
Kubernetes in Action 笔记二
Volume 介绍
Kubernetes 通过定义 Volume 来满足这个需求,Volume 被定义为 Pod 这类顶级资源的一部分,并和 Pod 共享生命周期。
- 容器重启都不会影响卷的内容,如果一个 Pod 内包含多个容器,多个容器共享此卷。
- 非持久卷只能实现容器级别,无法实现Pod级别的共享与复用
- 持久卷(Persistent Volumes),可以把存储和计算分离开来,通过不同的组件来管理存储资源和计算资源,然后解耦pod和Volume之间生命周期的关联,实现Pod级别共享与复用。
Volume 类型
- emptyDir: 用于存储临时数据的空目录,只能作为临时数据存储,不过利用容器共享卷的这一特性,在 Pod 的多个容器中共享文件还是很有效的。
- hostPath: 用于将工作节点的目录挂载到 Pod 中,只是将持久化数据放到工作节点的存储介质中,一般用作系统级别Pod如DaemonSet。
- 属于持久性存储卷,pod删除后卷不会被删除
- Pod通常使用hostPath来访问节点上的日志文件,kubeconfig或者CA证书
- 但是如果Pod被调度到别的节点上后,就不能访问原来挂载在工作节点上的数据了
- gitRepo: 通过检出 Git 仓库内容来初始化的挂载卷,是 emptyDir 的进化版,它通过克隆一个 Git 仓库的特定分支版本来初始化目录的内容,pod重启后不可用。
- nfs: 用于挂载 nfs 共享卷到 Pod 中
- configMap、secret、downwardAPI: K8S 内置的用于持久化存储的特殊类型资源
- persistentVolumeClaim: K8S 的持久存储类型
- gcePersistentDisk: 谷歌高效磁盘存储卷
- awsElasticBlockStore: 亚马逊弹性块型存储卷
注意:
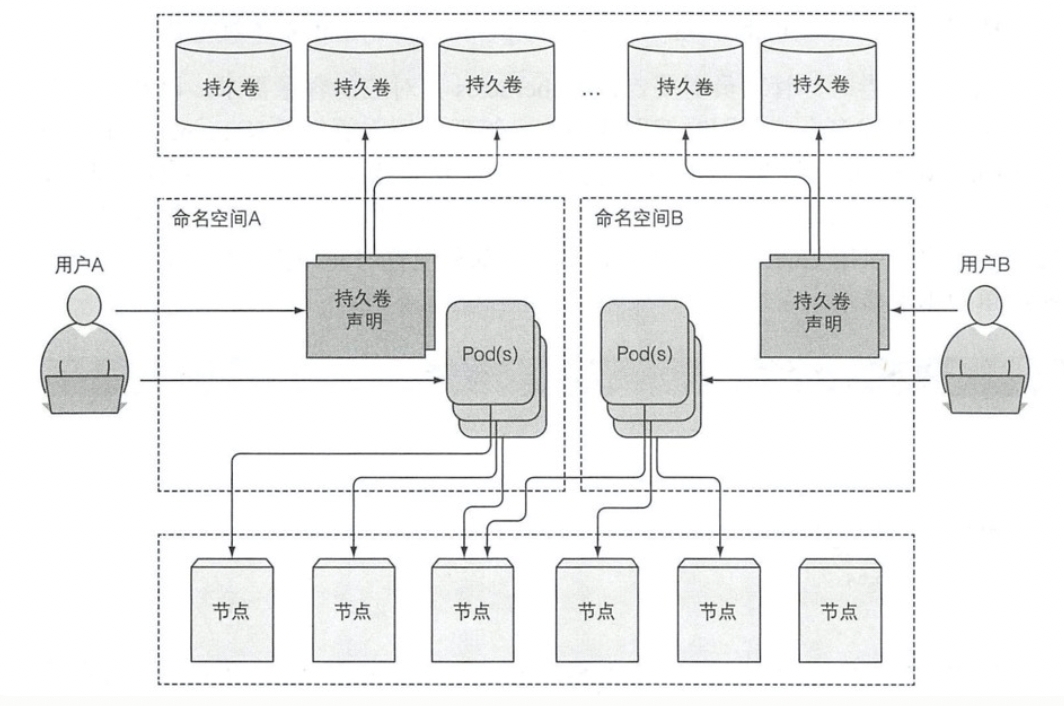
PV不属于任何命名空间,属于控制平面层级的资源,而PVC和pod一样,都要属于某个命名空间,
引入PV和PVC的目的是为了解耦Pod与底层的存储技术,研发人员不需要关心底层究竟使用哪种技术作为存储后端,这部分是由集群管理员来做的.
