Fuel插件InfluxDB-Grafana Server(0.7.0) Server安装部署指南
The InfluxDB-Grafana Server Plugin
LMA工具链包括与InfluxDB结合的Grafana来支持度量分析功能。InfluxDB-Grafana插件安装了一系列预先配置的仪表板,专门为Mirantis OpenStack监控设计。但是,很重要的一点是要理解,使用插件来安装InfluxDB和Grafana比LMA工具链的要求更容易启动。因此,LMA收集器的配置也提供了支持:
●指定主机名(或IP地址)的一个InfluxDB服务器(或服务器集群)已经安装在数据中心或,
●指定一个节点名baseos角色安装InfluxDB和Grafana OpenStack的环境。
InfluxDB是写在Go语言上,没有外部依赖关系。它的设计是横向的,但目前安装的版本更适合作为独立的服务器运行。底层存储引擎基于默认的LevelDB引擎。与Grafana相结合的InfluxDB提供了一个灵活的、功能丰富的、度量分析和图形编辑器系统到可视化的OpenStack的度量时间序列(time-series)。为了帮助您入门,这个插件安装了超过十个不同的预先配置的仪表板,您可以使用它来访问大量的操作数据,包括服务检查、使用和性能指标。收集到的度量指标的完整列表可以在StackForge上的LMA收集器插件repo中找到,我们也会定期导出到readthedocs.org。
Requirements
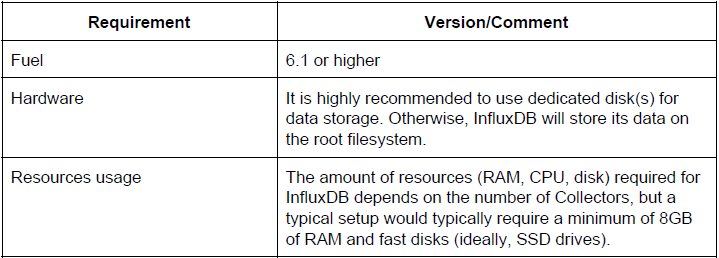
Limitations
该插件只与使用Neutron作为网络配置部署的OpenStack环境兼容。
Installation Guide
如前所述,您可以使用Fuel插件或单独安装InfluxDB和Grafana,只要您满足上面的要求,在这种情况下就不需要InfluxDB-Grafana插件安装。您只需要遵循安装LMA收集器插件的说明。
Install the plugin on the Fuel Master Node
要在Fuel主节点上安装有影响的- grafana插件,请遵循以下步骤:
- 从Fuel插件目录中下载插件的rpm文件。
- 将rpm文件复制到Fuel主节点:
[root@home ~]# scp influxdb_grafana-0.7-0.7.0-0.noarch.rpm root@<Fuel Master node IP address>:/tmp
- 使用Fuel的CLI安装插件:
[root@fuel ~]# fuel plugins plugins --install /tmp/influxdb_grafana-0.7-0.7.0-0.noarch.rpm
- 验证插件安装正确:
