

跳跃表
转自:https://www.61mon.com/index.php/archives/222/
一. 背景
跳跃表(英文名:Skip List),于 1990 年 William Pugh 发明,是一个可以在有序元素中实现快速查询的数据结构,其插入,查找,删除操作的平均效率都为 O(logn)。
跳跃表的整体性能可以和二叉查找树(AVL 树,红黑树等)相媲美,其在 Redis 和 LevelDB 中都有广泛的应用。
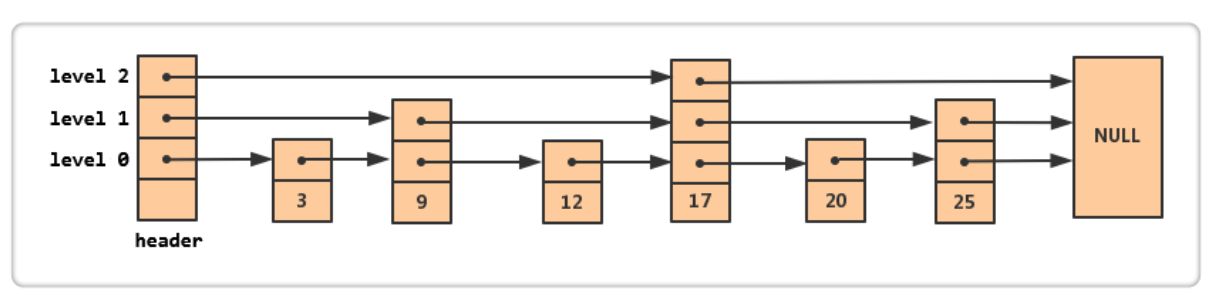
每个结点除了数据域,还有若干个指针指向下一个结点。
整体上看,Skip List 就是带有层级结构的链表(结点都是排好序的),最下面一层(level 0)是所有结点组成的一个链表,依次往上,每一层也都是一个链表。不同的是,它们只包含一部分结点,并且越往上结点越少。仔细观察你会发现,通过增加层数,从当前结点可以直接访问更远的结点(这也就是 Skip List 的精髓所在),就像跳过去一样,所以取名叫 Skip List(跳跃表)。
二. 过程分析
先来看下跳跃表的整体代码结构:
#define P 0.25
#define MAX_LEVEL 32
struct Node
{
int key;
Node ** forward;
Node(int key = 0, int level = MAX_LEVEL)
{
this->key = key;
forward = new Node*[level];
memset(forward, 0, level * sizeof(Node*));
}
};
class SkipList
{
private:
Node * header;
int level;
private:
int random_level();
public:
SkipList();
~SkipList();
bool insert(int key);
bool find(int key);
bool erase(int key);
void print();
};
2.1 插入
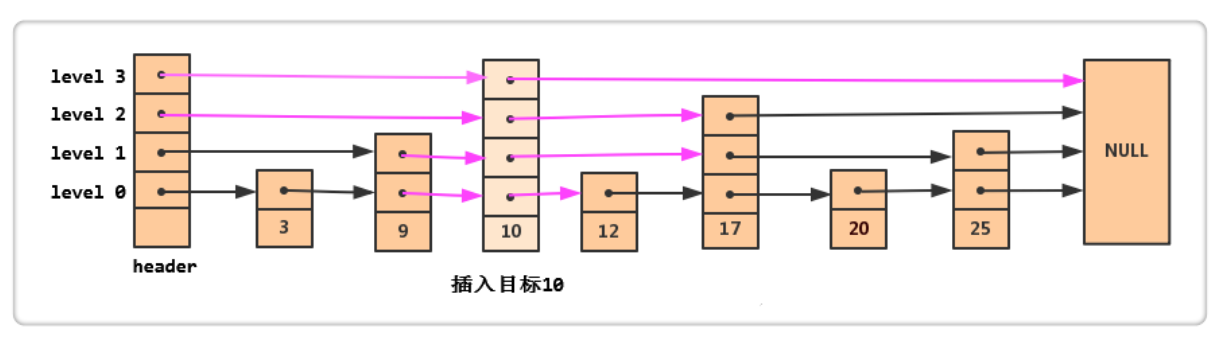
首先,我们要找到 10 在每一层应该被插入的位置,因此需要一个临时数组update[]来记录位置信息。
其次,我们要确定结点 10 的层数(结点 9 的层数为 2,结点 12 的层数为 1)。
理想的跳跃表结构是:第一层有全部的结点,第二层有 12 的结点,且是均匀间隔的,第三层有 14 的结点,且也是均匀间隔的...,那么整个表的层数就是 logn。每一次插入一个新结点时,最好的做法就是根据当前表的结构得到一个合适的层数,插入后可以让跳跃表尽量接近理想的结构,但这在实现上会非常困难。Pugh 的论文中提出的方法是根据概率随机为新结点生成一个层数,具体的算法如下:
-
给定一个概率 p(p 小于 1),产生一个 [0,1) 之间的随机数;
-
如果这个随机数小于 p,则层数加 1;
-
重复以上动作,直到随机数大于概率 p(或层数大于程序给定的最大层数限制)。
虽然随机生成的层数会打破理想结构,但这种结构的期望复杂度依旧是 O(logn),稍后文尾会给出证明。
最后,把结点 10 和它的前后结点连起来就行了。
int SkipList::random_level()
{
int level = 1;
while ((rand() & 0xffff) < (P * 0xffff) && level < MAX_LEVEL)
level++;
return level;
}
bool SkipList::insert(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
memset(update, 0, MAX_LEVEL * sizeof(Node*));
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
node = node->forward[0];
if (node == nullptr || node->key != key)
{
int new_level = random_level();
if (new_level > level)
{
for (int i = level; i < new_level; i++)
update[i] = header;
level = new_level;
}
Node * new_node = new Node(key, new_level);
for (int i = 0; i < new_level; i++)
{
new_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = new_node;
}
return true;
}
return false;
}
2.2 查找
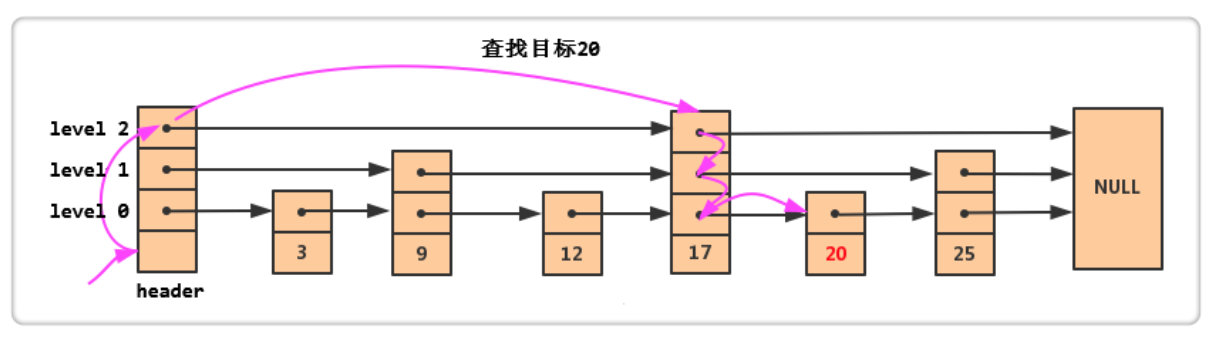