介绍持久卷与持久卷声明
- PV和Node是资源的提供者
- PVC和Pod是资源的使用者
为什么要引入PVC?
- 职责分离,PVC中只用声明自己需要的存储size,access mode(节点独占还是共享,只读还是读写访问),开发者不需要关心存储需求,PV和对应后端存储信息交给cluster admin统一运维和管控
- PVC简化了User对存储的需求,PV才是存储的实际信息的承载体,通过kube-controller-manager的PersistentVolumeController把PVC与合适的PV绑定在一起,从而满足User对存储的实际需求。
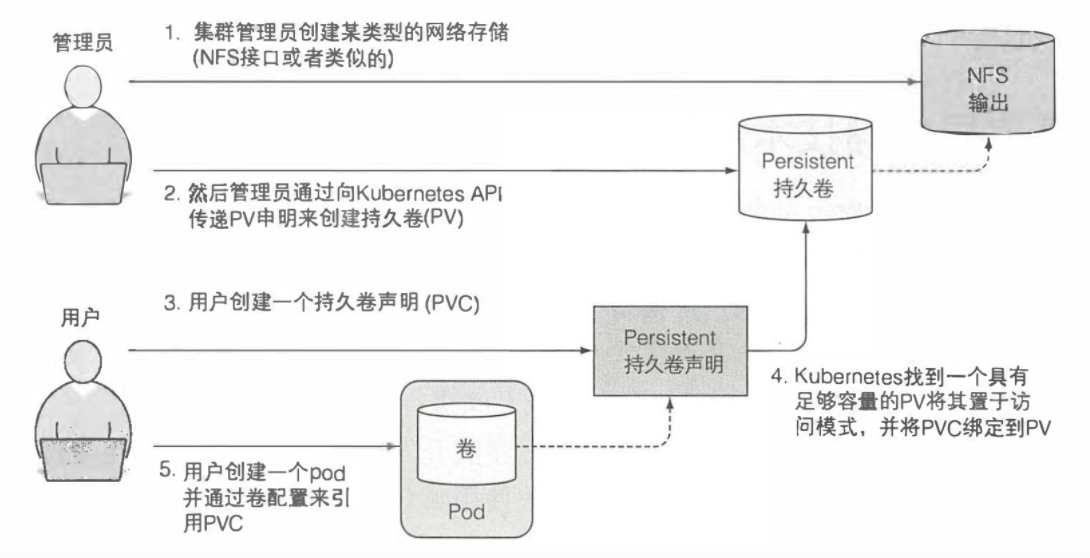
具体使用:
- 集群管理员设置底层存储
- 通过K8s API传递PV声明创建持久卷
- 用户创建持久卷声明
- K8s找到一个足够容量的PV并且将其置于访问模式,并且将PVC绑定到PV
- 用户创建一个pod并通过卷配置引用PVC
persistentVolumeReclaimPolicy:也有三种策略,这个策略是当与之关联的PVC被删除以后,这个PV中的数据如何被处理
- Retain 当删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV。
- Delete 当删除与之绑定的PVC时候,删除底层存储
accessModes:支持三种类型
- ReadWriteMany 多路读写,卷能被集群多个节点挂载并读写
- ReadWriteOnce 单路读写,卷只能被单一集群节点挂载读写
- ReadOnlyMany 多路只读,卷能被多个集群节点挂载且只能读
k8s里的持久化存储,总的分为两种,静态卷和动态卷。
- 静态卷就是刚才我们说的,volume挂载,或者通过手动创建pv,pvc进行挂载。都属于静态卷。
- 集群管理员事先规划这个集群的用户会怎样使用存储,即预分配一些存储,也就是预先创建一些PV
- Pod需要使用存储的时候,就可以通过PVC找到相应的PV,然后做绑定
- 动态卷,则是将一个网络存储作为一个StorageClass类,通过自己的配置,来动态的创建pv,pvc并进行绑定,这样就可以实现动态的存储生成与持久化保存。
静态卷:
为了使应用能够正常请求存储资源,同时避免处理基础设施细节,所以引入了持久卷和持久卷声明。
- 集群管理员只需要创建和管理某种存储介质。
- 然后创建 PV(PersistentVolume,持久卷)来抽象存储介质,此时可以设定存储大小和访问模式,PV 代理的存储能力会自动加入到 K8S 的资源池中。
- 当应用发布者需要使用持久卷时,只需创建一个 PVC(PersistentVolumeClaim,持久卷声明),指定所需的最小存储容量要求和访问模式。
- K8S 会自动找到可匹配的 PV,并绑定到此 PVC。