[root@fuel ~]# fuel plugins id | name | version | package_version ---|----------------------|---------|---------------- 1 | influxdb_grafana | 0.7 . 0 | 2.0 . 0
要安装LMA收集器插件,请遵循LMA收集器插件指南的说明。
Plugin Configuration
配置InfluxDB-Grafana插件,请执行以下步骤:
1、使用Fuel UI向导创建一个新环境。
2、单击“设置”选项卡并向下滚动,直到到达InfluxDB-Grafana插件部分。
3、选择InfluxDB-Grafana插件复选框并填写配置参数,如下图所示: 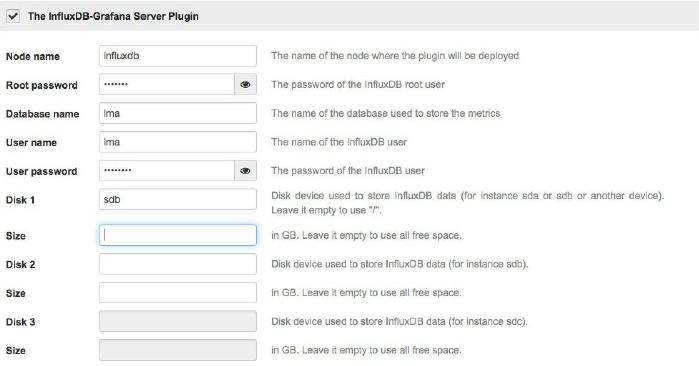
- 惟一需要填写的字段是“节点名”字段。所有其他字段要么是可选的,要么是与默认值相关联的。您应该输入“节点名”字段,在部署期间将安装有影响的节点和Grafana的名称。例如“influxdb”。参见下面的节点设置说明。
- InfluxDB管理密码(在InfluxDB文档中称为根密码)应该从默认值更改
- 您还可以为InfluxDB指定至多三个磁盘创建数据库。插件将自动在这些磁盘上创建一个逻辑卷。如果要分区磁盘,还可以在“size”字段中指定分配大小。如果没有指定大小,则插件将创建一个逻辑卷,以获取所有可用的磁盘空间。如果没有指定磁盘,那么将在根文件系统上创建有影响的数据库。
4、选择日志、监视和警报(LMA)收集器插件复选框,并填写“Metrics Analytics”部分,如下图所示。关于LMA收集器的进一步说明,请检查收集器插件用户指南
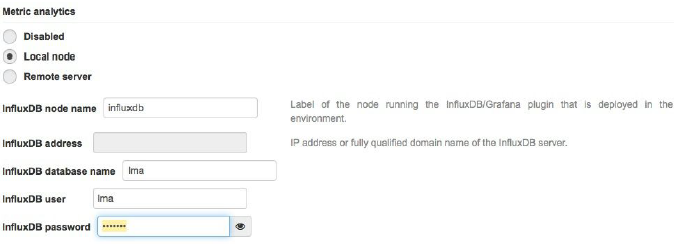
5、单击页面底部的Save设置保存配置参数。
6、单击“节点”选项卡
7、然后切换到Nodes选项卡,添加一个带有base_os角色的节点。
8、在部署任何更改之前,通过单击“Untitled (xx:yy)”并将其修改为“influxdb”,编辑base_os节点的名称。
9、向下滚动“网络”页面并验证你的网络。
10、最后部署您的更改。
Plugin Install Verification
根据节点的数量和设置的复杂性,部署一个新的Mirantis OpenStack环境通常需要30分钟到几个小时。一旦您的环境被成功部署,您应该在Fuel UI中收到一个类似这样的通知。

当前Fuel插件框架的一个限制是,不可能显示包含动态信息的通知,比如Grafana服务器的URL。这一限制将在下一个版本的Mirantis OpenStack中得到修复,但是同时您将不得不使用燃料命令行来检索这些信息。