查找操作很简单,例如上图,现要查找 20,
-
从最高层开始找,
17 < 20,继续往后,发现是NULL,则往下一层继续查找; -
25 > 20,则往下一层继续查找; -
找到 20。
bool SkipList::find(int key)
{
Node * node = header;
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key <= key)
node = node->forward[i];
if (node->key == key)
return true;
}
return false;
}
2.3 删除
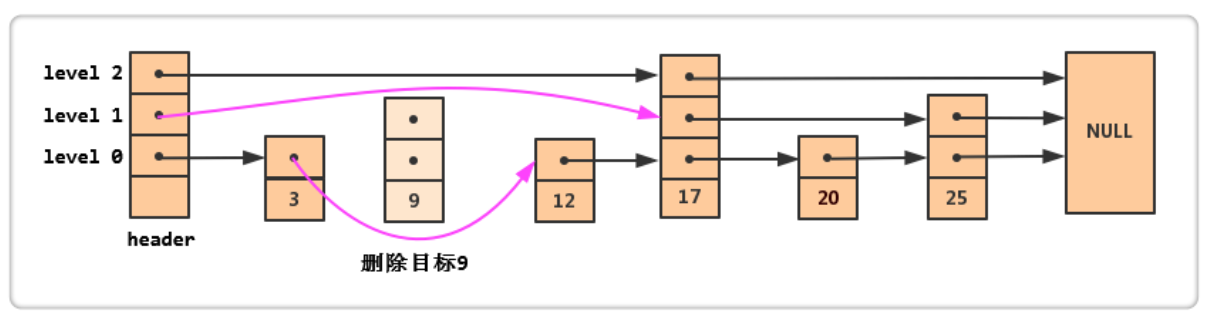
删除操作跟插入操作类似。 首先找到我们要删除结点的位置,在查找时使用临时空间来记录结点在每一层的位置,接着就是逐层的链表删除操作。 最后记住要释放空间。 删除结点之后,如果最高层没有结点存在,那么相应的,跳跃表的层数就应该降低。
bool SkipList::erase(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
fill(update, update + MAX_LEVEL, nullptr);
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
node = node->forward[0];
if (node && node->key == key)
{
for (int i = 0; i < level; i++)
if (update[i]->forward[i] == node)
update[i]->forward[i] = node->forward[i];
delete node;
for (int i = level - 1; i >= 0; i--)
{
if (header->forward[i] == nullptr)
level--;
else
break;
}
}
return false;
}三. 完整代码
#include <iostream>
#include <cstdlib>
#include <cstring>
#define P 0.25
#define MAX_LEVEL 32
using namespace std;
struct Node
{
int key;
Node ** forward;
Node(int key = 0, int level = MAX_LEVEL)
{
this->key = key;
forward = new Node*[level];
memset(forward, 0, level * sizeof(Node*));
}
};
class SkipList
{
private:
Node * header;
int level;
private:
int random_level();
public:
SkipList();
~SkipList();
bool insert(int key);
bool find(int key);
bool erase(int key);
void print();
};
int SkipList::random_level()
{
int level = 1;
while ((rand() & 0xffff) < (P * 0xffff) && level < MAX_LEVEL)
level++;
return level;
}
SkipList::SkipList()
{
header = new Node;
level = 0;
}
SkipList::~SkipList()
{
Node * cur = header;
Node * next = nullptr;
while (cur)
{
next = cur->forward[0];
delete cur;
cur = next;
}
header = nullptr;
}
bool SkipList::insert(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
memset(update, 0, MAX_LEVEL * sizeof(Node*));
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
node = node->forward[0];
if (node == nullptr || node->key != key)
{
int new_level = random_level();
if (new_level > level)
{
for (int i = level; i < new_level; i++)
update[i] = header;
level = new_level;
