,增加系统的复杂度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号