[ root@fuel ~] # fuel nodes id | status | name | cluster | ip | […] | roles ---|--------|----------------------|---------|-------------| |------ 1 | ready | influxdb | 1 | 10.20 . 0.3 | | base - os 6 | ready | Untitled ( 55 : b3 ) | 1 | 10.20 . 0.7 | | ceph - osd , compute 3 | ready | Untitled ( 73 : 19 ) | 1 | 10.20 . 0.5 | | controller 4 | ready | Untitled ( 1c : 5c ) | 1 | 10.20 . 0.6 | | controller 5 | ready | Untitled ( 75 : 35 ) | 1 | 10.20 . 0.8 | | ceph - osd , compute 2 | ready | Untitled ( ec : a2 ) | 1 | 10.20 . 0.4 | | controller
上面的命令行输出告诉您,在node1上已经部署了 InfluxDB-Grafana服务器,IP地址是10.20.0.3。
为了验证InfluxDB正在正常运行,请使用以下步骤。
1、InfluxDB的内置用户接口默认运行在8083端口上,使用您在上面的配置文件中定义的“root”用户名及“Root password”密码登录WEB界面,您将看到如下界面:

2、请继续点击“Explore”链接,获取“lma”数据库:

3、然后,获取到目前为止收集的timeseries列表。
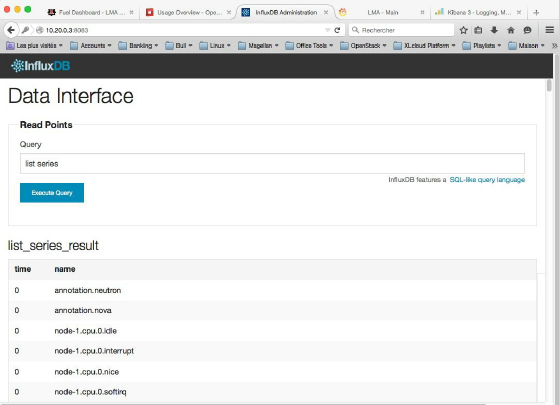
到目前为止,您应该得到LMA收集器收集的相当长的timeseries列表。
User Guide
Exploring the Data with Grafana
Grafana用户界面运行在端口80或8000上,这取决于是否在同一节点上安装了InfluxDB-Grafana插件和Elasticsearch-Kibana服务器插件。在这个示例中,Grafana用户接口在端口8000上运行。将浏览器指向URL http://10.20.0.38000 /您应该可以看到这样的屏幕:
这是Grafana的家庭仪表板,我们也称它为主要的仪表板。
但是,在您可以有效地使用插件提供的任何一个Grafana指示板之前,您需要使用在仪表板中定义的timeseries的变量部分来初始化所有的模板。例如,$controller是timeseries符号$controller.memory的变量。需要用控制器节点名替换它来查询影响。如果您遵循,Grafana模板就会自动执行该操作。