}
Node * new_node = new Node(key, new_level);
for (int i = 0; i < new_level; i++)
{
new_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = new_node;
}
return true;
}
return false;
}
bool SkipList::find(int key)
{
Node * node = header;
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key <= key)
node = node->forward[i];
if (node->key == key)
return true;
}
return false;
}
bool SkipList::erase(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
fill(update, update + MAX_LEVEL, nullptr);
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
node = node->forward[0];
if (node && node->key == key)
{
for (int i = 0; i < level; i++)
if (update[i]->forward[i] == node)
update[i]->forward[i] = node->forward[i];
delete node;
for (int i = level - 1; i >= 0; i--)
{
if (header->forward[i] == nullptr)
level--;
else
break;
}
}
return false;
}
void SkipList::print()
{
Node * node = nullptr;
for (int i = 0; i < level; i++)
{
node = header->forward[i];
cout << "Level " << i << " : ";
while (node)
{
cout << node->key << " ";
node = node->forward[i];
}
cout << endl;
}
cout << endl;
}
int main()
{
SkipList sl;
// test "insert"
sl.insert(3);
sl.insert(9);
sl.insert(1); sl.insert(1);
sl.insert(4);
sl.insert(2); sl.insert(2);
sl.insert(5);
sl.insert(6);
sl.insert(7);
sl.insert(8);
sl.insert(10);
sl.insert(11);
sl.insert(12);
sl.print();
// test "find"
cout << sl.find(50) << endl;
cout << sl.find(2) << endl;
cout << sl.find(7) << endl << endl;
// test "erase"
sl.erase(1);
sl.print();
sl.erase(10);
sl.print();
sl.erase(11);
sl.print();
return 0;
}运行如下(注意:结点层数采用的是随机值,故不同电脑可能会有不同的运行结果):

四. 效率分析与证明
首先回顾下插入操作中随机生成层数的函数:
#define P 0.25
#define MAX_LEVEL 32
int SkipList::random_level()
{
int level = 1;
while ((rand() & 0xffff) < (P * 0xffff) && level < MAX_LEVEL)
level++;
return level;
} 下文中我们用小写的p来代替上述代码大写的常量P。
1. 查找的期望时间复杂度
设 T(n) 表示 n 个结点的跳跃表中查找的期望路径长度。
它分为三部分:
-
第 1 层至最高层构成的跳跃表中查找的期望路径长度。此部分相当于一个期望规模为 O(pn) 的跳跃表的期望路径长度;
-
从第 1 层下降至第 0 层的一条指针;
-
在第 0 层右行的路径长度。每次能够右行的概率为 1−p。
于是:
解函数得到:
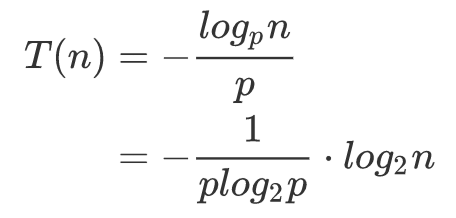
2. 单一结点的期望层数
-
结点层数恰好等于 1 的概率为 1−p;
-
结点层数恰好等于 2 的概率为 p(1−p);
-
结点层数恰好等于 3 的概率为 p2(1−p);
-
......