- 持久卷声明即可作为一个普通卷使用,并挂载到 Pod 上。
- 已经挂载的 PV 不能挂载在多个 PVC 上,只能等待之前的 PVC删除后释放,PV 才可以挂载到其他 PVC 上。
- 持久卷生命就像一个中间层抽象,使开发者的持久化工作更加简单,且对存储介质解耦,用户无需关注具体存储过程。
K8S 根据 PVC 申请的资源,去所有 PV 中找到能满足所有要求的 PV,然后两者绑定。
动态卷:
PV是由运维人员创建的,而PVC是由开发人员创建的,那么大规模集群中可能会有很多PV,如果这些PV都需要手动管理,将会十分繁琐,因此就有了动态供给概念,核心就是StorageClass,作用是创建PV模板。
集群管理员只需定义一个或多个 SC(StorageClass)资源,用户在创建 PVC 时就可以指定 SC,K8S 就会使用 SC 的置备程序(provisioner)自动创建 PV,如此这般就不需要集群管理员一个一个的创建 PV 了。
动态持久卷完整图例
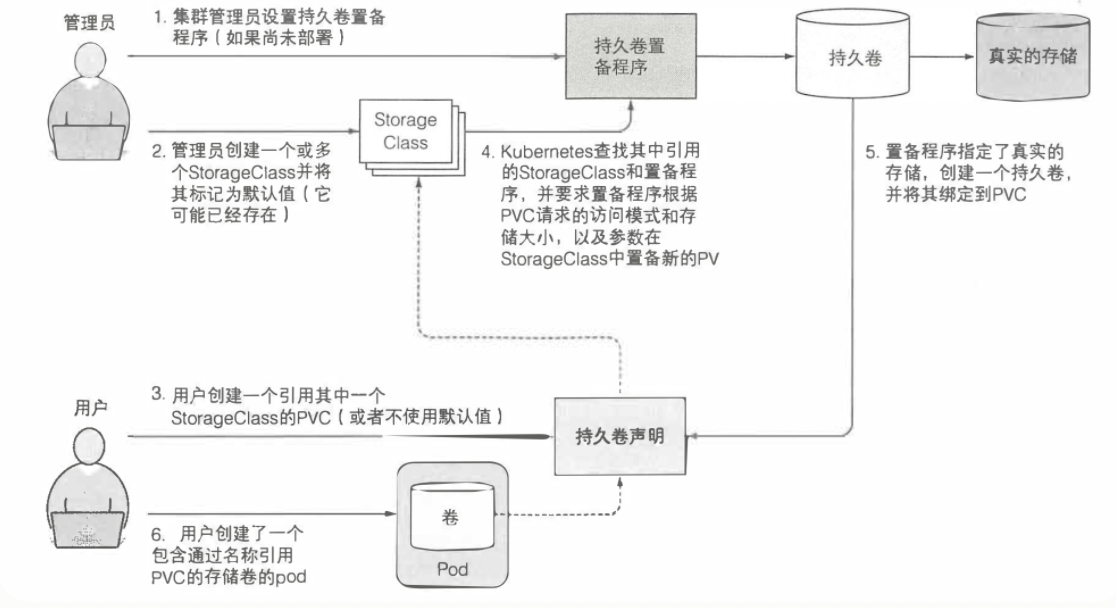
创建存储
用户提交完 PVC,由 csi-provisioner 创建存储,并生成 PV 对象,之后 PV controller 将 PVC 及生成的 PV 对象做 bound,bound 之后,create 阶段就完成了
存储挂载到节点上
用户在提交 pod yaml 的时候,首先会被调度选中某一个 合适的node,等 pod 的运行 node 被选出来之后,会被 AD Controller watch 到 pod 选中的 node,它会去查找 pod 中使用了哪些 PV。然后它会生成一个内部的对象叫 VolumeAttachment 对象,从而去触发 csi-attacher去调用csi-controller-server 去做真正的 attache 操作,attach操作调到云存储厂商OpenAPI。这个 attach 操作就是将存储 attach到 pod 将会运行的 node 上面。第二个阶段 —— attach阶段完成
将对应的PV进一步挂载到 pod 可以使用的路径
发生在kubelet 创建 pod的过程中,它在创建 pod 的过程中,首先要去做一个 mount,这里的 mount 操作是为了将已经attach到这个 node 上面那块盘,进一步 mount 到 pod 可以使用的一个具体路径,之后 kubelet 才开始创建并启动容器。这就是 PV 加 PVC 创建存储以及使用存储的第三个阶段 —— mount 阶段。
local PV
所谓 Local PV(本地持久化存储),指的就是利用机器上的磁盘来存放业务需要持久化的数据,和远端存储类似,此时数据依然独立于 Pod 的生命周期,即使业务 Pod 被删除,数据也不会丢失。