以下是为了定义所有的仪表盘使用变量的步骤,让我们从主仪表盘开始:
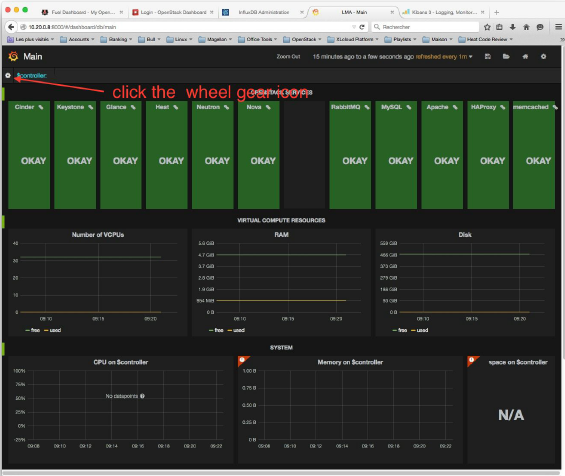
1、击“车轮齿轮图标”,选择“模板”。你应该看到这样的东西

2、然后单击Edit以访问timeseries定义。

3、你应该看到这样的东西。
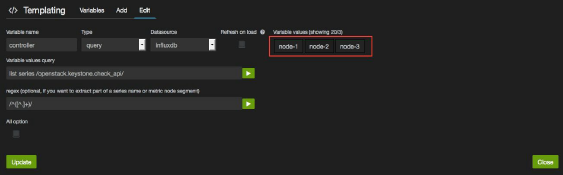
4、现在,模板被初始化为一个值列表,该列表的值对应于从影响查询中检索的控制器列表:
list series /openstack.keystone.check_api/
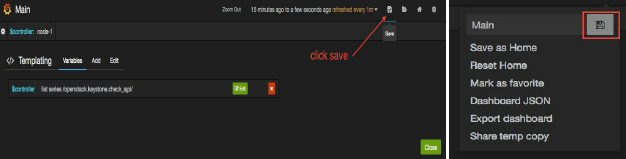
5、如下图所示点击“更新”保存配置,最后单击“关闭”
6、现在您的主仪表板应该有一个下拉菜单列表,从这里可以选择您想要显示timeseries的控制器。
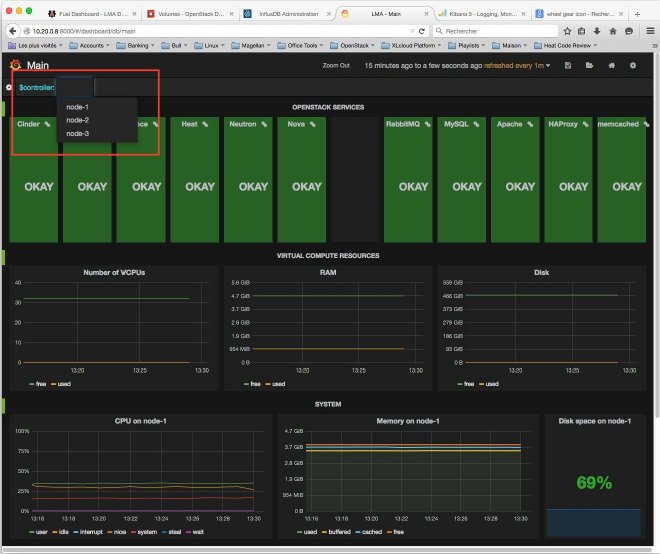
主指示板给出了OpenStack环境当前健康状态的概述。
1、 在“OpenStack服务”行中,每个被监视的服务可以有四个不同的状态(OK,警告,失败或未知)。当一个或多个服务端点、工作人员或代理被检测到失败时,但是该服务总体上仍然可用(尽管可能被降级)来处理用户请求时,服务被声明为警告。当对服务API端点(通过HA Proxy VIP)的合成检查超时,或者当检测到所有参与提供服务(如计算或存储)的人员和/或代理被检测失败时,服务被宣告失败。如果在HA集群中检测到所有的Nova调度程序和/或指挥人员都失败了,那么就会出现这种情况。
2、“虚拟计算资源”行概述了计算节点上使用的虚拟资源的数量,包括虚拟cpu数量、内存使用量、磁盘空间,以及创建新实例所需的虚拟资源数量。
3、“系统”行给出了控制器在基础结构中使用的物理资源数量的相同概述。您可以选择一个特定的控制器视图,使用控制器的下拉列表在工具栏的左边。
4、“Ceph”行提供了Ceph集群的资源使用情况和当前健康状态的概述。
主仪表板还允许您访问正在监视的每个OpenStack服务的更详细的timeseries指示板。例如,如果您点击Nova框,您应该会看到如下内容:
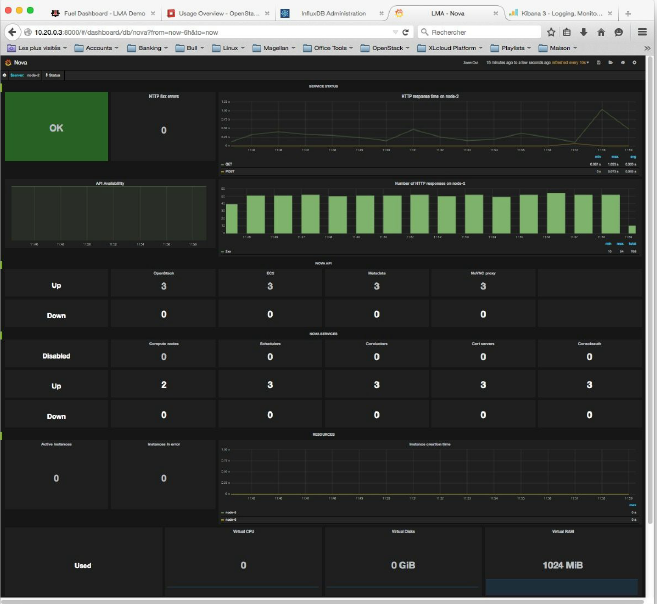
1、“服务状态”行提供了关于Nova服务健康状态的信息,包括服务API前端的状态(HAProxy VIP)、HTTP 5xx错误的计数、HTTP请求响应时间的历史和HTTP状态代码。
2、“Nova API”行提供了关于Nova服务端点的状态的信息(novaapi,ec2api,…实例)、工作人员状态和计算节点。