那么一个结点的期望层数计算如下:
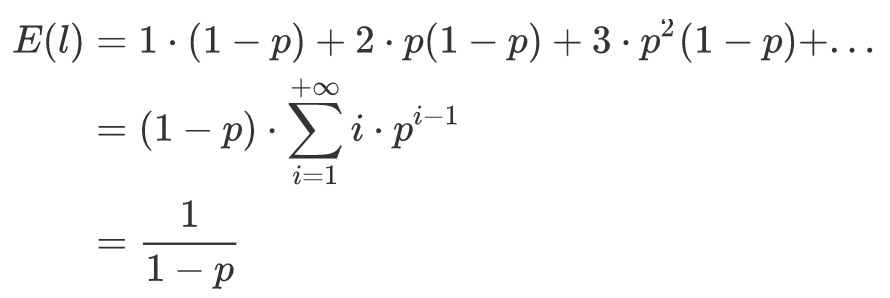
3. 期望空间复杂度
对于一个有 n 个结点的跳跃表,其期望空间复杂度为:
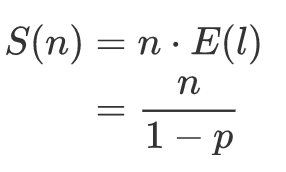
4. 最大层数分析
设最大层数为 h,则 h 不超过 m 的概率为:
当没有最高层限制的时候(即 h→+∞)才是真正的 Skip List,但是实际应用中为了程序实现简单,往往设置这样一个常数 h。根据刚才对最高层概率的分析,我们可以选取一个适当的 h。比如,对于 ,p=1/4,n=106 时,取 h=16 就是一个不错的选择(个人觉得,参照 BST 来,直接取 h=log2n 就可以)。此时
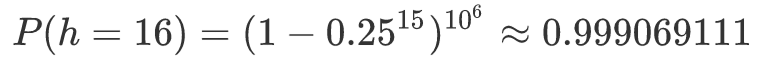
根据上述第 1 点所求的查找时间复杂度,进一步化简:
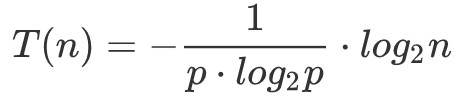
我们只需讨论左边的表达式即可,

对其求导可得以下信息:
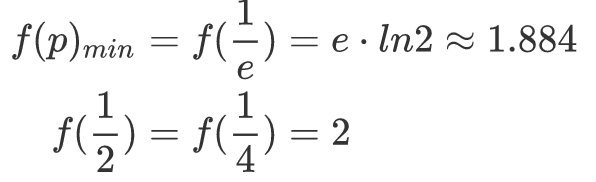
针对 p=1/e,1/2,1/4,绘制的综合分析表格如下:
| p | 空间复杂度 | 时间复杂度 |
|---|---|---|
| 1/e | O(1.58n) | O(1.88log2n) |
| 1/2 | O(2n) | O(2log2n) |
| 1/4 | O(1.33n) | O(2log2n) |
从时空权衡来看,1/e 和 1/4 是比较好的选择。
Redis 使用的后者,我在 Redis 的 Pull Request 上发现有人 pull 了一条 request:Change skip list P value to 1/e, which improves search times,但最终能否被采用还是未知数。

