zookeeper watch笔记
ZK其核心原理满足CP, 实现的是最终一致性, 它只保证顺序一致性.
zookeeper 基于 zxid 以及阻塞队列的方式来实现请求的顺序一致性。如果一个client连接到一个最新的 follower 上,那么它 read 读取到了最新的数据,
然后 client 由于网络原因重新连接到 zookeeper 节点,而这个时候连接到一个还没有完成数据同步的 follower 节点,那么这一次读到的数据不久是旧的数据吗?
实际上 zookeeper 处理了这种情况,client 会记录自己已经读取到的最大的 zxid,如果 client 重连到 server 发现 client 的 zxid 比自己大连接会失败
ZK 选举机制
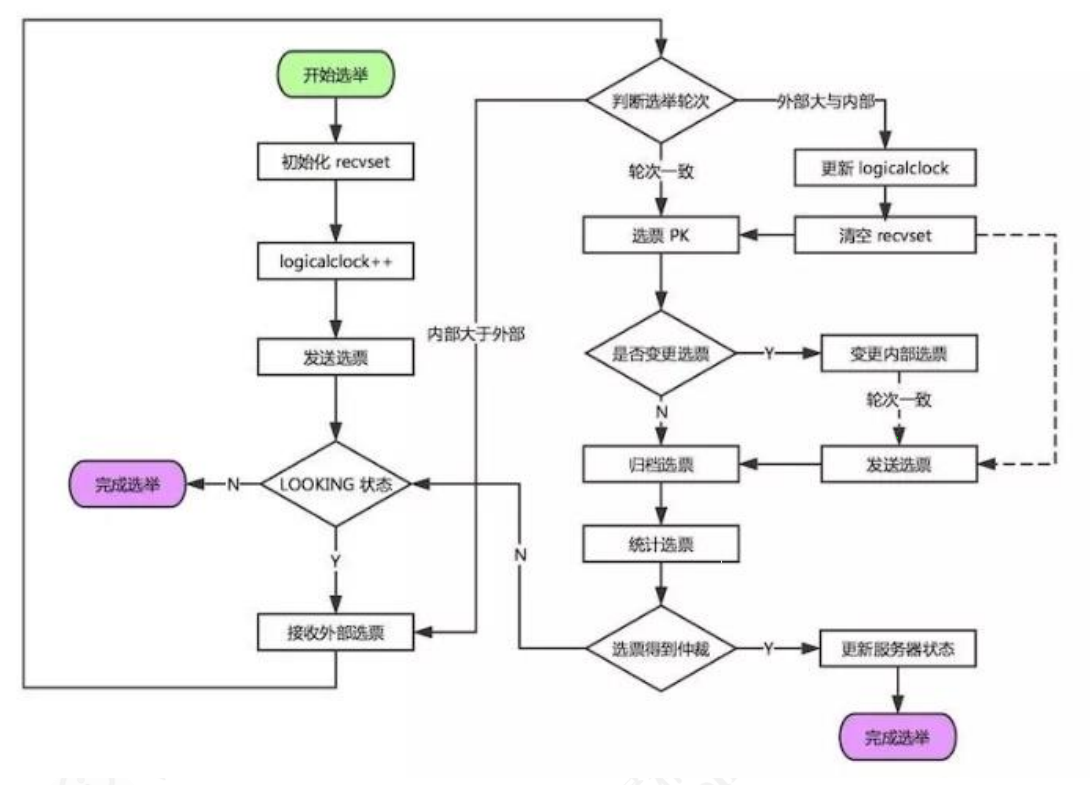
ZK选举投票核心逻辑
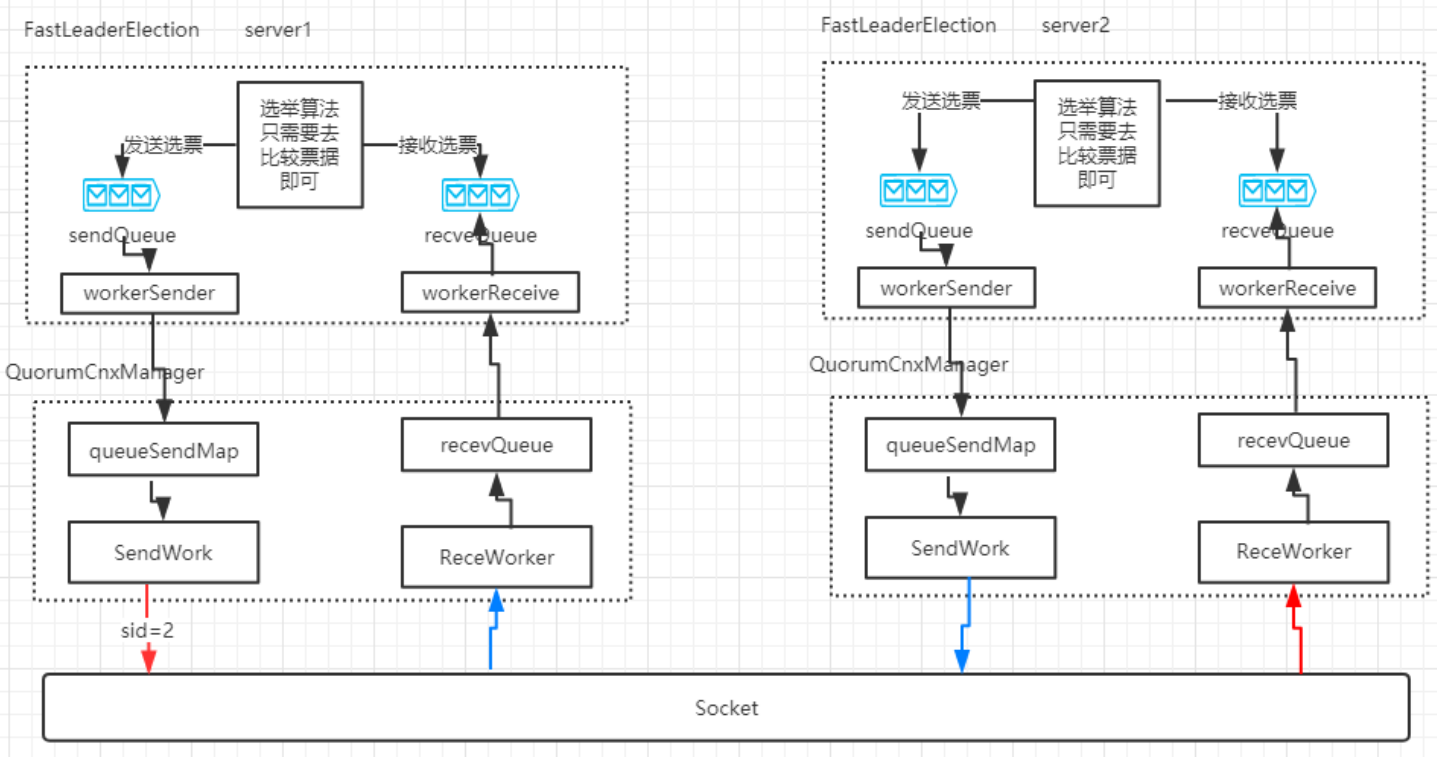
FastLeaderElection通信使用的是ServerSocket, 没有使用NIO/Netty.因为集群通信的节点毕竟有限.
Watch机制
ZooKeeper 的 Watcher 机制,总的来说可以分为三个过程:客户端注册 Watcher、服务器处理 Watcher 和客户端回调 Watcher 客户端注册 watcher 有 3 种方式,getData、exists、getChildren;