3、“资源”行提供了各种资源使用指标和性能统计数据,例如平均实例创建时间。
其他OpenStack服务有相同的详细指示板。InfluxDB-Grafana服务器插件有13个不同的指示板,可以从目录中选择,如下图所示。

最后,全局仪表板InfluxDB-Grafana插件提供了另一种称为“系统”仪表板,您可以使用它们来获得OpenStack节点和操作系统统计timeseries。这个指示板看起来是这样的
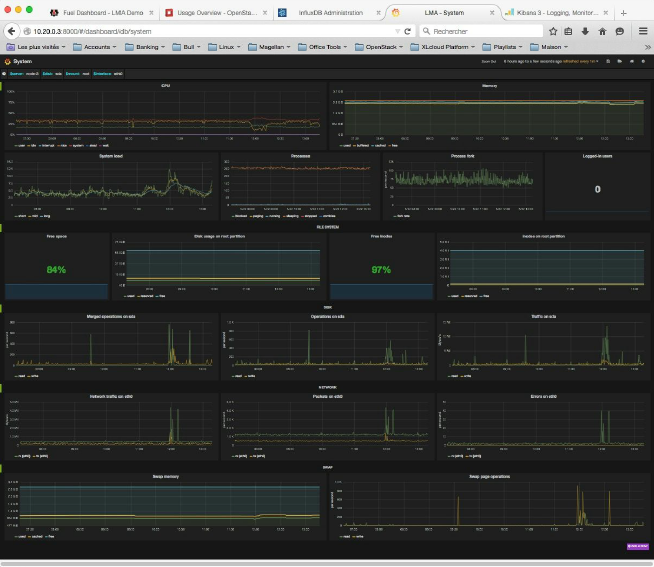
1、在工具栏的左侧,您可以选择要访问的节点,并从各自的下拉列表中选择磁盘、文件系统和网络接口timeseries。
Viewing Failures and Annotations with Grafana
LMAToolchain能够检测许多服务,比如服务端点、工作人员或代理的故障。这些条件在Grafana中显示的注释和服务的整体健康状态都有报告。让我们考虑一个情况,即所有的Cinder服务API端点都失败了。Cinder指示板将会报告如下图所示的情况。
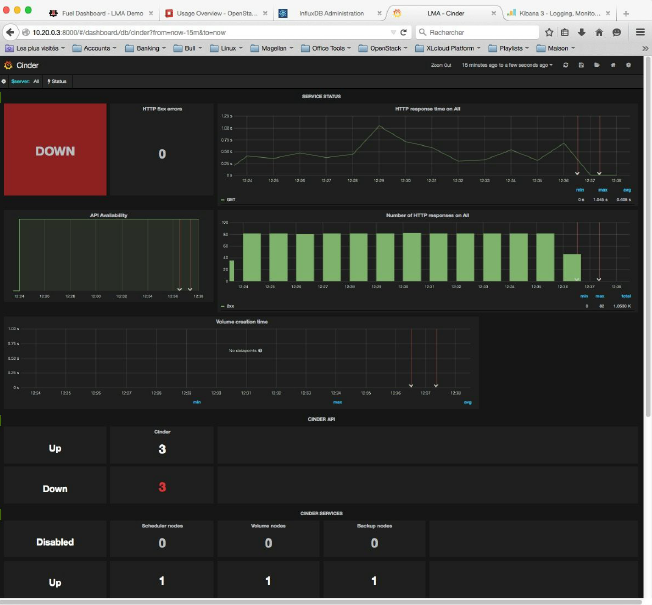
1、由于HA集群中所有的三个服务API端点都在下降,因此将Cinder服务作为一个整体进行报告。因此,不需要使用服务来处理Cinder用户请求。
2、此外,LMA收集器的异常检测能力可以推断出Cinder服务状态变化的“根本原因”,从OK到DOWN,可以在仪表板的右上角看到注释。
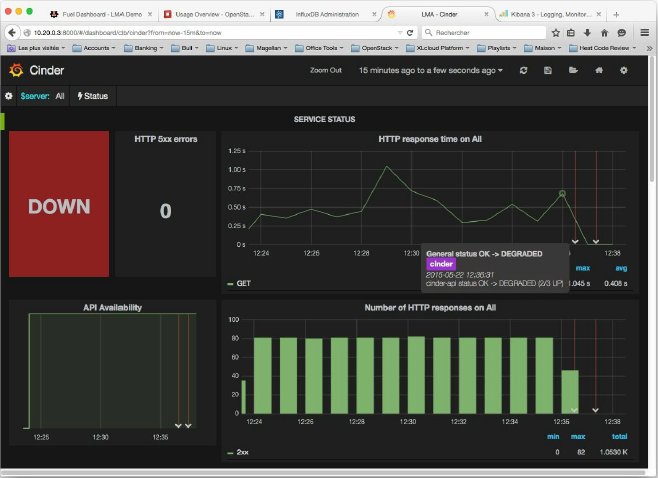
a.第一个注释说,最初Cinder服务将一个状态从OK改为DEGRADED,因为三个服务API端点中只有两个被报告了。
b.然后,第二个注释说,最后,Cinder服务将一个状态从DEGRADED到DOWN,因为,这一次,三个服务API端点中的三个被报告了下来。
Troubleshooting
如果在仪表板中没有数据,请使用下面的说明来排除问题:
1、检查LMA收集器服务是否已启动并运行:
# On CentOS /etc/init.d/lma_collector status # On Ubuntu status lma_collector
2、如果LMA收集器关闭,请重新启动它:
# On CentOS /etc/init.d/lma_collector start # On Ubuntu start lma_collector
3、在不同的节点上查找LMA收集器日志文件中的错误(位于/var/log/lma_collector中)。
4、检查节点是否能够连接到端口8086上的InfluxDB服务器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号