同时,和远端存储相比,本地存储可以避免网络 IO 开销,拥有更高的读写性能,所以分布式文件系统和分布式数据库这类对 IO 要求很高的应用非常适合本地存储。
目前,Local PV 的本地持久存储允许我们直接使用节点上的一块磁盘、一个分区或者一个目录作为持久卷的存储后端,但暂时还不提供动态配置支持,也就是说:你得先把 PV 准备好。
不同于其他类型的存储,本地存储强依赖于节点。
ConfigMap和Secret来配置应用
对容器化的应用配置,配置项的表现形式通常有
- 启动时的命令行参数
- 配置文件,使用configMap配置
- 环境变量,配置文件中设置env环境变量。
命令行方式:
$ docker run [--entrypoint entrypoint] image [cmd] [args]
ConfigMap
Kubernetes 允许将配置选项分离到单独的资源对象 ConfigMap 中,CM 本质上就是一个 KV 对。V 可以是短字面量,也可以是一个完整的配置文件。
应用无需知道 CM 存储的内容,甚至不需要知道这种资源的存在。CM 中的内容可以直接通过持久卷和环境变量的方式传递到容器中。
command 和 args 在 Pod 启动后无法就无法修改,但将 ConfigMap 暴露为卷是可以达到热更新效果的。
CM 被更新后,卷中引用他的所有文件也会相应更新(因为网络原因可能有延迟),进程发现文件改动(根据代码逻辑,不自动发现的需要手动通知)后会进行重载。但是热更新的耗时会出乎意料的长。
Secret 和 CM 类似,均是KV 存储,使用方式也类似,可以将 Secret 作为环境变量传递给容器,或者以卷的方式挂载。
Secret 只会存储在节点的内存中,永远不会写入物理存储。
CM 和 Secret 对比
当使用 kubectl get cm(secret) -o yaml 打印详细信息时,两者区别是:
- CM 直接纯文本展示内容存储内容
- Secret 的内容会被 Base64 格式编码打印(因为 Base64 编码可以涵盖二进制数据)
Downward API
Downward API 允许我们通过环境变量或挂载卷的方式传递 Pod 的元数据。
通过环境变量暴露pod元数据。
Downward API 仅可以获得 Pod 自身的元数据,还无法获得其他 Pod 的元数据信息甚至是集群的信息。
使用 ambassador 容器简化与 API 交互,、
在启动主容器的同时,启动一个 ambassador 容器,并在其中运行 $ kubectl proxy 命令来实现与 API 服务器的交互。
Deployment 升级应用
Deployment 是一种更高阶的资源,用于部署应用程序并以声明的方式升级应用,而不是直接通过 RC 或 RS 进行部署。
有了 RC,RS 为啥还需要 Deployment?