getData()和exists()返回节点的内容,getChildren()返回子节点列表
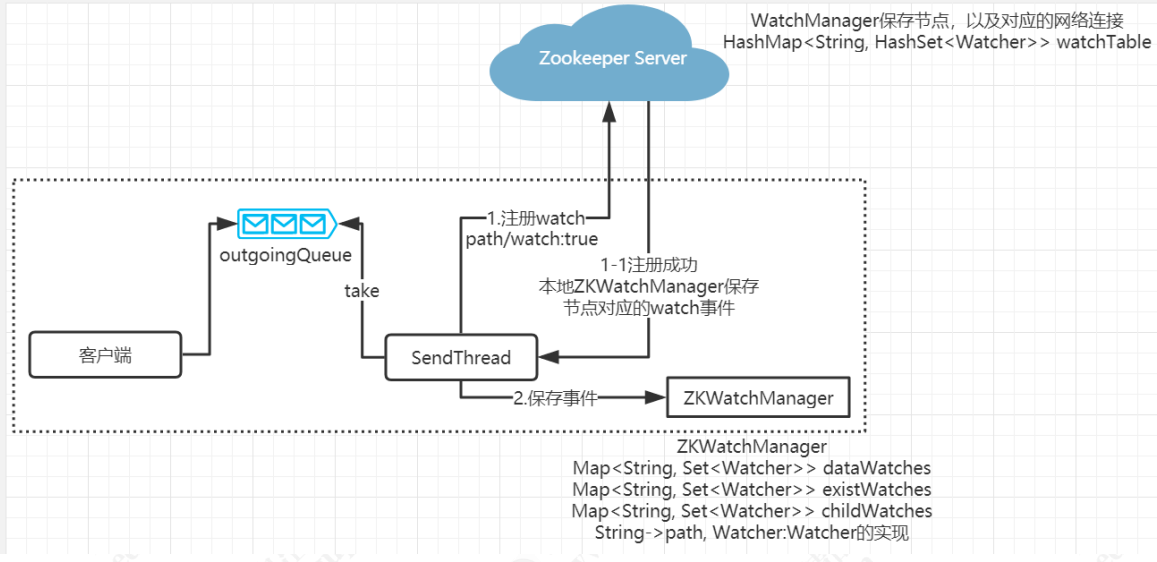
实现原理
ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
ZooKeeper 的 Watcher 机制主要包括客户端线程、客户端 WatchManager 和 ZooKeeper 服务器三部分。在具体工作流程上,简单地讲,客户端在向 ZooKeeper 服务器注册 Watcher 的同时,会将 Watcher 对象存储在客户端的 WatchManager 中。当 ZooKeeper 服务器端触发 Watcher 事件后,会向客户端发送通知,客户端线程从 WatchManager 中取出对应的 Watcher 对象来执行回调逻辑。如清单 9 所示,WatchManager 创建了一个 HashMap,这个 HashMap 被用来存放 Watcher 对象。
注: 以上图片来自于咕泡mic老师课程.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号