当应用服务使用 rolling-update 滚动升级时,需要协调另一个新建的 RC 不断增删来达到升级目的。而 Deployment 资源是在 K8S 控制层上运行控制器进程解决滚动升级问题。
优点: 支持声明时升级,回滚应用。
升级策略配置包括:maxSurge,maxUnavailable等。
StatefulSet 有状态的服务应用。
一些特殊情况下需要为每个Pod提供稳定唯一的网络标识。可以创建 StatefulSet 资源来代替 RS 运行此类 Pod,它是专门定制的一类应用,在 StatefulSet 中的每个实例都是不可替代的个体,且拥有稳定的名字和状态。如:和 RS 不同的是,它重新创建的 Pod 会和之前的 Pod 有完全一致的名称、主机名、存储卷。
- 在StatefulSet中也需要创建持久卷声明模板,那么在Pod创建之前,先创建这些PVC,然后再绑定到一个Pod实例上。
- 通过把Service的clusterIP设置为None,即Service为headless-service,可以使得StatefulSet里面的Pod都拥有独立的网络标识。
- 然后在StatefulSet的配置中要指定其对应哪一个Service
- 通常来说,无状态的 Pod 可以被替代,但有状态的 Pod 只能被消灭和复活。
扩缩容statefuleSet。
- 扩容一个 StatefulSet 会使用下一个还没有用到的顺序索引值创建一个新的 Pod 实例。缩容时也是会删除最高索引值的实例,使的扩容缩容的结果都是可预知的。
- 扩容一个实例,会创建一个 Pod 和对应的 PV、PVC 两三个资源。但当收缩一个实例时,则只会删除 Pod 而保留 PV、PVC,原因不必多说。
- 如果需要释放对应的 PV、PVC 要手动来完成,但并不建议这么做。
- 因为 StatefulSet 缩容的时候,每次只会操作一个 Pod 实例,所以有状态应用的缩容都会相对较慢。
- StatefulSet 在存在不健康实例的情况下是不允许缩容的
对比Replicaset
- Replicaset的每个Pod都会共享一个PVC,对应一个PV,没有办法使得其定义的所有副本都有一个单独的PVC
- 不能为每个Pod提供稳定的标志,例如某个pod删掉,重新再起一个pod,这个新的pod会有全新的主机名和IP
- Replicaset创建的pod都是随机生成的,即常见的podName+Hash,而Statefulset创建的pod都拥有规则的名称。
了解 Kubernetes 机理
我们学习的 Pod、RC、RS、CM 等等资源,都需要把 manifest 持久化以方便服务的重启和容灾。而 etcd 就是存放这些资源的 manifest 的地方。
etcd 是一个兼具一致性和高可用的分布式 K-V 数据库,它是保存 K8S 所有集群数据的后台数据库。通过抽离出单独存储,使的 K8S 的核心组件也可灵活组合。
etcd 在集群内的唯一客户端只有 API 服务器,其他组件只能通过 API 服务器代理来完成数据的修改,这样带来的好处就是 增强乐观锁(串行读写)和验证系统健壮性。
etcd 使用 RAFT一致性算法 来保证集群一致性。算法要求超过一半的法定节点参与投票才可以进行到下一个状态。所以我们希望 etcd 集群的实例数量尽可能是奇数。
2,容器
容器实际上是结合了namespace 和 cgroup 的一般内核进程,注意,容器就是个进程
所以,当我们使用Docker起一个容器的时候,Docker会为每一个容器创建属于他自己的namespaces,即各个维度资源都专属这个容器了,此时的容器就是一个孤岛,也可以说是一个独立VM就诞生了。当然他不是VM,网上关于二者的区别和优劣有一对资料.
更进一步,也可以将多个容器共享一个namespace,比如如果容器共享的是network 类型的namespace,那么这些容器就可以通过 localhost:[端口号] 来通信了。因为此时的两个容器从网络的角度看,和宿主机上的两个内核进程没啥区别。
kubernetes的pod
根据前面的描述我们知道,多进程/多容器可以共享namespace,而k8s的pod里就是有多个容器,他的网络实现原理就是先创建一个共享namespace,然后将其他业务容器加入到该namespace中。
k8s会自动以"合适"的方式为他们创建这个共享namespace,这正是"pause"容器的诞生。
pause容器:创建的每一个pod都会随之为其创建一个所谓的"父容器"。其主要由两个功能:
- (主要)负责为pod创建容器共享命名空间,pod中的其他业务容器都将被加入到pause容器的namespace中
- (可选) 负责回收其他容器产生的僵尸进程,此时pause容器可以看做是PID为1的init进程,它是所有其他容器(进程)的父进程。但在k8s1.8及以后,该功能缺省是关闭的(可通过配置开启)
